Introdução
Se você conhece alguém ou é da área de Data Science, já deve ter escutado sobre um tal de Jupyter Notebook.
O Jupyter é uma aplicação web interativa que permite a criação e compartilhamento de documentos com código dinâmico, amplamente usada na área de dados, facilitando sua visualização, limpeza e exploração. Além de permitir a mescla de células de código e texto, otimizando a criação de apresentações e relatórios, já que pode se fazer tudo em um só local.
Jupyter se mostra tão relevante para a comunidade que em 2017 foi agraciada com o prêmio ACM Software System Award, um dos mais importantes na área da computação. Entre os projetos que também já foram agraciados, estão nada mais, nada menos que Java, Unix, TeX e a “pouca” utilizada Web, isso mesmo, o famoso www. Mas o Jupyter que se “cuide”, pois não é apenas o Google com o Colaboratory que está nessa briga.
A Netflix entrou em campo lançando no dia 23/10/2019 o Polynote, um notebook poliglota com a intenção de simplificar a ciência de dados e o workflow de machine learning.
Neste artigo vamos realizar um overview sobre os aspectos mais interessantes dessa nova ferramenta que já está fazendo barulho na comunidade e empolgando muitos(as) cientistas de dados por aí.

Um notebook Poliglota
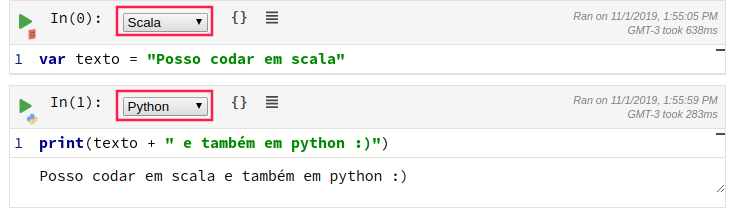
A Netflix é uma das defensoras da programação poliglota, isso é, da prática de escrever códigos em múltiplas linguagens para capturar funcionalidade e eficiência adicionais que não estão disponíveis em uma única linguagem de programação. Visando facilitar a vida dos adeptos a programação poliglota, o Polynote permite codar em diferentes linguagens em um mesmo notebook, até o momento apresentando suporte a Scala, Python e SQL. Como as células compartilham um mesmo contexto, as variáveis declaradas em linguagem podem ser utilizadas uma em outra e vice versa.
Um notebook com “jeito” de IDE
Se você está habituado com IDEs como Pycharm e editores como VScode, deve estranhar um pouco codar em um notebook. Já ví muita gente por aí codando em IDE e só colando o código em um notebook como o Jupyter e Colab (apelido carinhoso do Colaboratory) da google. Claro que o Polynote não tem a intenção de ser um uma IDE completa, mas traz um design diferente dos notebooks “tradicionais” e mais próximo de uma IDE, não é apenas o design que está próximo de uma IDE.
Algumas funcionalidades como auto-complete, lint e e um rico editor de texto com suporte a Latex torna mais evidente a diferença entre Polynote e o Jupyter. Por trás do editor do Polynote está o Monaco, que está por trás do VScode, então ainda podemos ter um avanço incrível nas melhorias do notebook.
Na parte visual, o Polynote pretende deixar os processos que ocorrem no kernel mais transparentes, evitando a necessidade de se aprofundar nos logs. Com esta finalidade o Polynote fornece uma variedade de informações visuais sobre o kernel, por exemplo, uma lista de tasks a serem executadas pelo kernel facilitando acompanhar o progresso de execução e uma tabela das variáveis e seus tipos.
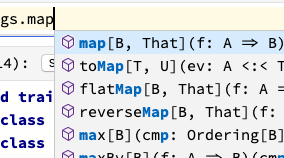
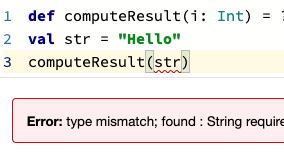
Referências das duas imagens acima: https://polynote.org/
Reprodutibilidade
Nós já falamos sobre a visibilidade (transparência dos processos) que é um dos grandes princípios do Polynote, mas tem outro princípio que guiará o desenvolvimento do notebook da Netflix, a reprodutibilidade. Se você já trabalhou com algum notebook, seja o Jupyter ou o Colaboratory do Google, provavelmente se deparou com a situação onde desenvolveu seu modelo ou análise sem nem um problema. A surpresa vem só quando reiniciar a execução desse notebook e do “nada” ele está quebrado. Se já passou por isso, fique calma(o) que você não foi a(o) primeira(o), eu garanto!
