O que é Data Science: conceitos, aplicações práticas e um bate papo sobre carreira


Data Science ou Ciência de Dados é um campo que vem ganhando destaque nas oportunidades de carreira e nas ofertas de cursos online e em currículos universitários.
Mas, afinal, o que realmente engloba essa área e quais são as razões que tornam seu aprendizado tão valioso?
Este artigo se propõe explorar o universo da Ciência de Dados, destacando não apenas sua essência e aplicações práticas, mas também delineando um caminho para aquelas pessoas que querem se aprofundar e talvez fazer carreira nesse campo em constante evolução.
E para nos ajudar a entender tudo isso, nós vamos contar com expertise da nossa convidada especial Sthefanie Monica Premebida que é Cientista de Dados Senior na Heineken e vai responder algumas perguntas sobre atuação profissional da pessoa cientista de dados.
História e Evolução da Ciência de Dados
Apesar de ser um termo novo, a Ciência de Dados tem raízes bem estabelecidas em décadas de evolução nas áreas de estatística, matemática, informática e análise de dados.
Quem usou a primeira vez esse termo foi Peter Naur, intitulado Concise Survey of Computer Methods, em 1974.
Pois bem, nesse texto ele definiu o termo como: “a ciência de tratar com dados, coletá-los, analisá-los e interpretá-los”.
A partir daí, surgiu o reconhecimento da Ciência de Dados como um campo independente, embora ainda estivesse fortemente ligado à estatística.
Com o advento da era da informação, especialmente nos anos 90 e início dos anos 2000, a Ciência de Dados começou a se moldar como conhecemos hoje.
Durante este período, a quantidade de dados gerados pela digitalização de quase todos os aspectos da vida diária cresceu exponencialmente.
Isso, combinado com o rápido desenvolvimento de tecnologias de armazenamento e processamento, como bancos de dados e algoritmos de aprendizado de máquina, proporcionou um terreno fértil para o crescimento da Ciência de Dados.
Em 2001, William S. Cleveland, professor de Ciência da Computação na Purdue University, publicou um artigo de nome Data Science: An Action Plan for Expanding the Technical Areas of Field of Statistics, que propôs uma expansão do campo da estatística, incorporando técnicas de computação e software, e cunhou o termo “Data Science” como conhecemos hoje.
Na última década, a Ciência de Dados se consolidou e se expandiu como uma disciplina distinta.

O que é Ciência de Dados (ou Data Science)?
Com o surgimento do Big Data, que visa lidar com enormes volumes de dados e a necessidade crescente da tomada de decisões baseadas em dados, a Ciência de Dados se estabeleceu como um campo interdisciplinar.
No estágio atual essa área abrange não apenas estatística, mas também Inteligência Artificial, mais especificamente aprendizagem de máquina, visualização e análise de dados.
O desenvolvimento contínuo e o crescimento da área de dados dentro das empresas fez com que a área de dados fosse desmembrada em diversas carreiras, tais como:
- Analista de Dados;
- Engenharia de Dados;
- Ciência de Dados; e
- Engenharia de Machine Learning.
No último ano, o surgimento de grandes modelos de linguagem tem proporcionado a interação com assistentes virtuais de análise de dados.
Porém, mais importante que isso, diversas empresas têm buscado por Cientistas de Dados capazes de lidar com problemas envolvendo texto (processamento de linguagem natural) e o ajuste fino desses modelos para tarefas específicas.
Perguntas e respostas para Sthe Monica, Cientista de Dados Sênior na Heineken
Dado esse contexto inicial, chegou a hora de trazermos a primeira parte do bate papo que tivemos com a nossa expert da área de dados, Sthefanie Monica. Vamos lá?
Qual foi a maior mudança que você observou na Ciência de Dados ao longo dos anos?
O termo Ciência de Dados, mesmo que usado faz um tempo em artigos acadêmicos, teve uma crescente nos últimos 5 anos.
Acredito que quando o termo começou a ser difundido e colocado em vagas de empresas, não tínhamos tantas informações de como essas pessoas atuariam, como seria o dia a dia da empresa com esse novo funcionário e também muitas vezes era facilmente trocado de papéis com outras pessoas de dados, que ainda não tínhamos ideia de nomes e classificações de tarefas.
Sinto que realmente a maior mudança na área de dados foi essa divisão do que um cientista de dados deve e pode fazer e também o que é tarefa de engenheiros de dados e machine learning, por exemplo.
Há algum marco histórico ou avanço tecnológico específico que você acredita ter sido um ponto de virada para a Ciência de Dados?
Considero que existem dois marcos gigantes para a Ciência de Dados: a pandemia e o ChatGPT.
O primeiro deles, a pandemia que tivemos no início do ano 2020 fez com que todos ficassem dentro de casa, trabalhando home office e muitas empresas ainda não sabiam como lidar com a situação.
No entanto, as empresas de tecnologia decolaram, já que o trabalho de uma pessoa programadora pode ser feito em casa utilizando um computador.
Com todas as pessoas em casa, sem ver os amigos pessoalmente e sem fazer tarefas do dia a dia fora de casa, abriu-se uma porta para os estudos e a área tech foi o alvo, já que milhares de empresas dessa área estavam abrindo diversas novas vagas.
Tudo voltou-se para análise de dados: entender as estatísticas de doenças que passavam na televisão, vagas remotas para cientistas de dados e demais áreas tech, atualizações constantes de redes sociais com notícias, lives, etc. Nesse momento, acredito que a área de dados teve seu destaque especial.
A segunda situação que considero um marco é o lançamento do ChatGPT. De um dia para o outro as pessoas estavam falando sobre ChatGPT, pesquisando informações e montando textos, muitas pessoas para uso pessoal, algumas para testar eficiência das ferramentas lançadas e outras para achar pontos fracos.
Todo o rebuliço que essa IA causou foi intrigante, já que muitas pessoas ficaram com medo de perderem seus empregos, outras pessoas acabaram utilizando sem filtro e ocorreram vazamento de dados de empresas, e mais ainda: as portas para IA generativas estavam abertas.
Ambos os acontecimentos colocaram a área de Ciência de Dados no radar do mundo, onde os olhos estavam voltados com medo e admiração para cada momento seguinte.
O Processo de Data Science
Existem diferentes setores empresariais que fazem uso da Ciência de Dados. Por isso, esse processo pode variar significativamente dependendo do setor e das necessidades da empresa.
No entanto, de maneira geral, esse processo segue uma estrutura que começa com a coleta de dados.
Esta etapa é crucial, pois envolve não apenas a aquisição de dados relevantes, mas também a garantia de sua qualidade e relevância.
Em seguida, vem a fase de limpeza e preparação dos dados, onde os dados brutos são transformados em um formato adequado para análise.
Erros, valores ausentes e inconsistências são tratados nesta etapa para garantir a integridade dos dados.
Nesse sentido, deixo aqui um vídeo da Websérie “Universo Data Science” na qual você pode aprender um pouco mais sobre o processo de Data Science.
Após a preparação, segue-se a análise dos dados. Aqui, técnicas estatísticas e algoritmos de aprendizado de máquina são aplicados para extrair padrões, insights e correlações.
Nesta fase podemos ter de análises descritivas simples a modelos preditivos complexos, dependendo do objetivo do projeto.
A visualização de dados também desempenha um papel crucial nesta etapa, ajudando a transformar os resultados complexos em formatos compreensíveis e acionáveis.
Finalmente, a interpretação dos dados é o momento em que os insights aparecem em decisões ou ações.
Esta etapa requer não apenas habilidades técnicas, mas também um profundo entendimento do contexto de negócios.
Sobre isso, deixo como recomendação a escuta do excelente podcast Hipsters.tech na qual o CEO da Alura, Paulo Silveira, e a nossa instrutora da escola de dados da Alura, Valquíria Alencar, comentam sobre a importância do storytelling na apresentação dos dados
Ou seja, da capacidade de “contar uma história” ou passar adiante uma informação clara e interessante quando estamos criando exibições de análises de dados.
Perguntas e respostas para Sthe Monica, Cientista de Dados Sênior na Heineken
Poderia nos dar um exemplo concreto de um projeto de Data Science que você trabalhou, destacando as etapas do processo?
Os meus projetos favoritos envolvem imagens, que têm processos um pouco diferentes dos utilizados em dados tabulares, mesmo que os nomes de etapas sejam as mesmas: limpeza de dados, decisão de manter ou retirar outliers, aumentar dados caso a amostra seja pequena, etc.
Porém um dos projetos que já trabalhei envolvendo dados que não eram imagens foi um no qual fiz um artigo no começo da minha carreira na área de ciência de dados, onde o objetivo era prever o número de manchas solares dos próximos dias com base em observações dos dias anteriores.
