Introdução
No dia a dia do mercado de trabalho em dados, é comum nos depararmos com termos estrangeiros e técnicos complexos de data science e machine learning, podendo nem sempre ser compreendido por quem está na área ou em transição para ela.
Pensando nisso trouxemos uma seleção de termos, que frequentemente aparecem em inglês, com suas traduções e significados, associando com seu uso na prática.

Feature Engineering (Engenharia de Atributos)
Antes de alcançarmos grandes respostas e bons modelos, há todo um processo de entendimento e identificação de tarefas de pré-processamento necessárias a se aplicar no conjunto de dados.
Uma dessas tarefas é a feature engineering, em que consiste no processo de transformação dos dados brutos em features (atributos) que possam gerar valor e aumentar o potencial do modelo a fim de responder a um problema de negócio.
Por exemplo, em um conjunto de dados sobre preços de casas, você possui as variáveis largura e comprimento do terreno. Não seria mais interessante termos a área a partir dessas outras duas variáveis?
Sim! Se estamos pensando em comprar uma casa, saber sua área é muito mais interessante do que apenas sua largura ou comprimento, ainda mais em relação ao seu valor.
Backpropagation (Retropropagação)
Com o avanço das redes neurais, ou seja, modelos preditivos cada vez mais complexos baseados na dinâmica do cérebro humano, foi necessário criar algoritmos que treinassem redes com múltiplas camadas intermediárias de neurônios interconectados para o processamento das informações. Um desses algoritmos desenvolvidos foi o backpropagation, ou em português retropropagação, que funciona em duas etapas: para frente (forward) e para trás (backward).
Em outras palavras, ele utiliza o cálculo de gradiente descendente de forma automatizada, fazendo com que o algoritmo caminhe para frente e para trás pelas camadas intermediárias, buscando diminuir a taxa de erro até convergir a melhor solução, ou seja, a melhor acurácia.
Entropy (Entropia)
Um dos modelos utilizados no aprendizado de máquina supervisionado, são as árvores de decisão. Estas são estruturas baseadas na divisão do conjunto de dados em diferentes caminhos e seus respectivos resultados.
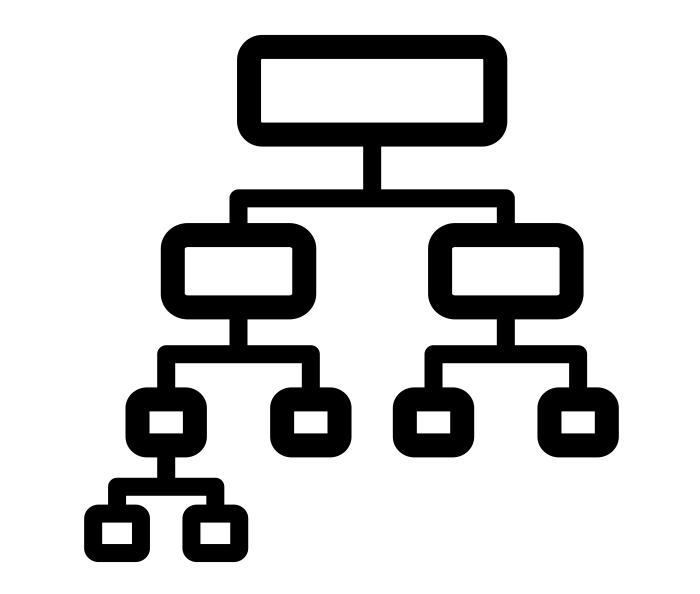
A entropia é a medida que calcula o nível de confiança dos dados, ou seja, o quão incerta é a classe a qual os dados fazem parte e quanto ganharemos de informação com isso. Esta é uma medida importante para vermos qual o melhor caminho que traga os melhores resultados (boa acurácia) para o nosso problema.
Parameters e Hyperparameters (Parâmetros e Hiperparâmetros)
Quando desenvolvemos um modelo, há dois conceitos importantes para ficarmos atentos e saber qual a diferença entre eles:
Parameters (Parâmetros): são as variáveis ajustadas diretamente durante o processo de aprendizado da máquina, ou seja, quando estão sendo treinados os modelos, há uma escolha do melhor parâmetro para aquele método. Por exemplo: em um modelo de regressão linear, os parâmetros são seus coeficientes.
Hyperparameters (Hiperparâmetros): são as variáveis definidas, com intuito de otimizar o máximo possível dos parâmetros. Por exemplo, podemos citar um algoritmo disponível na biblioteca scikit-learn, o GridSearchCV, que por meio da validação cruzada na busca em grade, otimiza os parâmetros.
Overfitting e Underfitting (Sobreajuste e Sub-ajuste)
Quando estamos na etapa de modelagem do projeto de data science, devemos ficar atentos a dois problemas comuns de ocorrerem:
Overfitting (sobreajuste): um ajuste perfeito aos dados no treinamento, resultando em altos valores de acurácia, porém quando damos entrada a valores novos, o modelo não consegue prever de forma eficaz. O modelo não generaliza bem com novos conjuntos de dados. Uma das formas de evitar este problema, é a divisão do conjunto de dados em treino e teste, sendo estes dados diferentes.
Underfitting (sub-ajuste): um baixo ajuste do modelo aos dados, não conseguindo prever praticamente nada correto, acurácia muito baixa. Sugestão é que procure outro modelo mais viável aos dados que esteja trabalhando.
Bias-Variance Dilemma (Dilema viés-variância)
Os modelos de machine learning procuram obter as previsões mais próximas da realidade. Dois pontos importantes que afetam diretamente a acurácia são: a variância, o quão distante da média estão os dados e o viés, a capacidade de identificar as diferenças entre as previsões médias e os valores corretos a serem previstos. O dilema viés-variância busca trazer a atenção para os níveis de variância e o viés nos dados, ou seja, a tendência é termos uma alta variância e um baixo viés (ocasionando um overfitting no modelo) ou uma baixa variância e um alto viés (levando a um underfitting no modelo), então devemos focar em equilibrar essa taxa. Por exemplo, uma das formas de equilíbrio é por reamostragem.
Cross-Validation (Validação Cruzada)
Uma importante etapa de um projeto de data science é a validação do modelo, para termos uma certeza se os resultados são confiáveis e não há presença de overfitting ou underfitting. Uma das técnicas utilizadas é a validação cruzada, que consiste em separar o conjunto de dados em subconjuntos mutuamente exclusivos, sendo um deles para treino e os outros para teste e validação do desempenho do modelo. Esta técnica permite avaliar a capacidade de generalização de modelos de machine learning. Uma das formas de aplicar essa técnica é pelo k-fold, ou seja, separar de forma aleatória em k subconjuntos de mesmo tamanho.
Para conhecer outros termos, se aprofundar e saber mais, confira nossos cursos e artigos destacados abaixo!
Referências