Tá na hora de escrever
o prompt da sua carreira.
Comece sua evolução
Home
Carreiras
Skills & Go
Talent Lab
IA
Artigos
Empresas
Ver planos
Home
Planos
Carreiras
Skills & Go
Talent Lab
IA
Pós Graduações
Artigos
Sobre a Alura
Para Empresas
Grupo Alun
Busca:
Login
Contato
LinkedIn
Instagram
YouTube
Carreiras
Pós-Graduação
Conteúdos
Skills & Go
Para Empresas
Voltar
Trilhas por carreira
Ver Todas
IA
Engenharia de IA
Especialista em IA
Dados
Ciência de Dados
Análise de Dados
Governança de Dados
Engenharia de Dados
Cyber
Cloud Security
AppSec: Desenvolvimento Seguro de Aplicações
DevOps & Cloud
Platform Engineering
SRE (Site Reliability Engineering)
UX & UI
UI Design
UX Design
Mobile & Front-End
Desenvolvimento Mobile com Flutter
Desenvolvimento Front-End React
Back-End
Desenvolvimento Back-End PHP
Desenvolvimento Back-End .NET
Desenvolvimento Back-End Python
Desenvolvimento Back-End Java
Desenvolvimento Back-End Node.js
Negócios
Liderança
Recursos Humanos (RH)
Social Media Marketing
Growth Marketing
Voltar
Voltar
Cursos por área de atuação
Ver Todos
Data
Data Analytics
Machine Learning Engineering
IA
IA Para Devs
IA Para Negócios - Gestão Estratégica e Liderança
Machine Learning Engineering
Cyber
Defensive Cyber Sec
Offensive Cyber Sec
Tech & Business
Digital Product Management
Growth Marketing
Tech Management
Dev
Arquitetura de Sistemas .Net
Arquitetura e Dev JAVA
Front-end Engineering
Full Stack Development
IA Para Devs
Software Architecture
DevOps e Arquitetura Cloud
Voltar
Praticar
Imersões
Eventos ao vivo e gratuitos que conectam comunidade e novas tecnologias
7 Days of Code
Desafios diários para praticar durante 7 dias
Aprofundar
Artigos
Biblioteca com artigos de todas as escolas e assuntos da Alura
Podcasts
Explore o universo de podcasts da Alura
Tech Guide
Um guia de carreira para se tornar um profissional em T
Vídeos Extras
Vídeos extras para aprofundar seus estudos