A base de dados do projeto foi feita a mão, utilizando coleta de dados online (web scraping) e depois foi feita a limpeza de dados.
Entender quais variáveis utilizamos no projeto também foi uma tarefa importante, já que era necessário realmente entender quais colunas tínhamos que trariam um resultado melhor na previsão, quais dados afetam o surgimento das manchas solares, etc.
Depois de decidir quais colunas manteríamos, outra parte importante foi a identificação dos outliers, mesmo depois de feita a limpeza dos dados, já que muitas vezes os removemos sem entender quais são os impactos em uma predição.
Depois das etapas iniciais, passamos para o modelo de regressão. Nesse momento é importante testar pelo menos dois modelos diferentes e entender quais são seus pontos altos, como tempo de processamento e eficácia dos resultados.
Portanto, a seleção do modelo ideal envolve uma análise cuidadosa dos resultados, requerendo uma interpretação detalhada dos dados para transformar valores numéricos em insights concretos que fundamentam a conclusão.
Na sua experiência, qual etapa do processo de Data Science é frequentemente subestimada ou negligenciada, mas é crucial para o sucesso do projeto?
A parte de entender quais são as variáveis no projeto e escolhê-las. Muitas vezes usamos variáveis com alta correlação que não fazem sentido no projeto final por estarem carregando informações muito próximas ou duplicadas.
O mesmo acontece quando usamos variáveis que não tem sentido nenhum com o problema e não tem um resultado efetivo quando temos um modelo estatístico ou de machine learning.
É a parte mais complexa de ser feita porque demora um tempo, junto com a limpeza dos dados e traz uma responsabilidade grande de entender qual é a situação problema e onde queremos chegar com o resultado, ou seja, conhecer totalmente o escopo que está sendo trabalhado.
Ferramentas e tecnologias de Data Science
Como você já deve ter reparado, a base da Ciência de Dados envolve conhecimento em análise de dados, matemática e estatística.
Porém, para aplicar todo esse conhecimento quem trabalha com Ciência de Dados usa ferramentas específicas. As tecnologias utilizadas variam de empresa para empresa.
Algumas empresas podem centralizar o processo de análise de dados em softwares como o Excel ou Google Planilhas.
Porém, em empresas que já maturaram seus setores de dados é comum que os Cientistas de Dados utilizem linguagens de programação a fim de implementar as últimas tecnologias e soluções dedicadas para essas empresas.
As duas linguagens mais utilizadas são a Python e a R.
