Otimização de hiperparâmetros


A biblioteca Scikit Learn, da linguagem de programação Python, é voltada para o Machine Learning, com o objetivo de prever determinadas ações através de padrões de uma base de dados. Ela possui diversas funções que exigem parâmetros para a perfeita execução do código e algum deles assumem um estado default (padrão), retornando um valor que, até então, é o melhor resultado que podemos encontrar.
Mas será que são mesmo?
Na verdade, podemos modificar os parâmetros dessas funções, chamados hiperparâmetros, com o intuito de melhorar o resultado. O nome desse processo se chama tunning de hiperparâmetros.
Neste artigo vamos utilizar uma base de dados pronta que o próprio sklearn disponibiliza, assim podemos focar na otimização de hiperparâmetros. Vamos utilizar a base Breast cancer wisconsin que contém informações de nódulos e os classifica entre benigno ou maligno.
Carregando a base
Primeiramente, vamos carregar a base de dados.
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
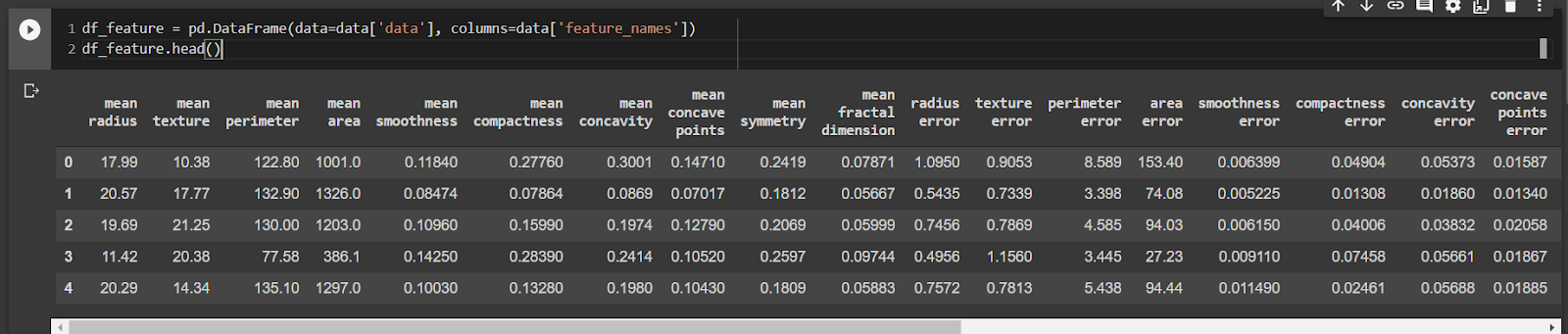
Em seguida, vamos transformar essa base em um DataFrame do Pandas para facilitar a visualização dos dados.
import pandas as pd
df_feature = pd.DataFrame(data=data['data'], columns=data['feature_names'])
df_feature.head()
Agora vamos criar uma tabela com apenas uma coluna, denominada Series do Pandas para os Targets, que são a classificação dos dados. Vamos utilizar o método unique para visualizar que teremos apenas duas classes 0 e 1.
ser_targets = pd.Series(data=data['target'], name='benign')
ser_targets.unique()
Agora vamos transferir os dados para as variáveis X e y por convenção.
X = df_feature
y = ser_targets

Primeiro modelo
Vamos explorar o modelo DecisionTreeClassifier, que é uma árvore de decisão que classifica os dados, no nosso caso, entre 0 e 1. Primeiro utilizamos seus hiperparâmetros definidos por padrão.
from sklearn.tree import DecisionTreeClassifier
modelo_arvore = DecisionTreeClassifier()
Um ponto importante é que vamos usar o conceito de cross-validation, onde tentamos minimizar os efeitos que a aleatoriedade dos dados selecionados para treino e teste podem ter no nosso resultado. O que o cross_validate vai fazer é separar nossos dados em 5 grupos e utilizá-los para treinar vários modelos, no caso 5 vezes porque definimos o cv=5, variando quais dados serão para treino e quais serão para teste.
results = cross_validate(modelo_arvore, X, y, cv=5,
scoring=('accuracy'),
return_train_score=True)
O cross_validate vai nos retornar o results contendo as principais informações que ele calculou, vamos focar no mean_train_score e no mean_test_score que são, respectivamente, a precisão média com os valores de treino e a precisão média com os valores de teste.
print(f"mean_train_score {np.mean(results['train_score']):.2f}")
print(f"mean_test_score {np.mean(results['test_score']):.2f}")
Obtivemos:
mean_train_score 1.00
mean_test_score 0.92
Tivemos um bom resultado de Score, porém tivemos uma precisão de 100% nos dados de treino, o que nos indica um overfitting quando o modelo fica especializado nos dados de treino.
Otimizando os hiperparâmetros
Os hiperparâmetros são características do seu modelo que podem ser definidas através dos parâmetros. Por exemplo, o DecisionTreeClassifier conta com os parâmetros max_depth e min_samples_split que, dependendo do valor, entregam um modelo melhor adaptado aos seus dados.
