


Executores do Airflow: tipos e funções


Para que os processos presentes nos fluxos de trabalho, como um ETL ou ELT, sejam gerenciados pelo Airflow, como podemos garantir que as tarefas serão executadas da melhor forma possível?
Antes de respondermos essa questão, vamos voltar um pouco no tempo. O Airflow surgiu em 2014, na Airbnb, com Maxime Beauchemin e a ideia de suprir a necessidade de gerenciar fluxos de trabalho (workflows) cada vez mais complexos. Você pode imaginar essa ferramenta como um maestro responsável por orquestrar vários músicos e suas execuções.
Para que seja possível lidar com todas as tarefas envolvidas em um fluxo de trabalho complexo, o Airflow utiliza de um mecanismo chamado Executor. Mas o que esse mecanismo faz exatamente? É isso que vamos descobrir agora!
Tasks e DAGs
Para entendermos a função do Executor dentro do Airflow, temos que conhecer dois conceitos essenciais antes: as tasks e os DAGs.
As tasks - em português, tarefas - constituem o elemento básico de execução do Airflow, pois é por meio delas que todo o processo de dados ocorre. Elas são organizadas de forma que cada tarefa tenha duas dependências. Uma tarefa possui outras tarefas que precisam ser executadas antes, ou seja, as upstream dela. Essa mesma tarefa também possui outras tarefas que só serão executadas depois dela, as que são downstream dela.
Quem gerencia as dependências, as ordens e as relações que dizem como as tarefas serão executadas é o DAG - Directed Acyclic Graph, em tradução livre, Grafo Acíclico Direcionado. Abaixo, podemos ver um exemplo básico de um DAG:
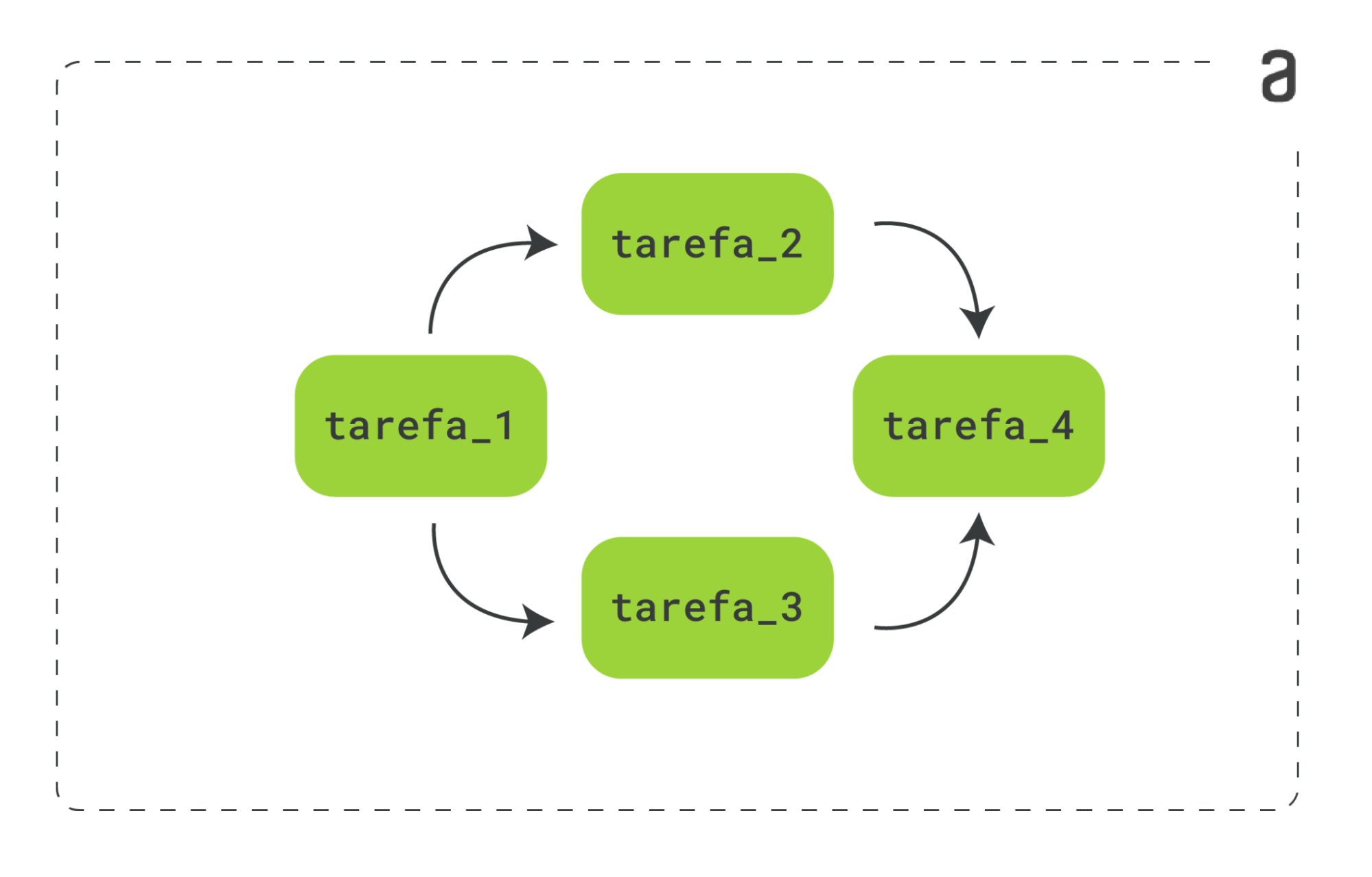 Temos quatro tarefas - tarefa_1, tarefa_2, tarefa_3 e tarefa_4 - em que podemos ver qual tarefa depende de qual e em que ordem elas devem ser executadas, representada pelas setas direcionadas. Nesse caso, a tarefa_1 seria a tarefa inicial, seguida pela tarefa_2 e tarefa_3, executadas paralelamente, que dependem da tarefa_1 para serem executadas e, por fim, a tarefa tarefa_4, dependente das tarefas anteriores, tarefa_2 e tarefa_3.
Temos quatro tarefas - tarefa_1, tarefa_2, tarefa_3 e tarefa_4 - em que podemos ver qual tarefa depende de qual e em que ordem elas devem ser executadas, representada pelas setas direcionadas. Nesse caso, a tarefa_1 seria a tarefa inicial, seguida pela tarefa_2 e tarefa_3, executadas paralelamente, que dependem da tarefa_1 para serem executadas e, por fim, a tarefa tarefa_4, dependente das tarefas anteriores, tarefa_2 e tarefa_3.
Além disso, o DAG nos diz a frequência em que essas tarefas devem ocorrer, se serão a cada 1 hora, a partir de hoje, ou a cada 10 minutos, a partir de amanhã.
Quer aprender ainda mais sobre DAGs? O artigo Airflow - Entendendo os DAGs aprofunda os conhecimentos sobre as DAGs e outros conceitos essenciais do Airflow.

Scheduler
Tendo o entendimento dos conceitos de tasks e DAGs, chegamos em outro elemento essencial do Airflow, o Scheduler - em português, agendador - responsável por monitorar todas as tasks e DAGs, garantindo que as tarefas ocorram no momento certo.
Ele atua de forma contínua, lendo o banco de dados, verificando quais tarefas precisam ser feitas e em qual ordem e, a cada minuto, coleta os resultados do DAG e verifica se há alguma tarefa ativa a ser executada.
Para ajudar nesse processo de execução das tarefas, o Scheduler conta com a colaboração do Executor, responsável por verificar todos os recursos necessários para a realização das tarefas. Nesse artigo, nosso objetivo é justamente entender mais sobre esse mecanismo.