Esse gráfico compara a popularidade das duas linguagens. O único ponto de atenção aqui é que a linguagem Python é também muito utilizada em outras aplicações não necessariamente ligadas a dados, como desenvolvimento back-end e desktop.
Porém, as duas possuem uma extensa gama de bibliotecas sendo capazes de suprir todas as necessidades na Ciência de Dados.
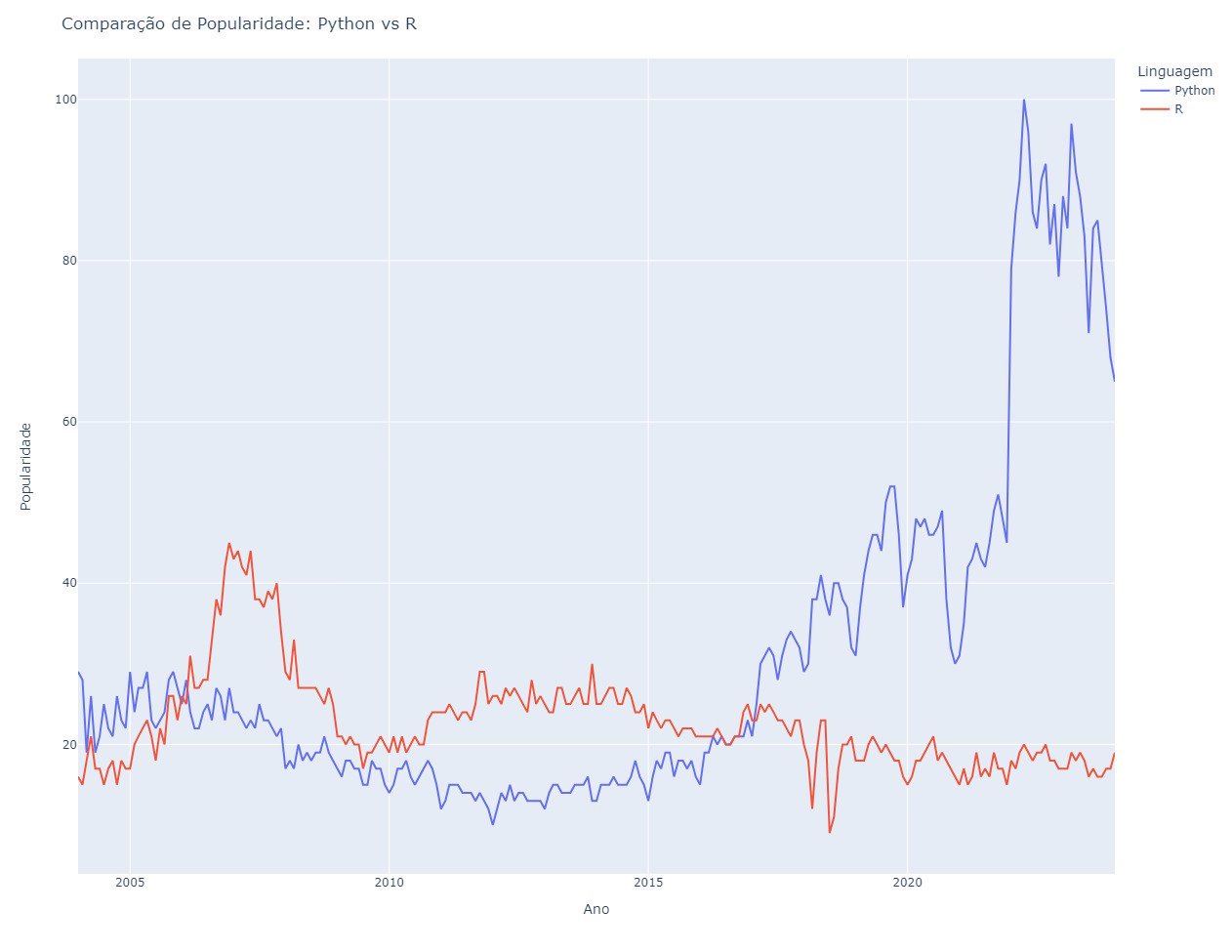
Fonte: Google Trends
Além dessas linguagens de programação é essencial o domínio de bancos de dados SQL e NoSQL.
A organização, recuperação e manipulação eficiente dos dados faz parte do processo diário nessa carreira.
Quando estamos lidando com grandes volumes de dados se torna necessário conhecer ferramentas como Hadoop e Spark. Essas ferramentas permitem a manipulação dos dados de maneira otimizada.
Retomando a questão das linguagens, na Ciência de Dados você não irá implementar soluções do zero.
Toda a parte de análise, cálculos estatísticos e visualização de dados se dá por meio das bibliotecas disponíveis para cada uma dessas linguagens.
Na linguagem Python a biblioteca mais popular para a análise e tratamento de dados é a Pandas. Na etapa de visualização são utilizadas bibliotecas como a Matplotlib e a Seaborn.
Outro aspecto importante é a criação de soluções a partir dos dados. Isso envolve a habilidade de implementar modelos de machine learning.
Os modelos de machine learning permitem a generalização das informações a partir de uma base de dados.
Por exemplo, um modelo de machine learning pode prever a demanda futura de produtos em um supermercado com base nos padrões de compra passados.
As bibliotecas mais famosas que envolvem Machine Learning são a scikit-learn, TensorFlow e PyTorch.
Por fim, a necessidade de coletar grandes volumes de dados, analisá-los e implantar soluções a partir desses dados faz com que o conhecimento de plataformas de nuvem se torne cada vez mais necessário.
Plataformas como a Microsoft Azure, Google Cloud e AWS permitem que todo esse processo seja feito de maneira inteligente e integrada dentro de um mesmo fluxo.
Pode não ser exatamente o Cientista de Dados que irá implementar todo esse processo, mas o conhecimento é importante já que diferentes profissionais de dados podem ter que interagir de forma contínua.
Perguntas e respostas para Sthe Monica, Cientista de Dados Sênior na Heineken
Quais ferramentas ou bibliotecas você considera indispensáveis para quem está começando em Data Science?
As primeiras bibliotecas que recomendo são: Pandas e Numpy.
Com essas bibliotecas você consegue fazer manipulações em tabelas, operações matemáticas, estatísticas e o básico da ciência de dados.