Mas isso nos traz uma questão. Basta olhar para a documentação de algum desses algoritmos para notar a infinidade de parâmetros que temos e, por consequência, muitas possibilidades. Para esse problema temos duas soluções: definir os valores e hiperparâmetros que vamos explorar ou explorar aleatoriamente. Essas duas estratégias estão implementadas no scikit-learn, o GridSearchCV e o RandomizedSearchCV
Vamos começar pelo GridSearchCV. Ele nos permite definir um espaço que queremos explorar, por exemplo:
from sklearn.model_selection import GridSearchCV
espaco_de_parametros = {
"max_depth" : [3, 5],
"min_samples_split" : [32, 64, 128],
"min_samples_leaf" : [32, 64, 128],
"criterion" : ["gini", "entropy"]
}
Aqui definimos um dicionário onde a chave é o nome do parâmetro que queremos otimizar e o valor é uma lista com os valores que queremos que ele explore. Então, nesse caso, ele treina a árvore usando uma profundidade máxima, max_depth, 3 e 5.
Para usar o GridSearchCV vamos repetir alguns parâmetro que usamos no cross_validate. A novidade vai ser que não vamos mandar o x e o y, e vamos usar o parâmetro param_grid, que será o nosso dicionário.
modelo_arvore = DecisionTreeClassifier()
clf = GridSearchCV(modelo_arvore, espaco_de_parametros, cv=5, return_train_score=True, scoring = 'accuracy')
search = clf.fit(X, y)
results_GridSearchCV = search.cv_results_
indice_melhores_parametros = search.best_index_
Uma outra diferença é que teremos mais de um modelo, então precisamos selecionar o que teve o melhor desempenho. Nós acessamos por busca.best_index_ e então selecionamos ele dentro dos nossos resultados.
print(f"mean_train_score {results_GridSearchCV['mean_train_score'][indice_melhores_parametros]:.2f}")
print(f"mean_test_score {results_GridSearchCV['mean_test_score'][indice_melhores_parametros]:.2f}")
Resultado:
mean_train_score 0.94
mean_test_score 0.92
Para recuperar os parâmetros que tiveram o melhor desempenho vamos usar a chave params:
results_GridSearchCV['params'][indice_melhores_parametros]
Resultado:
{'criterion': 'gini',
'max_depth': 3,
'min_samples_leaf': 32,
'min_samples_split': 32}
Com isso, conseguimos descobrir o melhor modelo dentre o grupo de parâmetros que definimos, mas isso pode ser um problema, porque o espaço de possibilidade é bem maior. Assim, a melhor combinação de parâmetros pode estar em outro lugar nesse espaço. Pensando nisso temos a segunda solução, o RandomizedSearchCV. Nele definimos o espaço que queremos explorar e ele aleatoriamente vai testar as combinações de hiperparâmetros, além de testar a quantidade que você vai determinar pelo parâmetro n_iter, que é o número de interações.
from sklearn.model_selection import RandomizedSearchCV
Primeiro vamos definir esse espaço. Veja que agora podemos incluir um grande número de possibilidades, já que não serão todas testadas. Por exemplo, no min_samples_split testamos números aleatórios entre 32 e 129.
from scipy.stats import randint
espaco_de_parametros = {
"max_depth" : randint(1, 10),
"min_samples_split" : randint(32, 129),
"min_samples_leaf" : randint(32, 129),
"criterion" : ["gini", "entropy"]
}
Com o espaço definido, podemos seguir para utilização do RandomizedSearchCV. Veja que vamos usar de maneira semelhante ao GridSearchCV, porém com um parâmetro a mais, o n_iter, que é a quantidade de combinações que ele vai tentar.
modelo_arvore = DecisionTreeClassifier()
clf = RandomizedSearchCV(modelo_arvore, espaco_de_parametros, random_state=SEED, cv=5, return_train_score=True, n_iter=100, scoring='accuracy')
search = clf.fit(X, y)
results_RandomizedSearchCV = search.cv_results_
indice_melhores_parametros = search.best_index_
Para poder comparar os resultados, modifiquei a função apresentada anteriormente para utilizar esses otimizadores de hiperparâmetros:
print(f"mean_train_score {results_RandomizedSearchCV['mean_train_score'][indice_melhores_parametros]:.2f}")
print(f"mean_test_score {results_RandomizedSearchCV['mean_test_score'][indice_melhores_parametros]:.2f}")
Resultado:
mean_train_score 0.92
mean_test_score 0.91
Para recuperar os parâmetros que tiveram o melhor desempenho vamos usar a chave params:
results_RandomizedSearchCV['params'][indice_melhores_parametros]
Resultado:
{'criterion': 'gini',
'max_depth': 4,
'min_samples_leaf': 34,
'min_samples_split': 105}
Com isso podemos notar que podemos explorar ainda mais os algoritmos. Recomendo explorar a documentação dos algoritmos que você estiver trabalhando. Verifique se há hiperparâmetros a serem explorados e encontre os melhores para os seus dados e para o seu objetivo.
Nesse notebook você encontra o código completo do projeto.
Se você ficou com curiosidade e quer saber mais sobre melhorar os modelos, temos um episódio do Hipsters.tech sobre Engenharia de machine learning .