Um dos desafios do processamento de linguagem natural é como representar e simplificar todo conteúdo contido em um texto e realmente extrair o máximo de informação para o seu objetivo. Este pode ser: resumir documentos, criar um motor de buscas, fazer análise de sentimento e agrupar documentos.
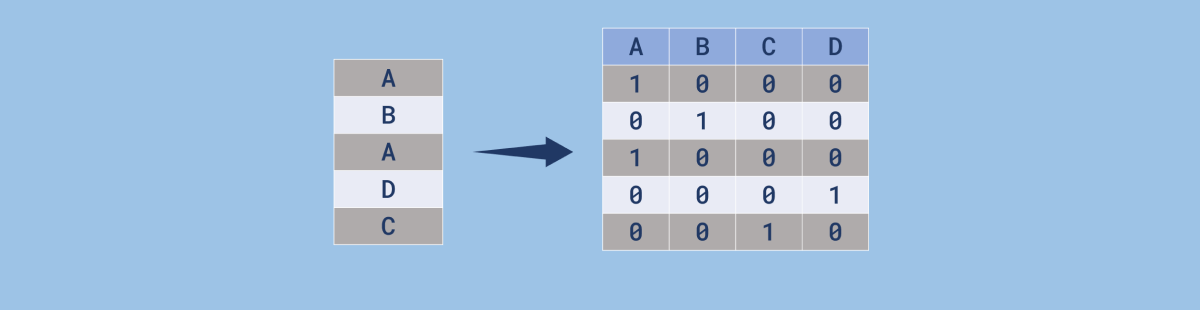
Existem diversas técnicas que são aplicadas em nossos textos antes de se criar um modelo. Por exemplo, a bag of words representa as palavras por um vetor, sinalizando quais delas estão naquele texto ou não. Sem o devido tratamento, vamos terminar com um vetor gigantesco que pode conter muitas informações repetidas e desnecessárias. Para resolver isso, precisamos de um tratamento que remova as stop words e um pré-processamento onde vamos conseguir reduzir palavras focando em seu significado, uma técnica chamada de stemming (stemização, no português).
Na stemming vamos analisar cada palavra individualmente e reduzi-la à sua raiz ou, como é chamado na técnica, ao seu stem. Uma característica dessa técnica é que ela pode reduzir a palavra a uma outra gramaticalmente incorreta, porém ainda com valor para nossa análise. Os algoritmos de stemming têm um conjunto de regras para decidir como fazer os cortes. Utilizando a biblioteca NLTK podemos demonstrar seu uso.

Vamos criar um dataframe no pandas com exemplos de palavras.
import pandas as pd
df_palavras = pd.DataFrame(['amigos', 'amigas', 'amizade', 'carreira', 'carreiras'], columns=['Original'])
df_palavras
| Original | |
|---|---|
| 0 | amigos |
| 1 | amigas |
| 2 | amizade |
| 3 | carreira |
| 4 | carreiras |
Agora que temos os dados, podemos importar a biblioteca NLTK e depois fazer o download do algoritmo que vamos utilizar: o RSLP Stemmer.
import nltk
nltk.download('rslp')
Depois podemos criar o objeto que vai ser usado para fazer a transformação dos nossos dados: o stemmer.
stemmer = nltk.stem.RSLPStemmer()
E, finalmente, vamos pedir para o stemmer fazer as transformações. Combinamos o list comprehension e o método stem para passar por cada palavra e fazer a transformação.
df_palavras['nltk_stemmer'] = [stemmer.stem(palavra) for palavra in df_palavras['Original']]
df_palavras
| Original | nltk_stemmer | |
|---|---|---|
| 0 | amigos | amig |
| 1 | amigas | amig |
| 2 | amizade | amizad |
| 3 | carreira | carr |
| 4 | carreiras | carr |
Conseguimos, rapidamente, extrair raízes ou stem. Como previmos, não é garantido que as palavras existam, o que pode ser um problema dependendo do que estamos resolvendo. Pensando nisso, devemos buscar uma técnica diferente, a lemmatization (lematização, no português).
Na lemmatization também vamos buscar reduzir a palavra à sua raiz, retirando todas as inflexões e chegando ao lemma. Porém, essa redução sempre resultará em uma palavra que realmente existe na gramática. Outro ponto importante é que, nessa técnica, a classe gramatical da palavra será levada em consideração para fazer a redução. Vamos agora utilizar a biblioteca spaCy para aplicar essa técnica.
Primeiro, instalamos a parte de português do spaCy.
!python -m spacy download pt
Depois, fazemos a importação e criamos o nosso objeto para a manipulação do texto: o nlp. Um ponto de atenção é que devemos mandar o parâmetro pt para identificar o idioma que vamos trabalhar.
import spacy
nlp = spacy.load('pt')
Agora podemos novamente utilizar o list comprehension para passar por cada uma das palavras. Dessa vez vamos criar uma grande string, como uma frase, para ser analisada pelo nosso NLP.
doc = nlp(str([palavra for palavra in df_palavras['Original']]))
Em seguida, vamos iterar por essa frase, analisando se a palavra ou token é um substantivo (NOUN) ou não. Caso seja, pedimos para o spaCy extrair o lemma desta palavra.
df_palavras['spacy_lemma'] = [token.lemma_ for token in doc if token.pos_ == 'NOUN']
df_palavras
| Original | nltk_stemmer | spacy_lemma | |
|---|---|---|---|
| 0 | amigos | amig | amigo |
| 1 | amigas | amig | amigo |
| 2 | amizade | amizad | amizade |
| 3 | carreira | carr | carreira |
| 4 | carreiras | carr | carreira |
Dependendo do quão elaborado seja o algoritmo da lemmatization, ele pode gerar associação entre sinônimos tornando essa técnica muito mais rica nos resultados, como relacionar a palavra trânsito e a palavra engarrafamento. Este mesmo resultado não aconteceria na técnica stemming que apenas reduziria essas palavras. Assim, essa técnica não é a ideal em idiomas morfologicamente mais complexos.
Stemming ainda pode gerar dois tipos de problemas como: cortar demais e acabar com um stem que não tem sentido e perdeu muito de sua informação; ou também cortar demais e ter dois stem iguais para palavras com significados muito diferentes. A lemmatization é mais lenta, mas garante que vai gerar palavras gramaticalmente corretas e com maior precisão já que leva a classe gramatical em consideração.
Com essas informações sobre essas duas técnicas podemos determinar onde elas serão melhor aplicadas. Stemming é mais comumente usada por mecanismos de busca para indexar palavras. Já a lemmatization tem seu uso interessante junto a técnica como vetorização de palavras (word vectors), Tf-idf e LDA para modelagem de tópicos onde, eliminando plurais e utilizando sinônimos, podemos ter um aumento de precisão nessas técnicas.
Aqui está o link para o Notebook do projeto e também temos o curso Word2Vec que é um ótimo próximo passo para explorar mais técnicas do mundo NLP.