Quando começamos a estudar sobre machine learning, diversos termos em inglês aparecem de uma só vez. Quanto mais nos aprofundamos nos assuntos específicos, mais palavras aparecem. Se quiser saber mais sobre alguns dos termos dessa área, recomendo a leitura do artigo Desmistificando termos em Machine Learning.
O Processamento de Linguagem Natural (PLN), mais conhecido pelo termo em inglês Natural Language Processing (NLP), é uma das áreas de machine learning que vem crescendo todos os dias. Ela está inserida no nosso cotidiano nas pesquisas que fazemos no Google, por exemplo, e faz a ponte entre a comunicação humana e a das máquinas.
Autor(a)
Sthefanie Monica Premebida
Engenheira Eletricista, pesquisadora na área de Redes Neurais e Machine Learning, instrutora de Data Science, apaixonada por esportes radicais, viajar e fazer qualquer trilha que apareça, cheerleader nas horas vagas e uma jogadora de RPG de mesa.
Inscreva-se em nossa Newsletter
Fique por dentro de conteúdos, insights e oportunidades do universo tech. Receba novidades e lançamentos direto no seu e-mail.
Para fazer essa ponte, existem diversas técnicas aplicadas à nossa linguagem humana para que ela seja compreendida pelas máquinas. Termos como: corpus, fazer tokenização e normalização, aplicar técnicas para retirar ruídos, aplicar stemming e lemmatization… Nossa! É muita informação! Mas, vamos por partes.
Primeiro, vamos conhecer os conceitos básicos de NLP e depois passaremos para as técnicas, já que muitos desses termos são interligados. No final, você vai estar craque em termos de NLP.
Conceitos
Corpus
Palavra do latim que significa corpo. Refere-se ao corpo de um texto, que pode ser escrito ou falado, contendo um ou mais idiomas. Para representar uma coleção de textos, temos a palavra corpora, plural de corpus. Esta coleção de textos pode ter um tema específico ou temas gerais. Alguns exemplos de textos usados em NLP são: resenhas de filmes, comentários da internet, reviews de cursos, críticas à aplicativos online, e-mails, entre outros.
Tokenization
Tokenização é o processo de dividir uma frase em palavras ou tokens individuais. Durante esse processo, pontuações e caracteres especiais são completamente removidos. É importante ressaltar que os tokens não são necessariamente apenas uma palavra.
Quando temos palavras compostas, elas podem ter significados totalmente diferentes, como: “beija-flor” e “segunda-feira”. De uma forma geral, tokenização é o ato de simplificar o corpus e prepará-lo para os outros estágios de processamento.
Normalization
A normalização dos textos é feita para que o processo de análise seja mais preciso e tem a característica de manter um padrão com todas as letras maiúsculas ou minúsculas. Geralmente, a normalização é feita depois do processo de tokenização, onde podemos encontrar frases que são semelhantes e fazer a combinação entre elas, caso queiramos, independente das diferenças.
Um exemplo disso é quando encontramos as palavras “Terra” e “terra” que têm significados diferentes, já que uma se refere ao planeta e a outra ao chão/solo. Na normalização podemos combinar esses termos e utilizar apenas “terra”. Existem diversos prós e contras em todas as fases. Ao mesmo tempo que é possível ter uma melhor correspondência na hora da pesquisa, a confiabilidade geral da aplicação pode ter uma interferência por conta dessa mudança de letras maiúsculas e minúsculas.
