Paulo Silveira é CEO e cofundador da Alura. Bacharel e mestre em Ciência da Computação pela USP, teve sua carreira de formação em PHP, Java e nas maratonas de programação. Criou o Guj.com.br, o podcast do Hipsters.tech e o Like a Boss.
Inscreva-se em nossa Newsletter
Fique por dentro de conteúdos, insights e oportunidades do universo tech. Receba novidades e lançamentos direto no seu e-mail.
A primeira coisa que eu quero saber nesse episódio é: afinal, o que é Ciência de Dados? Guilherme, você pode dar um exemplo para a gente entender?
GUILHERME SILVEIRA:
Hoje em dia, quando a gente fala da ciência de dados, pensa num guarda-chuva que inclui muitas coisas. Então vou dar um exemplo de uma parte disso que a gente costuma chamar de ciências de dados.
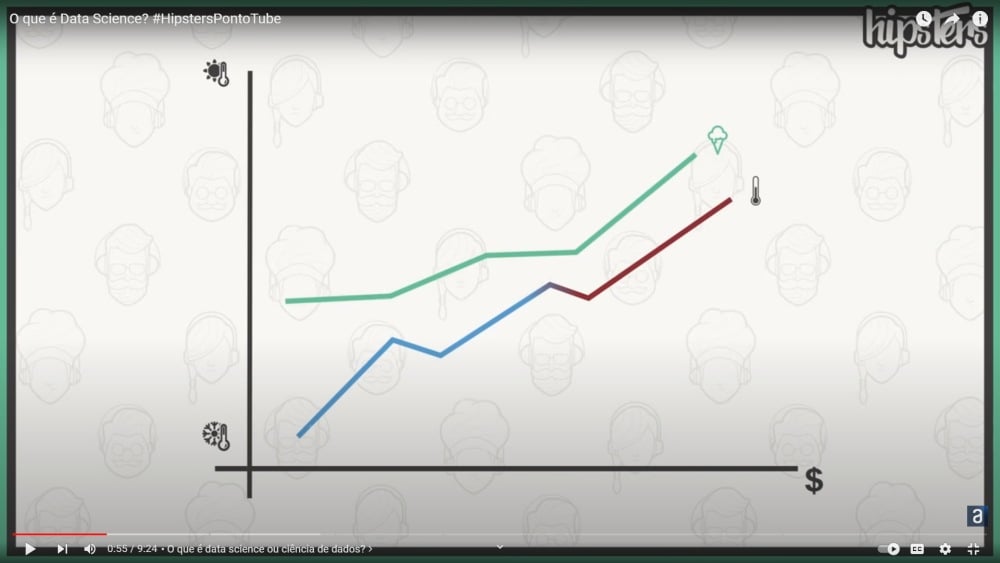
E a ideia é, pensa numa empresa que vende sorvete ou outros objetos gelados que a gente gosta de tomar, né? — em momentos, principalmente, quentes — e quando você começa a analisar as vendas mensais ou diárias e do lado desses números você coloca a temperatura do dia ou a temperatura média do mês, você pode perceber que existe uma relação ou, mais especificamente, uma correlação entre esses dois valores, essas duas sequências de valores.
Quando a temperatura é mais alta tem mais consumo de sorvete, mais baixa tem menos consumo, elas crescem juntas.
Ou ainda outras variáveis, você olha a variável “se o tempo está nublado” ou “se choveu" e percebe que é ao contrário a correlação. Quando chove tem menos consumo. E você pode encontrar esse tipo de comportamento que não necessariamente é uma relação de causa, mas uma correlação que existe entre esses números.
PAULO SILVEIRA:
O que pode trazer alguma dica ou algum sinal de que você deve investigar mais.
GUILHERME SILVEIRA:
Isso! Até, por exemplo, se eu sei que a previsão do tempo no mês que vem vai tá muito quente, então é bom eu produzir muito sorvete, agora se no mês que vem não vai estar tão quente, não faz sentido fazer tanto estoque, porque eu não vou vender e distribuir tanto sorvete assim.
Estou citando o ramo de sorvetes, mas no ramo da moda isso é super tradicional, o ciclo de produção da moda é muito longo, então para o verão que vem já preciso ter uma ideia de quanto eu vou vender para poder a fábrica produzir essa quantidade específica de saia e bermuda etc, que são uma roupas do verão, por exemplo.
Data Science, Corporações e Sociedade – Hipsters Ponto Tech #250
spotify:5JI9mJov3WpvKrsKcVvVVD:episode
O que é análise exploratória?
PAULO SILVEIRA:
Esse tipo de pergunta que você está fazendo “ah, será que vende mais ou vende menos sorvete de acordo com a temperatura?”, o que parece meio óbvio, eu posso tentar correlacionar com outros tipos de variáveis que às vezes a gente nem imagina, correto?
Então, parece que a pessoa cientista de dados lida com uma pergunta que ela não sabe exatamente o que está procurando. Isso tem a ver com esse nome que se usa bastante, análise exploratória?
