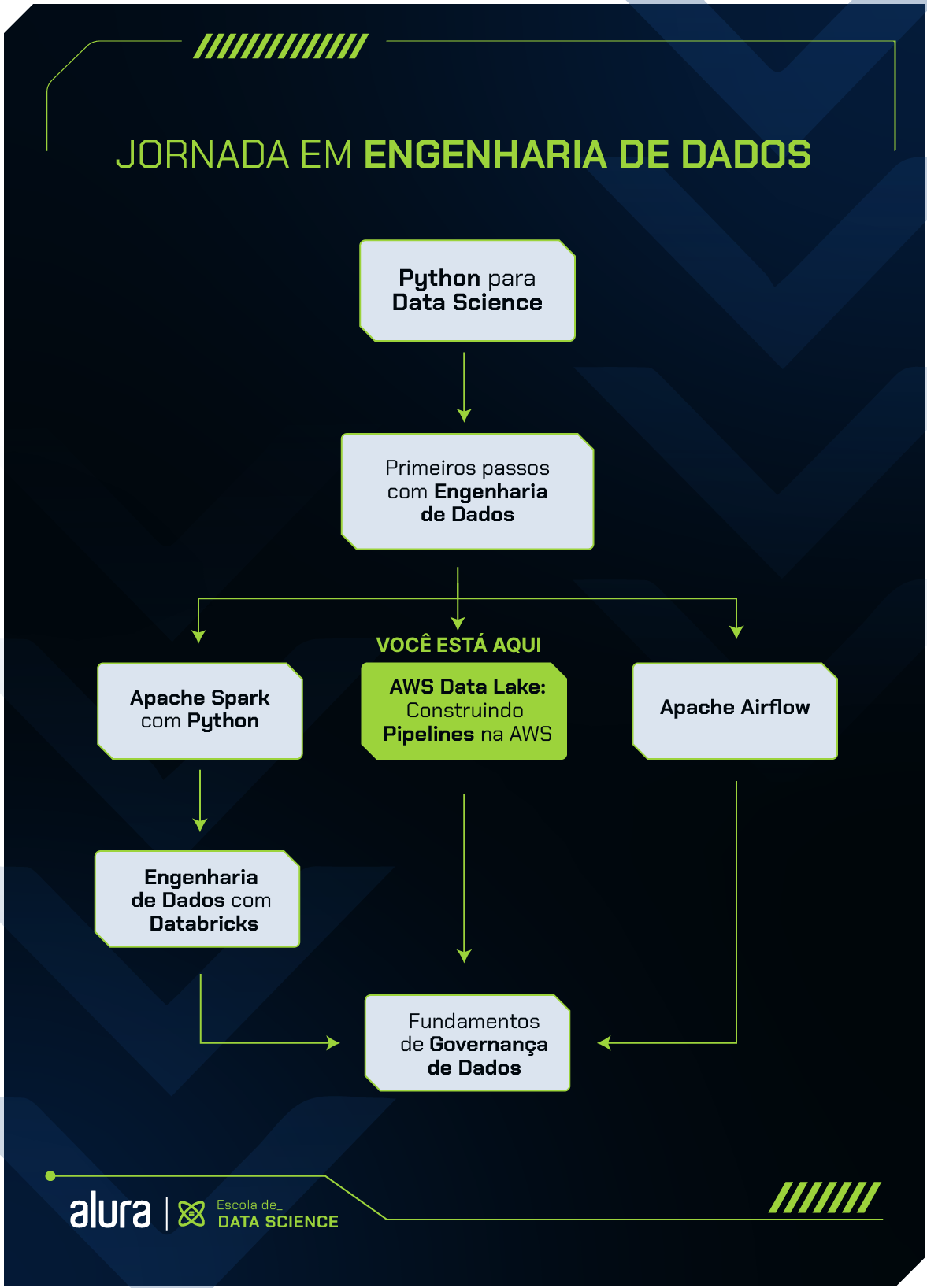
O que é AWS?
A AWS (Amazon Web Services) é uma plataforma de serviços em nuvem oferecida pela Amazon. No contexto de Engenharia de Dados, a AWS desempenha um papel significativo ao fornecer uma variedade de serviços e ferramentas que facilitam a coleta, processamento, armazenamento e análise de grandes volumes de dados.