Outra biblioteca que considero importante é a Matplotlib, para a visualização de dados.
Com essa biblioteca você pode fazer gráficos e visualizações dos dados, ver como eles estão distribuídos, identificar outliers e também torna o trabalho de avaliação de modelos mais fácil.
Ainda em bibliotecas, se você quer aprender mais sobre machine learning e demais modelos estatísticos, a Scikit-learning é a biblioteca ideal para aprender e reforçar conhecimentos.
Outra recomendação para quem está começando é se habituar com códigos em células, e um ótimo companheiro para essa primeira jornada é o Google Colab, que é um ambiente de notebook baseado em nuvem que facilita a escrita e execução de código Python através do navegador, sem necessidade de configuração prévia.
No começo pode ser que todos os nomes sejam estranhos, mas eles nos ajudam em diversos campos da vida de cientista de dados!
Aplicações práticas de Data Science
A Ciência de Dados é utilizada em diferentes áreas de uma empresa e também em empresas de diferentes setores.
Por isso, fica difícil pensar em algo que resuma toda a atuação de um Cientista de Dados. Alguns exemplos, que podem ser citados são:
- Análise de Tendências de Mercado em Empresas de Varejo: Utilizando dados de vendas para prever tendências futuras e otimizar o estoque.
- Desenvolvimento de Sistemas de Recomendação em Plataformas Online: Como os sistemas usados por empresas como Netflix e Amazon para recomendar produtos ou conteúdos.
- Detecção de Fraude em Instituições Financeiras: Analisando padrões de transações para identificar atividades suspeitas em tempo real.
- Otimização da Cadeia de Suprimentos em Logística: Analisando e prevendo os melhores caminhos e métodos para transporte e distribuição de produtos.
- Análise de Dados no Setor de Saúde: Para melhorar os tratamentos e a eficiência dos serviços de saúde.
Perguntas e respostas para Sthe Monica, Cientista de Dados Sênior na Heineken
Você poderia compartilhar um tipo específico de problema que você trabalhou como Cientista de Dados?
Já trabalhei como cientista de dados em algumas empresas diferentes e com problemas diferentes. Os problemas que enfrentamos no dia a dia acabam se parecendo muito com os que estudamos.
Durante o final dos meus anos de universidade, meu TCC envolveu análises de imagens de pulmão para dizer se tinha ou não COVID presente no raio-x.
Um tempo depois comecei a trabalhar em um projeto dentro do Hospital Israelita Albert Einstein e meus conhecimentos de análise de imagem médica foram postos à prova em um projeto voltado para o SUS, realizando análises de imagens de tomografias cranianas para detecção de AVC ou problemas similares.
Hoje em dia trabalho na Heineken Brasil, uma das maiores indústrias do mundo no ramo de cervejas e bebidas, e no dia a dia trabalhamos com projetos de RH e demais áreas como finanças, logística e projetos voltados para a cervejaria - parte industrial.
Todos esses desafios encontrados no dia a dia podem ser treinados com diversos outros cases que vemos no Kaggle por exemplo, por isso é muito importante a parte do estudo de problemas baseados na realidade e também o desenvolvimento desde a análise prévia dos dados até o storytelling completo.
Desafios e considerações éticas na área de Ciência de Dados
Na ciência de dados, os desafios vão além das complexidades técnicas e se estendem às considerações éticas e sociais.
Um dos principais desafios e pontos necessários para o aprendizado é a questão da privacidade e segurança dos dados.
Com o aumento do volume de dados coletados por empresas e organizações, a proteção de informações sensíveis se tornou crítica.
Isso envolve não apenas a implementação de medidas de segurança robustas, mas também a garantia de que a coleta e uso dos dados estejam em conformidade com as leis de privacidade, como o GDPR na Europa e a LGPD no Brasil.
Além disso, há o desafio de evitar vieses nos dados, que podem levar a resultados discriminatórios.
Por exemplo, se um conjunto de dados de treinamento para um algoritmo de machine learning não for diversificado ou representativo, o modelo resultante pode perpetuar ou até amplificar preconceitos existentes, levando a decisões injustas ou tendenciosas.
Nesse sentido, recomendo o curso
Outra consideração ética importante na ciência de dados é a transparência e explicabilidade dos modelos.
À medida que os algoritmos de machine learning e inteligência artificial se tornam mais complexos, surge a necessidade de garantir que suas decisões sejam compreensíveis e explicáveis.
Isso é crucial, especialmente em setores como saúde e justiça, onde decisões baseadas em dados podem ter consequências significativas na vida das pessoas.
Além disso, os Cientistas de Dados devem estar cientes do impacto social e ambiental de seus trabalhos.
Por exemplo, o treinamento de modelos de deep learning em grande escala consome uma quantidade significativa de recursos computacionais e, consequentemente, energia, levantando questões sobre a sustentabilidade dessas práticas.
Perguntas e respostas para Sthe Monica, Cientista de Dados Sênior na Heineken
Na sua carreira profissional você já teve que lidar com dados sensíveis ou houveram considerações éticas no tratamento de dados?
Em todos os trabalhos que eu tive como cientista de dados precisei lidar com dados sensíveis e é realmente algo muito importante para as organizações que as pessoas sejam totalmente confiáveis e assinem termos de compromisso quando começam um projeto que envolve dados sensíveis.
Obviamente na área de fraudes todos os dados são extremamente sensíveis, já que todos os dados de cadastro da pessoa, fotos e números de documentos, conta do banco, dentre outros dados, estão a disposição para a análise total de dados, ou seja, as pessoas que trabalham com essa área precisam ter um cuidado redobrado.
Dentro da área da saúde também é importante que a LGPD seja aplicada, já que estamos usando dados médicos da pessoa e isso pode ser um grande problema se for usado por mãos erradas, ninguém quer que pessoas sofram consequências sobre sua vida profissional por conta da vida privada/saúde, por exemplo.
Antes das imagens serem analisadas no projeto no qual eu estava, elas passavam por um processo de anonimização, ou seja, os dados da pessoa eram retirados da imagem do exame e dos metadados (variáveis que armazenam dados gerais, como nome da pessoa, máquina que foi usada, profissional que aplicou o exame, laudo médico, etc).
Dentro da Heineken quando uma pessoa cientista de dados está fazendo um projeto que envolva dados de RH por exemplo, é necessário utilizar um ambiente diferente do usado no dia a dia por outras pessoas com demais informações, já que as tabelas de RH podem conter dados pessoais sensíveis, onde mora, quanto recebe, entre outras informações.
Carreira em Data Science
O mercado de trabalho em Ciência de Dados está em constante mudança. A cada momento ocorre o desmembramento da área de dados em novas carreiras, surgem novas aplicações e ferramentas. Tudo isso, torna difícil a atualização dos profissionais.
A tendência é que cada vez mais os profissionais se especializem em determinadas tecnologias. No relatório de 2023 do fórum econômico mundial sobre o futuro dos empregos a área de Big-data analytics aparece como no topo das áreas com potencial de geração de empregos até 2027.
Vou deixar um vídeo bem bacana sobre carreira em dados na qual você pode se inspirar um pouco mais e quem sabe até fazer sua transição de carreira para a área de dados
Uma forma de lidar com esse oceano de possibilidades é tentando construir uma base sólida de conhecimento.
As linguagens, bibliotecas e ferramentas disponíveis mudam rapidamente, mas a matemática, estatística e conhecimento sobre as possibilidades de análise de dados não.
Para facilitar a sua jornada nos estudos sobre Ciência de Dados a Alura desenvolveu um Tech Guide contendo um mapeamento dos principais tópicos demandados pelo mercado.
Falando dos salários e vagas em uma pesquisa no site Vagas.com a média salarial para Cientistas de Dados é de R$ 6.144,00.
Já no site Glassdoor.com a média dos salários informados no site é igual a R$ 15.092,00.
Na primeira edição do Concurso Nacional Unificado também tivemos vagas para Cientistas de Dados.
Com vagas que exigem formação superior em qualquer área do conhecimento. Concursos são uma ótima opção para quem está começando e não possui experiência.
Já para quem está focando no mercado de trabalho de empresas privadas o processo de conquista da primeira vaga é mais tortuoso e é baseado em uma construção através de cursos, faculdade e portfólio.
Perguntas e respostas para Sthe Monica, Cientista de Dados Sênior na Heineken
Você considera que elementos como o portfólio, certificados e certificações ajudam na busca por vagas em Ciência de Dados? O que ajuda mais?