GUILHERME SILVEIRA:
Esse termo foi cunhado bem recentemente, aliás, sabe? Menos de um século, há 50 anos atrás. Para definir e separar duas partes nos estudos dos dados, porque uma parte é realmente testar uma teoria que eu tenho, uma hipótese, que eu quero ver se é verdadeira. Então se eu tenho uma teoria que é quando faz calor vende mais, eu posso fazer um teste para isso, ou outras coisas, por exemplo, a teoria de que um remédio cura gripe e, então, faço um teste para isso.
Então isso é uma fase em que eu posso trabalhar, mas antes disso você pode ter uma outra fase que é simplesmente olhar os dados, ver o que que você encontra por lá e essa é a fase de análise exploratória. Com isso, você pode encontrar diversas coisas que nem espera, levantar perguntas baseadas nos dados que você olhou e depois que levantou todas as perguntas, intuições, hipóteses, você coloca elas em teste, cria modelos e faz outras coisas.
Exemplo real de análise exploratória
PAULO SILVEIRA:
Acho que você tem outro exemplo interessante que trouxe para a gente.
GUILHERME SILVEIRA:
Tem um outro exemplo, que é de onde eu trabalho, uma Escola online, a Alura, e lá dentro a gente tem diversos cursos e diversas pessoas.
As pessoas fazem cursos e estudam, mas como é online e pode usar a qualquer hora, tem gente que estuda 1 vez por semana, 2 vezes por semana, 3 vezes por semana, de vez em quando, de vez em nunca, com ritmo ou sem ritmo, tem tudo. E, se você olhar os dados, uma das coisas que você percebe é que quem visita duas vezes por semana ou mais (a plataforma), tem uma taxa de conclusão de cursos a curto, médio e longo prazo totalmente diferente de quem visita num ritmo menor.
O que me lembram um pouco o cursinho de inglês que a gente faz quando é criança, você vai lá de segunda e quarta ou de terça e quinta, não é simplesmente vai quando você quer, no horário que for, e ponto final. Ter um ritmo faz você manter aquele trabalho a médio-longo prazo, então a gente vê uma correlação entre você ter ritmo com um objetivo a médio-longo prazo de concluir diversos estudos.
Agora se isso é uma consequência, uma relação de causa ou é só uma correlação a gente tem que fazer algum teste para poder ter essa certeza.
Guia do Iniciante em Data Science – Hipsters Ponto Tech #221
spotify:5i9WWlTRDQX6QQp4BaB4b7:episode
O que é Causa e Correlação?
PAULO SILVEIRA:
Às vezes só ser a correlação é um sinal bom para a gente pensar “olha como instituição de ensino, vamos tentar engajar as pessoas a usarem mais a plataforma, porque elas vão concluir e ter um melhor aproveitamento” ou a gente acha, é uma hipótese.
GUILHERME SILVEIRA:
Com certeza, existe uma frase famosa, que obviamente eu não lembro de cabeça, que diz que a correlação não é causalidade, mas é um bom indício. Apesar que se você for procurar, tem um livro chamado spurious correlations.
O site que tem um livro, eu acho que o livro é do mesmo nome e tem exemplos super legais de correlações super interessantes, por exemplo, os anos que a bolsa dos Estados Unidos subiu com relação aos anos que o Nicolas Cage lançou o filme.
PAULO SILVEIRA:
E ela (correlação) segue direitinha a curva!
GUILHERME SILVEIRA:
O gráfico é igualzinho nos dois. Então tem uma correlação, a gente sabe obviamente que essa correlação não faz sentido, mas existe. Então tem que tomar sempre muito cuidado com como a gente analisa os dados, porque a gente pode cometer diversos tipos de erros que trazem conclusões que não fazem sentido.
Como nasceu o termo Ciências de Dados?
PAULO SILVEIRA:
Então porque que nasceu esse termo ciência de dados, sendo que eu acho que isso tudo que você está me contando parece muito com o que as pessoas faziam no Excel, numa planilha e que antigamente tinha uns nomes mais pomposos, como Business intelligence ou até Data Mining, o que aconteceu que nos últimos anos para cá isso estourou com esse termo de ciência de dados e não com o tal do Business intelligence ou Data Mining.
GUILHERME SILVEIRA:
A Inteligência Artificial, Machine Learning e a Ciência de Dados são realmente termos que trouxeram muita força para algumas coisas que as pessoas já faziam, então o pessoal de Analytics, Análise de Risco, muita gente que estudou Física, Oceanografia, Matemática, algumas das Engenharias etc, diversas áreas diferentes já utilizavam esses tipos de técnicas para criar modelos, para testar, para avaliar, para entender uma empresa ou uma situação, tudo isso já era utilizado com diversos nomes diferentes, com especificidades diferentes.
Mas com esse advento cada vez mais forte seja da linguagem Python, Machine Learning, Redes Neurais etc, acabou sendo cunhado alguns termos que o mundo do mercado pegou.