Executores
Os Executores são o mecanismo responsável pela execução das tarefas, e apenas um executor pode ser configurado por vez. Eles podem ser executados de dois modos, localmente ou remotamente, e executam tarefas sequencialmente ou paralelamente.
A principal diferença entre os executores diz respeito aos recursos que possuem e à maneira de realizar a execução das tasks.
Abaixo podemos ver um diagrama do processo de execução das tarefas, contendo todos os elementos abordados até aqui:
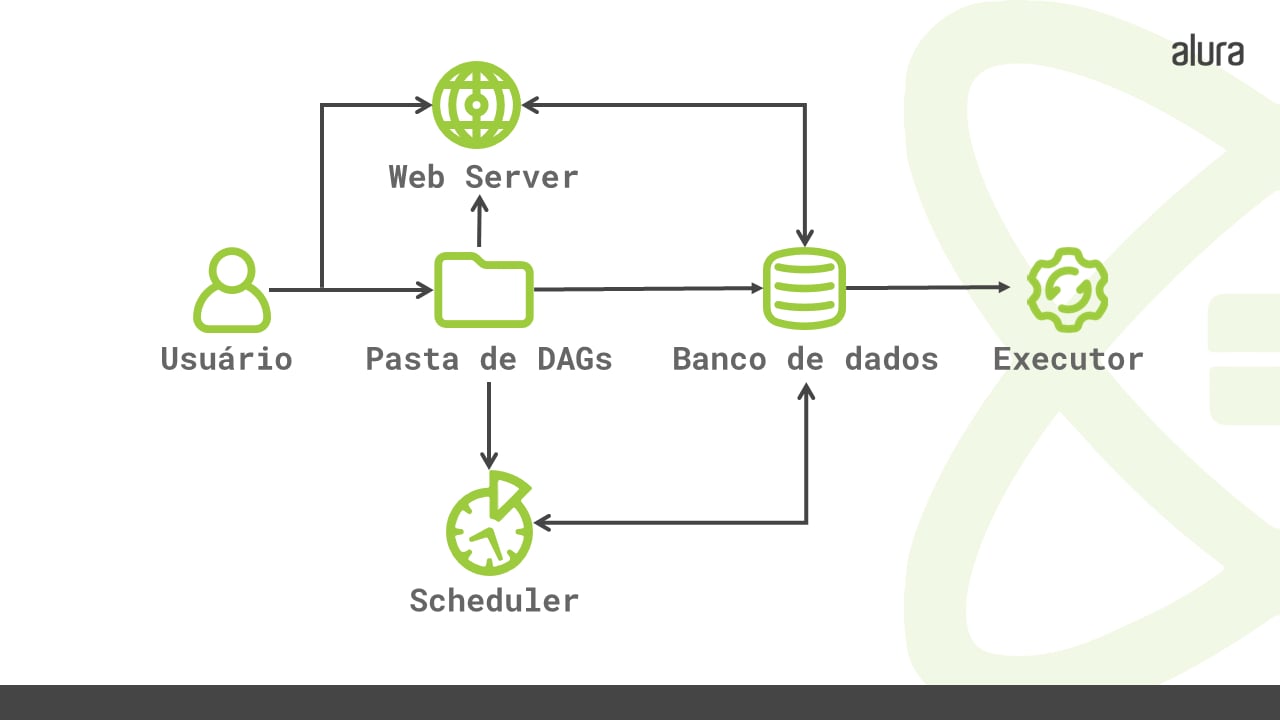 O Airflow possui dois tipos de executores, os Executores Locais e os Executores Remotos, os quais iremos abordar a seguir.
O Airflow possui dois tipos de executores, os Executores Locais e os Executores Remotos, os quais iremos abordar a seguir.
Executores Locais
Os executores locais têm como característica a execução de tarefas apenas na máquina da pessoa usuária, ou seja, localmente. A seguir, veremos dois dos executores locais - o Sequencial Executor e o Local Executor.