Acredito que ajudam sim! Obviamente certificados têm uma grande importância para provar que você assistiu aulas e fez exercícios para aprender os conteúdos, porém quando você cria um portfólio e aplica em projetos que tem muito a ver com a realidade dentro das empresas e mostra que seu conhecimento de cursos foi avaliado e comprovado, as pessoas tendem a olhar com maior carinho.
Sinto que portfolios trazem uma proximidade maior com as empresas e tech recruiters realmente por trazer pontos que são pertinentes sobre como você desenvolve um projeto, como conta a história dele, transmitindo a informação de forma clara para pessoas técnicas e não técnicas, e também permite que a pessoa analise como você faz toda a programação, validando seus conhecimentos técnicos.
Certificações são altamente recomendadas depois de um tempo atuando como cientista de dados, já que quando você está no início da sua carreira, o principal é aprender com projetos e criar um portfólio. Quando você se sentir confortável com as tecnologias utilizadas e quiser fazer uma certificação, vá em frente!
Como você acha que o papel do cientista de dados vai mudar no futuro?
Depois de alguns acontecimentos globais como a pandemia e o lançamento do ChatGPT, que falei anteriormente, o papel de cientista de dados começou a mudar e ter um perfil muito grande de não somente produzir análises e modelos de machine learning, mas aprender a escrever prompts para IAs generativas e identificar se as informações são verídicas ou não.
Imagino que em um futuro breve teremos muitos cientistas aplicados na explicabilidade e interpretabilidade de IAs, para entender porque escolheram os caminhos que levaram ao resultado final e como isso afeta os problemas que estamos solucionando com essas tecnologias.
Outro ponto que acredito que será forte é a análise de maior número de dados, ou seja, a computação paralela (como o Spark) terá um ponto ainda maior do que temos atualmente para conseguir suprir a demanda.
Por fim, acredito que pode existir mais uma divisão de áreas, como aconteceu com a ciência de dados e engenharia de dados e engenharia de machine learning. Ou seja, pessoas que estão focadas em espaços menores ainda da pipeline do projeto de dados.
Conclusão
Em conclusão, a Ciência de Dados representa uma das áreas mais interessantes e em crescimento no panorama tecnológico atual.
Com suas raízes fincadas em disciplinas clássicas como estatística e matemática, e evoluindo para incorporar avanços em inteligência artificial e computação em nuvem, a Ciência de Dados está se tornando cada vez mais essencial para a tomada de decisões informadas em todos os setores da economia.
Para profissionais que desejam ingressar ou se aprofundar nesta área, o caminho envolve um compromisso contínuo com o aprendizado e a adaptação às novas tecnologias e métodos emergentes.
O futuro da Ciência de Dados promete ser ainda mais integrado, com uma ênfase crescente na ética e na responsabilidade social, refletindo sua importância fundamental na moldagem de um futuro orientado por dados.
Se você deseja mergulhar ainda mais nos conteúdos de Ciência de Dados, aqui na Alura nós temos a Formação de Data Science.
A formação aborda as principais ferramentas utilizadas em Ciência de Dados, incluindo Pandas, Matplotlib, Statsmodels, Scikit-learn, e muito mais.
Durante a formação, construímos vários projetos práticos para enriquecer o seu portfólio como profissional de dados.
Confira a formação de data science no seguinte link: Formação de Data Science.
Sthefanie, se você pudesse dar um conselho para alguém que está começando em Data Science, qual seria?
O primeiro conselho é: faça cursos e entenda realmente o que as métricas estão mostrando no problema, quais são as partes importantes para manter nos dados, nas análises e também de modelos de machine learning usados.
O segundo conselho consiste em colocar a mão na massa: faça projetos!
Sites como o Kaggle contém diversas bases de dados, competições, cases resolvidos e você pode aproveitar para aprender sobre novos temas enquanto faz suas análises, garanto que será um processo rico em aprendizado.
Além de ser ótimo fazer projetos, criar um portfólio completo, se conectar com pessoas e soluções diferentes para os mesmos problemas, entre outros, faz com que você se sinta cada vez mais preparado para o mundo de trabalho.
O terceiro e não menos importante conselho: procure uma comunidade para compartilhar problemas, para trocar sobre projetos e também sobre estudos. Estar cercado de pessoas com objetivos semelhantes faz com que o percurso seja melhor e mais prazeroso.
Créditos
- Conteúdo: Allan Segovia Spadini
- Produção técnica: Rodrigo Fernando Dias
- Produção didática: Tiago de Freitas
- Designer gráfico: Alysson Manso