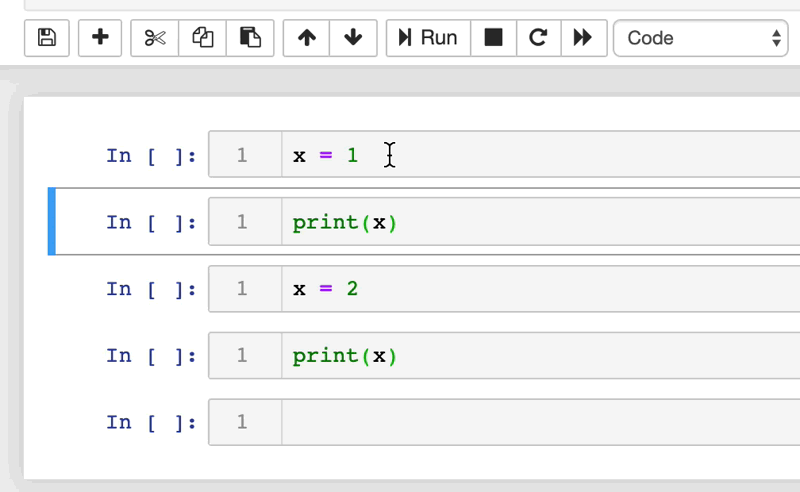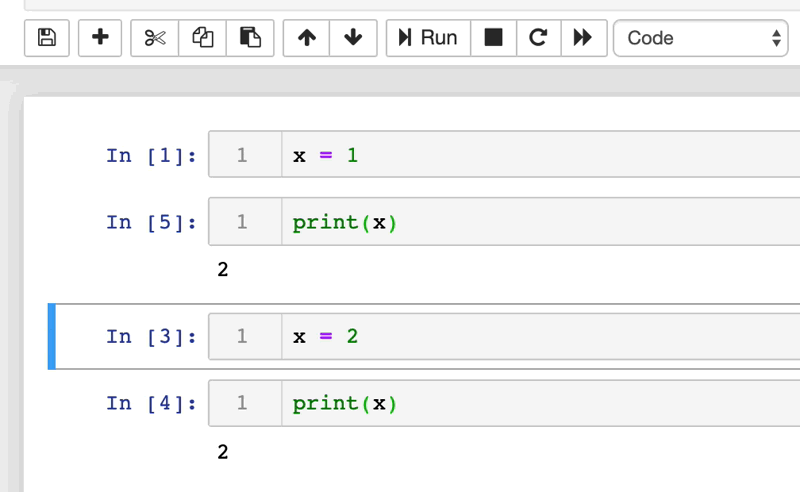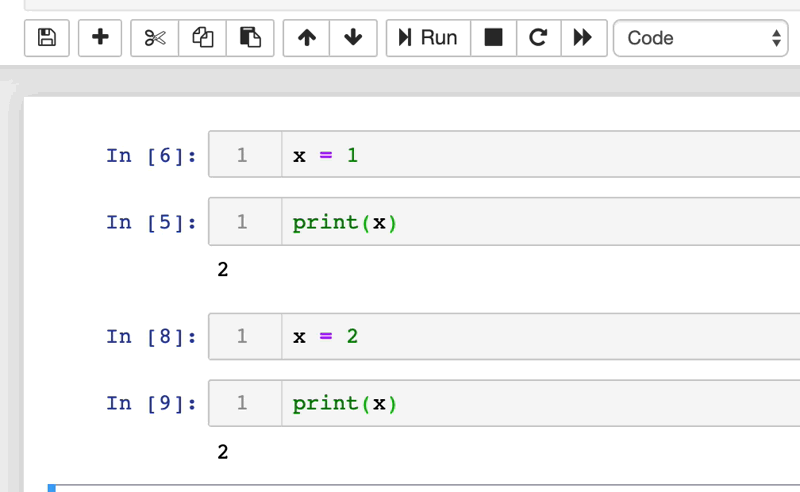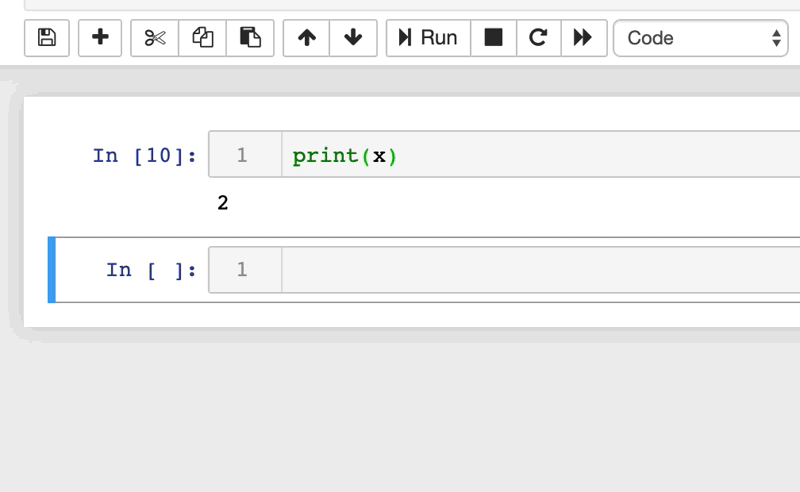
Relembrar o que são os notebooks é importante para compreender o porquê são tão suscetíveis a erros. Os notebooks são uma coleção ordenada de células, cada uma das quais pode conter código ou texto. O conteúdo de cada célula pode ser modificado e executado independentemente. As células podem ser reorganizadas, inseridas, excluídas e podem depender da saída de outras células no notebook.