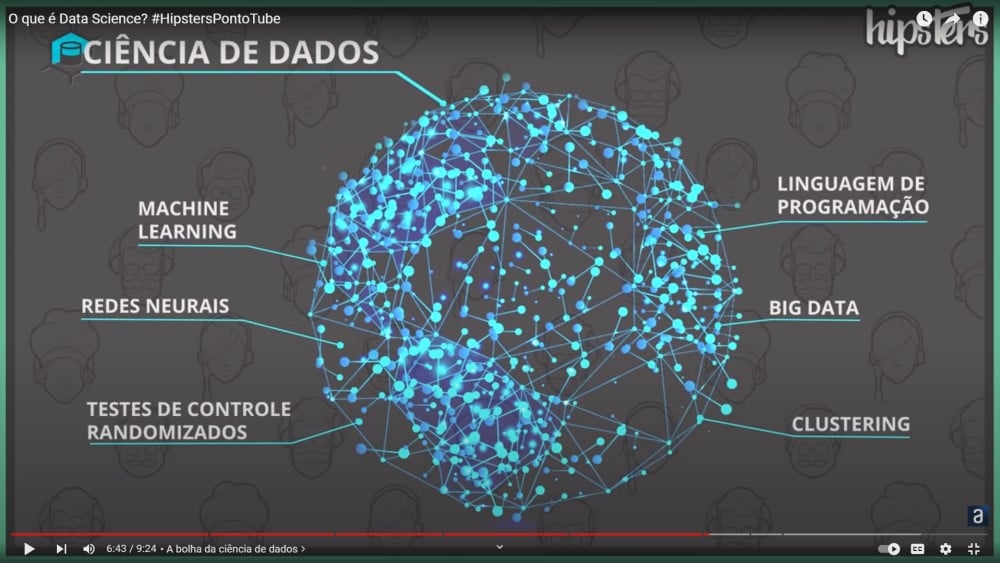
O guarda-chuva da Ciências de Dados
GUILHERME SILVEIRA:
Então o guarda-chuva (o universo) mais genérico ficou sendo esse de ciência de dados, então meio que: está ligado com dados? Está dentro do guarda-chuva de ciência de dados.
Então são coisas que já eram feitas, podiam ser feitas em Excel, muita gente usa Excel para fazer várias dessas coisas, ainda hoje em dia, mas também existe uma migração do pessoal do Excel indo para o Python ou indo para o R ou o pessoal que já era do R (estão migrando também), tem tudo isso acontecendo.
Primeiros Passos em Data Science: Do Excel e BI ao Python – Hipsters #134
spotify:17FZ1Dny1y9cCGjyg4eYcy:episode
Websérie: Universo Data Science
Data Science: por onde eu começo? | Universo Data Science #01
Pois é, twittei recentemente a piada de um colega, que o Python é o novo Excel, faz sentido?
GUILHERME SILVEIRA:
Talvez né, porque eu acho o Excel ainda mais amigável para o usuário final, por mais que fazer fórmulas, uma dentro da outra etc, não seja nada trivial né, a maneira funcional e reativa do Excel, não é trivial, mas eu ainda ainda acho que o Excel é mais tranquilo de aprender a primeira vez.
Linguagens e bibliotecas de Data Science: R, Python, Pandas
PAULO SILVEIRA:
E onde que entra então, essas siglas, essas palavras-chaves, Python, R e Pandas que estão muito no dia a dia do(a) cientista de dados?
GUILHERME SILVEIRA:
Então, existe o Excel que é uma forma da gente trabalhar os dados numa planilha e, que eu acho super legal, porque é fácil da gente visualizar essas informações, mas a gente também pode descrever isso de uma maneira que a gente manda o computador fazer coisas, (de maneira) imperativa, que em geral imperativo é o que a gente acaba usando nessas outras linguagens, e com isso você tem o Python, o R e outras linguagens como alternativas ao Excel, existem outras ferramentas também, claro né.
Então você vai ter, talvez mais controle, talvez (com a possibilidade de) fazer coisas mais profundas, com mais facilidade e vai ter uma luta de linguagens um pouco, mas são alternativas, o Excel, o R, o Python, cada uma com suas vantagens e desvantagens.
Dentro do mundo do Python, você vai ter, por exemplo, o Pandas como uma biblioteca que basicamente todo mundo utiliza, o Jupyter basicamente como espaço de exploração para fazer testes, com espaço exploratório. Mas se você correr atrás, você vai ver gente usando o mesmo Jupyter, não só para fazer um teste, mas para rodar coisas para valer mesmo, como o Netflix que usa um cluster de Jupyter rodando os algoritmos deles de machine learning.
Então você pode usar essas ferramentas para fazer outras coisas, se você tem o Pandas como a principal, provavelmente, biblioteca de Python, tem Numpy também, mas é mais numérico, mas o pandas é a principal biblioteca de uma dessas linguagens.
O que faz uma pessoa cientista de dados?
O que faz uma Cientista de Dados? com Mikaeri Ohana | #HipstersPontoTube