Sequencial Executor
É o executor disponível por padrão no Airflow, caracterizado por ser leve, executar apenas uma tarefa por vez e ser utilizado apenas para testes, não para produção, tendo como desvantagem a ocorrência de falhas em ponto único, pois é utilizada apenas uma máquina, e se ela tiver algum problema, as tarefas executadas também terão.
Como ele realiza apenas uma tarefa por vez, o SQLite pode ser utilizado como opção de banco de dados, pois não permite mais de uma conexão.
Local Executor
O Local Executor, ao contrário do sequencial, conseguem realizar várias tarefas ao mesmo tempo. Por esse motivo, não é possível utilizar o SQLite. Como alternativa, utiliza-se o MySQL ou Postgresql como opção de banco de dados, tendo em vista que aceitam várias conexões, o que favorece o paralelismo na execução das tarefas.
Assim como o Sequencial Executor, ele também possui como desvantagem ter um único ponto de falha, pois executa tarefas em paralelo que são executadas em uma única máquina.
Executores Remotos
Ao contrário dos executores locais, os executores remotos possuem a capacidade de executar tarefas utilizando várias máquinas. Por não depender de apenas uma máquina, executores remotos são opções melhores e mais seguras para se trabalhar em produção, pois se uma falha ocorrer, não dependemos de apenas um local de execução. A seguir, veremos dois exemplos de executores remotos, o Celery Executor e o Kubernetes Executor.
Celery Executor
É uma fila de tarefas, que realiza a distribuição dessas tarefas entre vários workers - em português, trabalhadores. Os workers funcionam como máquinas individuais responsáveis pelas tarefas e, dessa forma, evitam o problema de ponto único de falha que ocorre com os executores que rodam localmente, pois se uma máquina falhar, as tarefas serão passadas para outras, dando continuidade ao fluxo de execução.
Assim como o Local Executor, o Celery utiliza o MySQL ou Postgresql como sistema de banco de dados.
Kubernetes Executor
O executor do Kubernetes executa cada tarefa em seu próprio espaço de um cluster do Kubernetes, um conjunto de máquinas físicas ou virtuais, também conhecido como Pod. Esse executor funciona como um processo no Scheduler e precisa de acesso a um cluster do Kubernetes.
Quando o DAG envia uma tarefa, o executor solicita um worker Pod, ou seja, um espaço dentro do cluster do Kubernetes contendo um worker, que por sua vez executa a tarefa, retorna o resultado e finaliza o processo.
Como nos demais casos, o executor do Kubernetes precisa de um sistema de banco de dados diferente do SQLite, por necessitar de várias conexões. Além disso, esse executor possui como vantagem a economia de recursos, pois os seus Pods são utilizados apenas quando as tarefas precisam ser executadas, ao contrário dos outros executores, que funcionam o tempo todo.
Se você se interessou pelo executor do Kubernetes, confira o artigo Kubernetes: conhecendo a orquestração de containers, onde você irá aprender sobre orquestração de contêineres utilizando o Kubernetes.
Conclusão
Com base no que foi apresentado, foi possível conhecer alguns dos componentes presentes no Airflow e o papel dos Executores na execução das tarefas, verificando os recursos necessários para cada uma delas, garantindo que o fluxo de trabalho possa funcionar corretamente.
O Airflow tem como função cuidar do pipeline de dados, ajudando a pessoa Engenheira de Dados a ter mais controle do fluxo de trabalho. E se você quiser aprender ainda mais sobre Engenharia de Dados, tenho a dica certa para você! Fique com a Formação Iniciando com Engenharia de Dados.
Caso queira aprofundar seus conhecimentos sobre os executores, em específico o Local e Celery, recomendo o curso Aprofundando no Airflow: Executores Local e Celery, que aborda esses dois temas no contexto do mercado financeiro.
Créditos:
- Conteúdo: Marcelo Cruz
- Produção técnica:
- Produção didática: Thaís de Faria
- Designer gráfico: Alysson Manso





