Spark Streaming: como processar grande volume de dados


A produção de informações, de diversas fontes, vem crescendo exponencialmente há décadas. Neste fluxo, as empresas têm dedicado, cada vez mais, seus esforços na tentativa de gerar valor para os negócios com estas informações.
No começo, o desafio era conseguir soluções para armazenamento destes grandes volumes de dados. Outro ponto foi o desenvolvimento de soluções para processar os dados de forma rápida. Porém, o maior desafio desse processo estava em como extrair valor dos dados em tempo real.
Neste sentido, a capacidade de processar conjuntos de dados à medida que chegam se tornou uma vantagem competitiva para boa parte das empresas. Para realizar essa tarefa foram sugeridas novas técnicas e ferramentas. Neste artigo iremos conhecer uma delas, mas primeiro falaremos sobre alguns pontos importantes. Vamos lá!?
Tipos de processamento de dados
No contexto Big Data, o processamento de dados em batch (lote) é bastante conhecido desde o surgimento do Hadoop. Devido aos seus recursos e robustez, o modelo de programação MapReduce do Hadoop tornou-se uma das principais estruturas de processamento de dados em batch.
Com o passar do tempo boa parte dos desafios neste campo foram bem solucionados e desde então a comunidade mudou sua atenção para outro desafio, o processamento de dados em streaming.
Algumas pessoas já leram ou ouviram algo relacionado com a palavra streaming, por exemplo, ao comentar sobre plataformas de transmissão de áudio e vídeo como Spotify, Amazon Music, Youtube e Netflix ou aplicações mais específicas como sistemas de monitoramento de bolsas de valores ou aplicativos de coleta de dados enviados por sensores (IoT). Mas, em um cenário de análise de dados, o que seria processamento de dados em streaming?
O processamento de dados em batch executa uma determinada tarefa considerando um conjunto de dados de entrada estático e de tamanho fixo para produzir o resultado final, ou seja, o processamento é interrompido quando chega ao final do conjunto de dados.
Por outro lado, o processamento em stream consiste em executar uma determinada tarefa considerando fluxos de dados ilimitados. Dessa forma, o processamento é contínuo e de longa duração, como se estivéssemos trabalhando com bases de dados infinitas.

Apache Spark
Com o elevado crescimento na geração de dados e a necessidade das empresas em agregar valor para os seus negócios com estas informações, surgiram alguns frameworks com o objetivo de processar grandes volumes de dados de forma distribuída e com alto desempenho. Um destes frameworks que vem sendo bastante utilizado no mercado é o Apache Spark.
O Apache Spark é um framework que dá suporte para mais de uma linguagem de programação. Ele é utilizado para executar engenharia de dados, data science e machine learning em apenas um computador ou em um cluster. É uma ferramenta muito aplicada no contexto Big Data.
O Spark tem um conjunto de componentes para solucionar problemas específicos, todos construídos sobre o Spark Core, que é o componente que disponibiliza as funções básicas para o processamento. Entre estes componentes temos o Spark Streaming, que possibilita o processamento de fluxos de dados em tempo real.
Spark Streaming
O Spark Streaming é uma extensão da API principal do Spark que dá suporte ao processamento de dados em tempo real com tolerância a falhas, alto desempenho e de forma escalável. A Figura abaixo foi extraída do site da Databrick e exemplifica como seria o fluxo de processamento de dados utilizando o Spark Streaming.
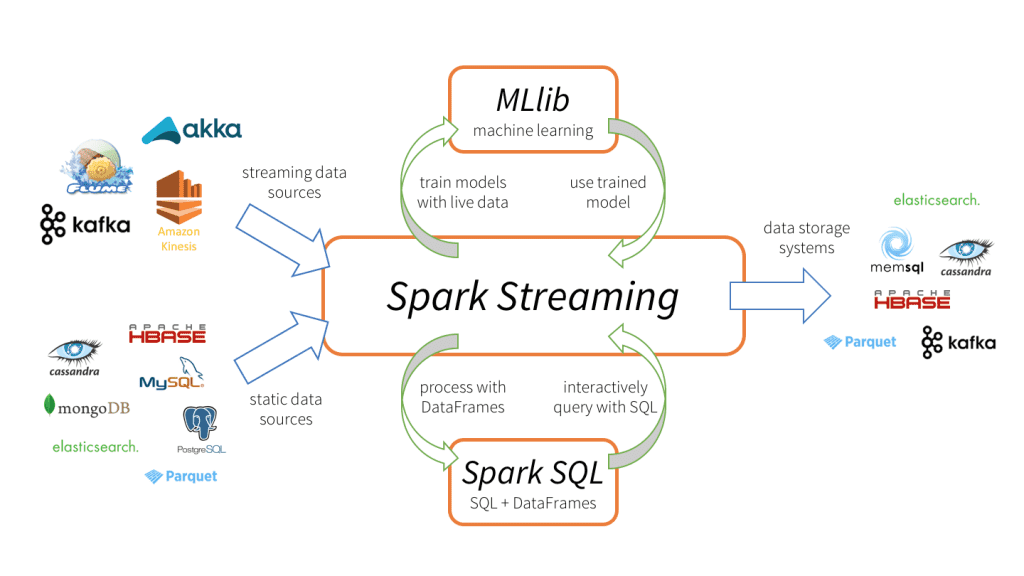
O Spark Streaming oferece suporte para cargas de trabalho em batch e streaming. Essa unificação de recursos de processamento de dados facilita muito o trabalho das pessoas desenvolvedoras, que podem utilizar uma única estrutura para satisfazer todas as suas necessidades de processamento.
Como mostra a figura, os dados em tempo real podem chegar de diversas fontes como Kafka, Flume, Kinesis, Twitter, HDFS ou soquete TCP. Já os dados de fontes estáticas podem vir de fontes como o MongoDB, MySQL, PostgreSQL etc.
Sua abstração principal é conhecida como Discretized Stream ou apenas DStream, que é uma sequência contínua de RDDs (a abstração de dados principal do Spark) e representa um fluxo contínuo de dados separados em lotes pequenos. O uso de RDDs permite que o Spark Streaming se integre perfeitamente a qualquer outro componente do Spark, como o Spark SQL e o MLlib.
Após o processamento, os dados podem ser enviados para sistemas de arquivos, bancos de dados e dashboards.
Caso queira saber mais sobre o Spark Streaming e como utilizar essa ferramenta, sugiro os seguintes conteúdos: