Data Lake: conceitos, vantagens e desafios


A partir da geração de várias fontes e tipos diferentes de dados, surgiu um desafio: como absorver e analisar essas informações em formatos diferentes?
Afinal de contas, as soluções tradicionais de armazenamento de dados e análise não estavam preparadas para isso.
A solução para essa questão estava em criar soluções personalizadas e complexas. O que tornava todo processo bastante devagar.
Foi aí que surgiu o Data Lake, como uma ferramenta para tornar os dados adequados para pré-processar e transformar os dados em formatos possíveis de se analisar através do modelo tradicional.
Se você se interessou sobre esse assunto, continue a leitura para descobrir tudo sobre o Data Lake. O objetivo desse artigo é refletir sobre o que é, mas principalmente como funciona, as vantagens e os desafios desse repositório.
O que é Data Lake?
O Data Lake, ou datalake, é um repositório altamente flexível e escalável que armazena dados brutos em diversos formatos, sendo: dados estruturados, semiestruturados e não estruturados.
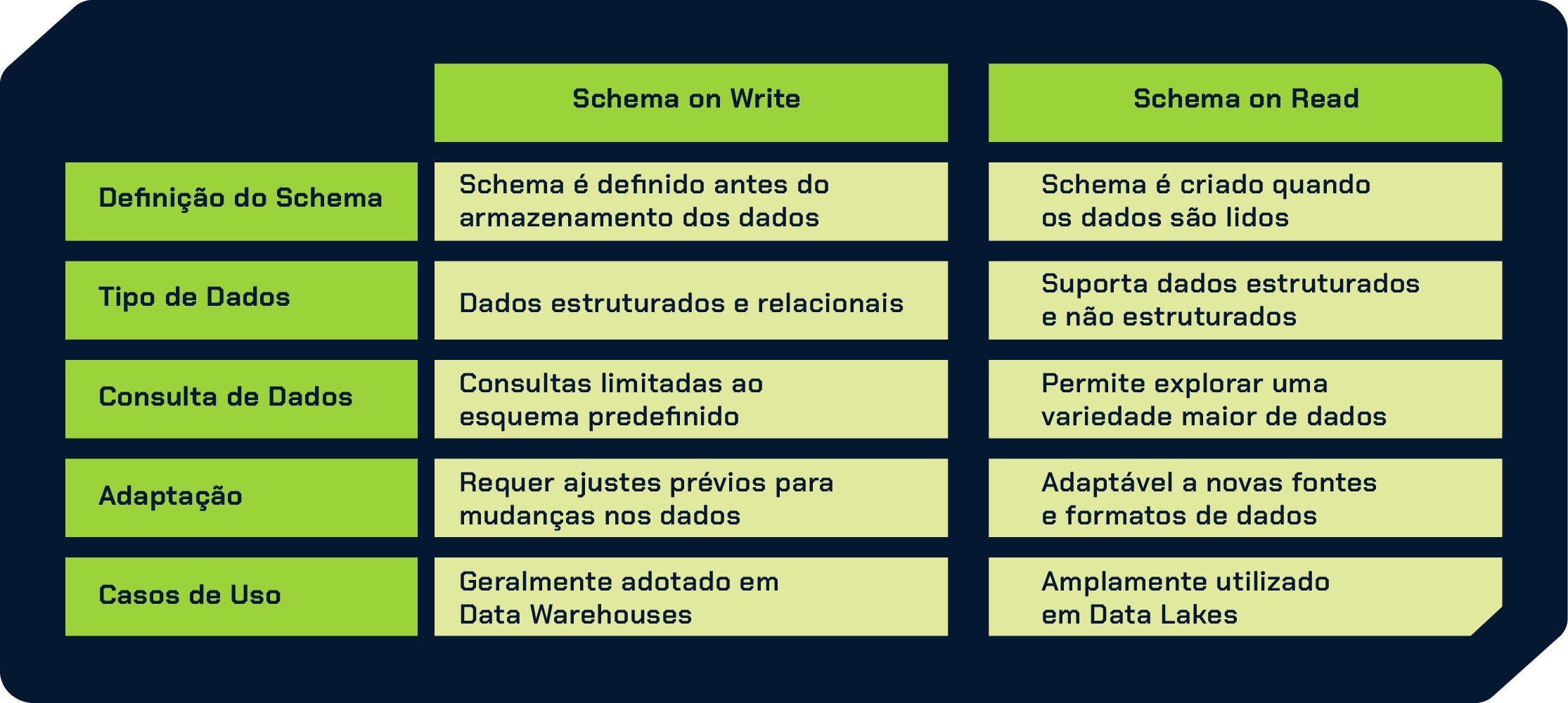
Diferentemente do Data Warehouse tradicional, que requer pré-processamento dos dados antes do armazenamento, o Data Lake adota o conceito de “schema on read”, o que significa que a estruturação dos dados ocorre apenas quando são lidos, conforme a necessidade.
Essa abordagem permite uma ingestão mais rápida e facilita a exploração e análise dos dados, adaptando-os conforme a interpretação necessária no momento da leitura.
Desta forma, vamos ter uma vantagem significativa, especialmente ao lidar com dados de streaming em tempo real, pois evita altos gastos com processamento e tratamento de dados a todo momento, permitindo selecionar apenas os dados necessários para análises e tomadas de decisões assertivas.
Por isso o Data Lake se destaca pela agilidade, escalabilidade e eficiência na gestão de dados, possibilitando a extração de insights valiosos de forma mais rápida e econômica em comparação ao Data Warehouse.
Caso queira um exemplo prático sobre Data Lakes, confira nosso podcast Hipster.tech para entender e conhecer o caso de uso do Banco PAN:

Como surgiu o data lake
Há algum tempo, a gestão de dados estava centrada em informações estruturadas, seguindo o modelo rígido como de um Data Warehouse.
No entanto, com o surgimento de fontes diversas e dados não estruturados, surgiram desafios na absorção e análise dessas informações em diferentes formatos.
Mas, para lidar com esse tipo de problema, era necessário criar soluções customizadas e complexas, tornando o processo lento e ineficiente.
As soluções tradicionais de armazenamento e análise não estavam preparadas para absorver, processar e extrair valores dessas informações de diferentes formatos.
Era como tentar montar um quebra-cabeça com peças que não se encaixavam no modelo rígido preestabelecido pelo Data Warehouse.
Para resolver isso, as empresas se viam obrigadas a recorrer a soluções customizadas e trabalhosas, envolvendo processos complexos de pré-processamento e transformação dos dados para torná-los adequados ao modelo tradicional.
Então, como solução a esse problema, o conceito de Data Lake revolucionou a forma como lidamos com dados.
Isso porque ele permite a coleta, o armazenamento e a análise de dados brutos, estruturados ou não, em um mesmo ambiente integrado.
Como funciona um Data Lake?
Como foi dito antes, a principal ideia por trás de um Data Lake é que ele armazena todos os tipos de dados em seu formato original, sem a necessidade de pré-definir esquemas rígidos como ocorre nos bancos de dados tradicionais.
Por isso, um Data Lake é uma solução avançada para lidar com os desafios de Big Data.
E, para funcionar adequadamente, são necessárias algumas etapas que garantem a integração, armazenamento seguro e o processamento eficiente dos dados:
- Ingestão de dados: diversas fontes são coletadas, como bancos de dados transacionais, dispositivos IoT, logs de servidores e entre outros tipos de dados.
Nessa fase, uma ferramenta como o Apache Kafka é comumente utilizada para facilitar a captura e movimentação contínua de dados para o Data Lake.
Armazenamento: os dados brutos são armazenados no Data Lake em sua forma original. A estruturação dos dados é flexível e pode ser realizada posteriormente, conforme as necessidades de análise.
Processamento e orquestração: nesta etapa, ferramentas de orquestração, como o Apache Airflow, são empregadas para agendar e gerenciar os fluxos de trabalho de processamento de dados.
Essas ferramentas possibilitam criar pipelines de dados, onde diversas tarefas podem ser executadas sequencial ou paralelamente, garantindo uma transformação adequada dos dados antes da análise.
- Catalogação e metadados: é importante manter um catálogo de metadados que descreva os dados armazenados no Data Lake.
Metadados são informações sobre os dados, como etiquetas que descrevem a origem, formato e outras características essenciais dos dados.
Eles ajudam a entender a origem dos dados, sua qualidade, estrutura e quaisquer outros atributos relevantes.
As informações do catálogo facilitam a descoberta e o uso eficiente dos dados, tornando-os mais acessíveis e compreensíveis para os usuários e usuárias do Data Lake.
- Acesso e análise: com os dados armazenados em seu formato bruto e estruturados de acordo com as necessidades, as pessoas usuárias podem acessar o Data Lake para realizar análises avançadas, criar relatórios e obter insights valiosos.
Para isso podemos utilizar o Apache Spark para explorar os dados e executar consultas analíticas.
- Segurança e governança: para garantir a segurança e conformidade dos dados, mecanismos de controle de acesso e políticas de governança devem ser implementados no Data Lake.
Isso assegura que apenas as pessoas autorizadas possam acessar os dados e que o uso dos dados esteja em conformidade com as regulamentações aplicáveis.
Vantagens e desafios do Data Lake
A escolha de implementar um Data Lake pode oferecer tanto vantagens quanto desafios, como qualquer outro tipo de decisão para projetos de dados.
Por isso, é interessante sempre analisar bem antes de definir como resolvemos nossos projetos. No caso do Data Lake podemos levar algumas informações em consideração:
Vantagens
Escalabilidade: capacidade de lidar com grandes volumes de dados, expandindo facilmente, conforme necessário.
Flexibilidade: possibilidade de armazenar diferentes tipos de dados em seu formato original, permitindo maior diversidade e enriquecimento das análises.
Custo-benefício: opção mais econômica em relação a soluções tradicionais de armazenamento de dados.
Análise avançada de dados: o Data Lake possibilita um ambiente robusto para análises detalhadas e insights valiosos, permitindo que os usuários e usuárias extraiam informações importantes para a tomada de decisões.
Desafios
Segurança: garantir a proteção dos dados, especialmente dados sensíveis armazenados no Data Lake.
Governança: estabelecer políticas claras de gerenciamento e responsabilidade para garantir a conformidade e integridade dos dados.
Qualidade dos dados: assegurar que os dados sejam consistentes, precisos e confiáveis, apesar da diversidade de fontes.
Complexidade de gerenciamento: lidar com a gestão eficiente do Data Lake em ambientes com grande volume de dados e múltiplas pessoas usuárias.
É importante ressaltar que quando o Data Lake não é bem gerenciado e organizado, pode-se tornar um Data Swamp (pântano de dados).
Ou seja, um ambiente onde os dados ficam estagnados e desorganizados, dificultando a obtenção de insights úteis.
Por isso, a definição de políticas de governança, processos de qualidade de dados e estratégias de segurança são fundamentais para garantir que o Data Lake seja uma fonte confiável de informações valiosas para a organização.
Sabendo disso, fica mais fácil entender que o Data Lake foi uma revolução para gerenciamento e análise de dados, oferecendo uma solução flexível e escalável para lidar com o desafio do Big Data.
Ao armazenar dados brutos em seu formato original e adotar o conceito de “schema on read”, o Data Lake agiliza o processo de análise, permitindo insights valiosos de maneira eficiente e econômica.
Mesmo com várias vantagens, ainda temos que enfrentar desafios como qualquer outra solução.
Mas, com a abordagem adequada, o Data Lake se torna uma fonte confiável de conhecimento, impulsionando o crescimento e a inovação em um mundo cada vez mais orientado por dados.
Caso queira se aprofundar e aprender mais sobre Data Lakes, não deixe de conferir o curso da Alura sobre Data Lake.
Leia também: Data Lake vs Data Warehouse
Créditos
- Conteúdo: Paulo Calanca
- Produção técnica: Rodrigo Dias e Millena Gená
- Produção didática: Pedro Drago
- Designer gráfico: Alysson Manso