Nosso Impacto
Depoimentos de Alunos
Veja como nossos alunos evoluíram na prática e alcançaram novas oportunidades
Cases de Sucesso
Exclusivo para estudantes Alura
Aprenda a partir de casos reais de líderes de grandes empresas de tecnologia
Artigos
Back-end
Artigos de
Back-end
Desenvolvimento de software e tecnologia em artigos, toda semana! Conteúdo de Dev em <T>.
Buscar
Últimos artigos publicados
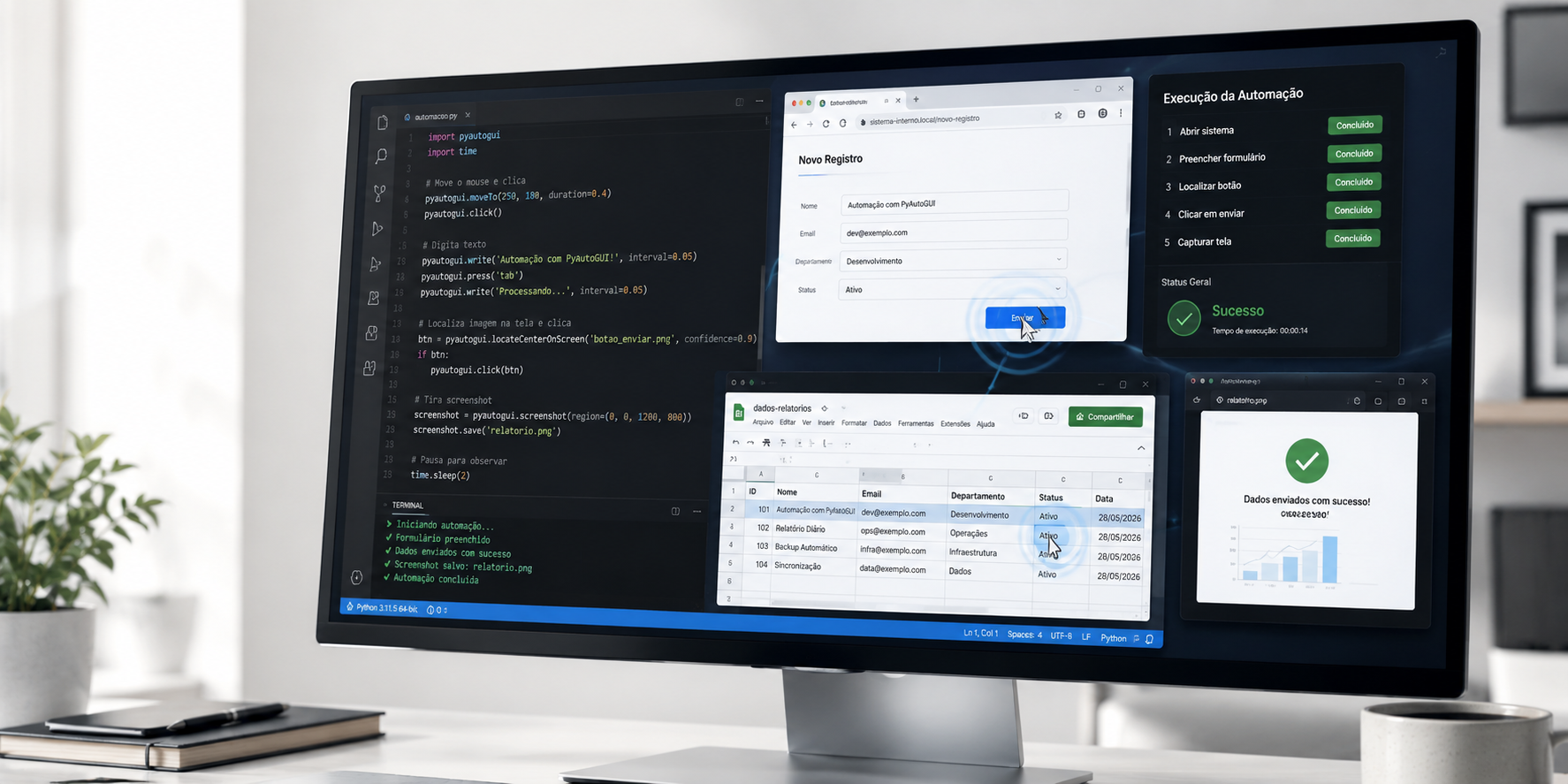
PyAutoGUI: o que é, como instalar, como usar e principais funcionalidades
10 de Junho
Back-end
Gerenciamento de Estado em React: por que e como usar o Zustand
3 de Junho
Back-end
1 Bi devs: o perfil builder
22 de Maio
Back-end
TypeScript: quando usar unknown em vez de any?
12 de Maio
Back-end
Estilização em React: do CSS tradicional ao Tailwind CSS
28 de Abril
Back-end
NestJS: o que é, como usar, para que serve, como instalar
23 de Abril
Back-end
Citizen developer: o que é, benefícios e como começar
21 de Abril
Back-end
Dev sênior: habilidades e características importantes
15 de Abril
Back-end
Como escolher uma linguagem de programação para back-end
14 de Abril
Back-end
Como evitar “callback hell” com async/await
18 de Fevereiro
Back-end
Rust: o que é, características e como instalar
4 de Fevereiro
Back-end
Guia completo de como construir sua carreira na área de TI em 2026
29 de Janeiro
Back-end
List comprehension Python: como simplificar seu código
28 de Janeiro
Back-end
Carreira de desenvolvedor júnior: como está o mercado de trabalho em 2026?
15 de Janeiro
Back-end
Platform Engineering: o que é, quais os benefícios e melhores práticas
14 de Janeiro
Back-end
Primeira
1
2
3
4
5
Última
 Back-end
Back-end
 Back-end
Back-end
 Back-end
Back-end Back-end
Back-end
 Back-end
Back-end
 Back-end
Back-end
 Back-end
Back-end
 Back-end
Back-end Back-end
Back-end Back-end
Back-end Back-end
Back-end Back-end
Back-end Back-end
Back-end