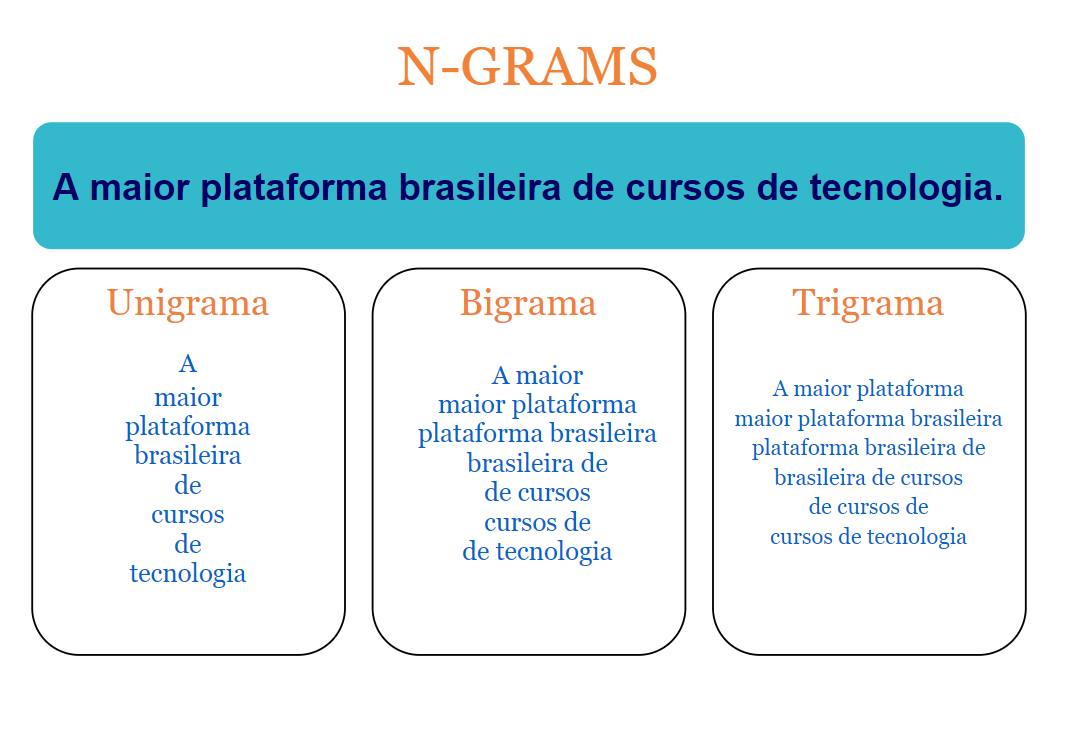
n-grams
n-gram é um tipo de modelo probabilístico usado para prever o próximo item de uma sequência na forma de um modelo de Markov. Em um contexto linguístico, o n-grams refere-se a uma sequência n de palavras. Como podemos perceber nos exemplos a seguir: “Estudando” tem um 1-gram (unigrama); na sequência “Estudando NLP” temos um 2-gram (bigrama); e em “Estudando Machine Learning” temos um 3-gram (trigrama).
Lexicons
Quando estamos fazendo alguma tarefa que envolva NLP, às vezes precisamos considerar mais do que apenas a linguagem. Nesse caso, entram os lexicons. Na Linguística e em NLP, eles são uma parte da gramática que lida com o significado de uma palavra. Quando ela é usada em situações diferentes e ao realizar, por exemplo, uma análise de sentimento em tweets, a forma coloquial de descrever situações ou coisas interfere nos resultados finais e não podemos ignorar esses fatores.
Pré processamento e limpeza dos dados
Antes de qualquer outra etapa, é necessário fazer o pré-processamento do texto que será usado. Nesta etapa, o objetivo é limpar o texto, removendo os ruídos (pontos, caracteres especiais, etc), palavras repetidas e aquelas com pouco valor para a base de dados. Esse processo é feito utilizando principalmente as técnicas de stop words, lemmatization e stemming.
Técnicas
Stop Words
É a técnica que faz a remoção de ruídos do texto que são menos evidentes que pontuações, como os conectivos “que”, “o”, “a”, “de”, entre outros. Quase todos os textos em português contém conectivos e palavras comuns que não são significativas para o nosso modelo, então podemos retirá-las.
Uma das bibliotecas usadas para NLP, a NLTK (National Language Toolkit), fornece auxílio para remoção das stop words passando como parâmetro o idioma do corpus que está sendo trabalhado e identificando se é uma palavra de alta frequência e baixa relevância.
Stemming e Lemmatization
Stemming e lemmatization servem para reduzir as palavras à sua forma raiz de uma forma que o ruído do texto seja diminuído cada vez mais. É uma técnica interessante dependendo do objetivo do uso da NLP. Um exemplo claro são as palavras “ventania”, “ventoinha” e “ventilador”, pois todas podem ser convertidas a “vento”. Para saber mais sobre essas técnicas, temos o artigo Lemmatization vs. stemming: quando usar cada uma?.
Bag of words
É uma das técnicas mais utilizadas para fazer a feature extraction, ou seja, fazer com que as informações sejam organizadas de uma forma estruturada. Porém, os textos não são dados estruturados - não organizados de uma maneira fixa, como uma tabela - e, por isso, transformamos os textos em uma informação numérica.
A técnica de bag of words nos permite representar o texto com a ocorrência de cada palavra, sem levar em conta a ordem das palavras ou a sua estrutura no texto. É realmente como se todas as palavras fossem colocadas dentro de um saco.
TF-IDF
TF-IDF significa Term Frequency - Inverse Document Frequency ou Frequência do Termo - Inverso da Frequência no Documento, em tradução livre para o português. Trata-se de medidas estatísticas que demonstram o quão importante uma palavra é em um texto, assemelhando-se muito com a técnica de bag of words, mas com algumas diferenças.
Term Frequency mede a frequência com que um termo aparece em um documento. Já o Inverse Document Frequency mede o quão importante um termo é em relação a todo o corpus. Essas duas métricas são usadas e levadas em conta para definir a importância da palavra. Basicamente, quanto mais frequente a palavra é, mais importante ela tende a ser no texto.
Word Embeddings
Traduzindo para o português podemos chamar de incorporação de palavras. Representa cada token incorporado como um vetor com valores numéricos antes de ser passado para o modelo de aprendizado de máquina, uma vez que elas não compreendem palavras, apenas números. Esse método reconstrói o contexto linguístico das palavras, focando na semelhança radical e na relação de sentido dos termos, para depois a palavra ser representada por um valor e ser inserida em um vetor.
Vale lembrar que os valores mudam conforme as características da palavra, para que exista um padrão, como conseguir separar palavras no masculino e no feminino. Apesar dos embeddings serem comumente chamados de palavras, eles podem ser feitos à nível de caracteres ou frases. Diversas técnicas podem ser usadas para incorporação, uma delas é a Word2Vec.
Word2Vec é um algoritmo do Google para fazer a Word Embeddings e nada mais é do que uma técnica estatística que aprendeu a incorporação de palavras com eficiência a partir de um corpus, para tornar o treinamento da rede neural eficiente.
Quando falamos de NLP, sabemos que a leitura, limpeza e análise de diversos textos são necessários. Às vezes, usando apenas técnicas computacionais, perdemos informações que podem ser relevantes para análises futuras. Nesse caso, entra o reconhecimento de entidade nomeada que extrai informações sobre um texto já fazendo um rótulo sobre a sua categoria pré-definida, como pessoas, lugares, horas, entre outras. Utilizando o Named Entity Recognition (NER), as análises feitas no texto tornam-se mais precisas.
Parts-of-speech (POS) Tagging
Essa técnica que, traduzida para o português, pode significar algo como etiquetar partes da fala, serve para analisar e identificar as diferentes classes gramaticais em um texto. A marcação de POS resulta em várias tuplas, onde cada uma delas contém a palavra e a sua tag que classifica gramaticalmente a palavra como verbo, adjetivo, substantivo, etc.
Então, se fizéssemos o POS tagging da frase “A maior plataforma brasileira de cursos de tecnologia”, teríamos um resultado como:
[A, [maior, adjetivo], [plataforma, substantivo], [brasileira, adjetivo], de, [cursos, substantivo], de, [tecnologia, substantivo]]
Note que apenas as palavras principais da frase tem uma tag, já que, no processo de stop words, o artigo “A” e as duas preposições “de” que estão na frase são removidos.
Esses conceitos e técnicas apresentados podem ser estudados mais a fundo nos cursos da Alura. Neles, os projetos são desenvolvidos junto com as pessoas instrutoras e você aprende na prática. Caso queira saber mais sobre onde pode aplicar NLP, sugiro a leitura do artigo Aplicações de NLP no mercado de trabalho.