Muitas vezes, quando declaramos uma variável em um notebook, ela precisa ser acessada em outra célula mais à frente na execução do código. Para isso, a máquina salva essa variável na memória RAM do computador. Podemos rodar as células individualmente e essa memória não é limpa depois que "finalizamos a execução", o que causa alguns problemas. Se por acaso eu mudar o nome de uma variável, o notebook apenas cria uma nova variável na RAM e não deleta a referência antiga. Mas então, quando é que ela limpa a memória do notebook?
Os notebooks vão limpar a memória quando você interromper o kernel ou interromper o servidor web que roda o notebook. Após limpar a memória é que o problema realmente pode aparecer.
Lembra que comentamos de uma variável que teve seu nome modificado, porém manteve as duas referências? Se você não modificou o nome de todos os locais onde a variável é utilizada, ocorrerá um erro (“variável” is not defined). Pode parecer algo simples de corrigir, mas garanto que depois de alguns dias sem olhar para aquele notebook você dificilmente lembrará qual é a variável modificada. Você pode estar questionando que isso quase nunca deve ocorrer… Mas te garanto que ocorre muito mais vezes do que gostaríamos.
Polynote diminui o risco desse tipo de erro mantendo o controle das variáveis definidas em cada célula. Polynote constrói o estado de entrada para uma determinada célula com base nas células que foram executadas acima dela. O Polynote constrói o input para uma célula com base nas células executadas anteriormente, o que torna a posição das células mais importante do que em outras ferramentas.
Isso permite que os usuários executem os notebooks de cima para baixo, sem grandes surpresas quando o runtime é reiniciado. Garante a reprodutibilidade, tornando muito mais provável que a execução sequencial do notebook funcione.
Referência: https://medium.com/netflix-techblog/open-sourcing-polynote-an-ide-inspired-polyglot-notebook-7f929d3f447
Considerações
Claro que nem tudo são flores, Polynote é um projeto grande que está começando e tem um caminho longo (e na minha visão promissor) para percorrer. O processo de instalação não é muito otimizado, apresenta suporte apenas para macOS e Linux.
Com pouco tempo de uso, já foi possível observar alguns bugs como não funcionar auto-complite em funções lambda. No processo de instalação em Linux a maior dificuldade que passei foi ao instalar uma lib python chamada jep, que é uma das dependências do Polynote. Jep é instalado pelo pip e como pip necessita de permissão sudo, jep não localizava o java_home já configurado. Se passar por problema semelhante, é só colocar a flag -E no sudo, assim fica, sudo -E pip install jep e problema resolvido.
Apesar dos contratempos, são vários pontos positivos (alguns que nem citei, como a configuração de ambiente por notebook e a ferramenta de visualização de dados) e as inovações trazidas pelo Polynote está deixando a comunidade empolgada.
As melhorias e ideias agregadas ao notebook da Netflix afeta substancialmente o dia a dia de cientistas de dados, engenheiros(as) de machine learning e de dados. Agora, a ideia é aprender mais sobre a nova ferramenta, contribuir para seu desenvolvimento, aguardar pelas próximas versões e esperar que os outros notebooks como Jupyter e Colaboratory adotem as boas ideias advindas pelo Polynote.
Vou deixar o link alguns links para quem quiser ler mais sobre o assunto: