Normalização: o que é, para que serve e como usá-la
8 min8 minutos de leitura
8 min8 minutos de leitura
Na modelagem de dados, é muito importante representarmos com precisão a estrutura e as relações entre os diferentes elementos de um sistema.
Autor(a)
Beatriz Magalhães
Beatriz é formada em Análise e Desenvolvimento de Sistemas. Faz parte do time de instrutores na escola de Data Science, tem focado seus estudos na área de banco de dados, SQL e Business Intelligence e ama explorar diferentes softwares de visualização de dados. É muito curiosa e adora aprender coisas novas e compartilhar com outras pessoas.
Inscreva-se em nossa Newsletter
Fique por dentro de conteúdos, insights e oportunidades do universo tech. Receba novidades e lançamentos direto no seu e-mail.
No entanto, durante esse processo, é comum surgirem anomalias no banco de dados, que são inconsistências ou problemas que afetam a integridade e a qualidade dos dados armazenados.
Nesse sentido, neste artigo, vamos conhecer os principais tipos de anomalias e também a importância do processo de normalização dos dados através da aplicação das chamadas formais normais, que visam garantir uma estruturação eficaz e livre de redundâncias em nosso banco de dados.
Vamos lá?
Quais são os tipos de anomalias
Como dito na introdução, existem vários tipos de anomalias nos dados que podem surgir em um banco de dados devido a falhas na estruturação ou manipulação inadequada dos dados.
Vamos conhecer os principais tipos de anomalias:
Anomalias de Inserção
Ocorrem quando é difícil ou impossível inserir novos dados no banco de dados devido a restrições de integridade ou inconsistências na estrutura da tabela.
Anomalias de Atualização
Surgem quando uma atualização de dados em uma tabela resulta em inconsistências ou valores indesejados em outras partes do banco de dados.
Anomalias de Exclusão
Acontecem quando a exclusão de dados de uma tabela resulta em perda de informações importantes ou em referências inválidas em outras partes do banco de dados.
Redundância de Dados
Ocorre quando os mesmos dados são armazenados em múltiplos locais, o que pode levar ao desperdício de espaço de armazenamento e dificuldades de manutenção.
Dependências Funcionais Indesejadas
Acontecem quando as relações entre os dados não são adequadamente definidas, resultando em dependências funcionais não intencionais ou ambíguas.
Inconsistências de Dados
Surgem quando os dados em uma tabela estão desatualizados, contraditórios ou em conflito com os dados em outras partes do banco de dados.
Dependências Multivaloradas
Ocorrem quando um conjunto de atributos não chave determina um conjunto de valores diferentes para outro conjunto de atributos, resultando em redundâncias e dificuldades de atualização.
Anomalias de Junção
Acontecem quando a junção de tabelas resulta em informações incorretas ou incompletas devido à forma como as tabelas foram estruturadas ou relacionadas.
O surgimento dessas anomalias são comuns, porém a permanência de qualquer uma delas no nosso banco de dados pode gerar grandes problemas na confiabilidade dos nossos dados, por esse motivo existe o processo de normalização.
Para quê serve a normalização de dados?
Importante dizer que a normalização dos dados será responsável por organizar as tabelas de um banco de dados de forma a reduzir redundâncias e evitar as anomalias de atualização e exclusão.
Sendo assim, ela é realizada através da aplicação de uma série de regras chamadas de formas normais, que garantem a estruturação eficiente e livre de redundâncias das tabelas.
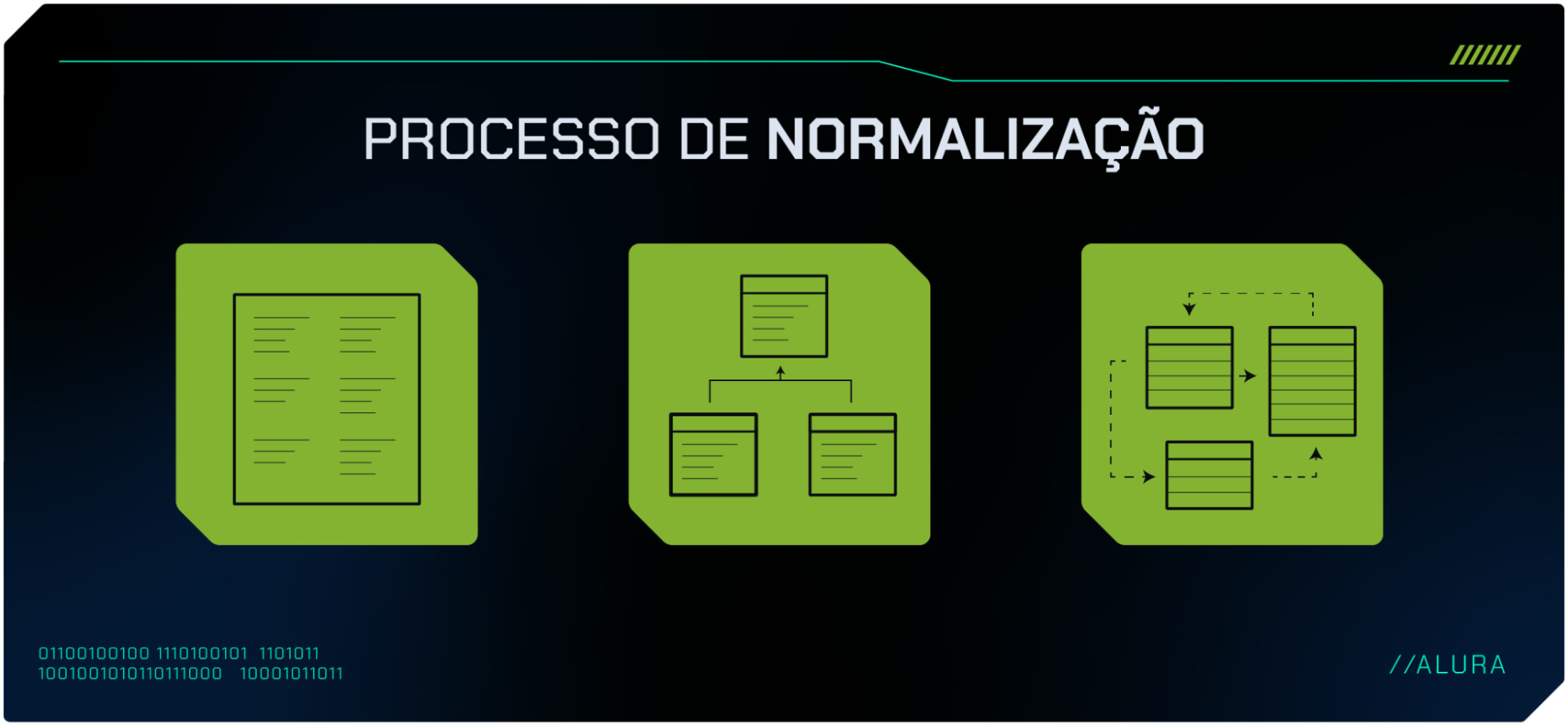
O processo de normalização geralmente envolve dividir as tabelas grandes em múltiplas tabelas menores e mais especializadas, conectadas por meio de relacionamentos.
Isso ajuda a minimizar o espaço de armazenamento necessário, melhorar a integridade dos dados e facilitar a manutenção e a consulta dos dados.
Regras de normalização de dados
Falando um pouco sobre as formas normais, existem várias dessas regras para garantir o sucesso da estruturação do nosso banco de dados.
Porém três delas são as mais utilizadas na normalização:
Primeira Forma Normal (1NF)
Em 1NF, cada célula de uma tabela deve conter um único valor atômico, ou seja, não pode conter valores compostos ou repetidos.
Por exemplo, vamos supor que temos uma tabela de alunos com colunas para ID do aluno, nome e lista de disciplinas cursadas.
Para aplicar a 1NF, devemos separar a lista de disciplinas em uma tabela separada de modo que cada linha representa um único aluno e uma única disciplina, como mostrado abaixo:
Tabela antes de aplicarmos a 1FN:
Tabela Alunos
ID Aluno
Nome
Disciplinas Cursadas
1
João
Matemática, História
2
Maria
Ciências, Inglês
Tabelas após a aplicação da 1FN:
Tabela Alunos
ID Aluno
Nome
1
João
2
Maria
Tabela Disciplinas
ID Aluno
Disciplina
1
Matemática
1
História
2
Ciências
2
Inglês
Segunda Forma Normal (2NF)
Em 2NF, uma tabela deve estar na 1NF e todos os seus atributos não chave devem depender completamente da chave primária.
Continuando com o exemplo anterior, vamos imaginar que agora temos uma tabela de inscrições que relaciona alunos e disciplinas com suas notas.
Para aplicar a 2NF, devemos dividir esta tabela em duas: uma para as inscrições, relacionando aluno e disciplina, e outra para as notas:
Tabela antes de aplicarmos a 2FN:
Tabela Inscrições
ID Inscrição
ID Aluno
Nome Aluno
ID Disciplina
Disciplina
Nota
1
1
João
1
Matemática
8,5
2
1
João
2
História
9
3
2
Maria
3
Ciências
7,5
4
2
Maria
4
Inglês
10
Tabelas após a aplicação da 2FN:
Tabela Inscrições
ID Inscrição
ID Aluno
ID Disciplina
1
1
1
2
1
2
3
2
3
4
2
4
Tabela Notas
ID Inscrição
Nota
1
8,5
2
9
3
7,5
4
10
Agora, cada tabela possui uma responsabilidade única: a tabela de inscrições registra quais alunos estão inscritos em quais disciplinas, enquanto a tabela de notas registra as notas associadas a essas inscrições.
Isso garante que não haja dependência transitiva entre os atributos, satisfazendo a segunda forma normal (2NF).
Terceira Forma Normal (3NF)
Em 3NF, uma tabela deve estar na 2NF e todos os seus atributos não chave devem depender apenas da chave primária, não de outros atributos não chave.
Considerando a tabela de inscrições do exemplo anterior, se houver um atributo "nome do professor" associado à disciplina, que não depende do aluno, então devemos criar uma tabela separada para armazenar informações sobre a disciplina, incluindo o nome do professor.
Tabela Inscrições após aplicarmos a 3NF
Tabela alunos
ID Aluno
Nome
1
João
2
Maria
Tabela Disciplinas
ID Disciplina
Disciplina
Nome Professor
1
Matemática
Prof. Silva
2
História
Prof. Alice
3
Ciências
Prof. César
4
Inglês
Profª Joana
Tabela Inscrições
ID Inscrição
ID Aluno
ID Disciplina
Nota
1
1
1
8,5
2
1
2
9
3
2
3
7,5
4
2
4
10
Além dessas 3 formas normais principais, temos a Quarta Forma Normal (4NF) e a Quinta Forma Normal (5NF), que são extensões das formas normais anteriores (1NF, 2NF e 3NF).
Quarta Forma Normal (4NF)
A 4NF é uma extensão da 3NF que trata de eliminar dependências multivaloradas. Ela assegura que uma tabela não tenha conjuntos de atributos multivalorados que dependam de uma mesma chave primária.
Isso é alcançado dividindo-se a tabela em múltiplas tabelas menores para representar adequadamente as dependências multivaloradas.
Por exemplo, se tivermos uma tabela de clientes com atributos como nome, telefone e uma lista de produtos de interesse, a 4NF exigiria a criação de uma tabela separada para representar os produtos de interesse, evitando assim redundâncias na lista de produtos.
Quinta Forma Normal (5NF)
A 5NF é uma forma normal menos comum e mais abstrata, que lida com dependências de junção.
Ela busca eliminar anomalias de junção, garantindo que as tabelas estejam estruturadas de modo a não induzir informações incorretas durante a junção.
Imagine uma tabela que armazena informações sobre cursos e professores. A 5NF exigiria que os cursos e os professores fossem separados em tabelas distintas para evitar que as informações sobre os cursos afetassem inadvertidamente os dados dos professores durante a junção.
Além disso, existe a Forma Normal de Boyce-Codd (FNBC ou BCNF), ela é uma forma normal mais rigorosa que a 3NF, que lida especificamente com dependências funcionais não triviais.
Em outras palavras, todas as dependências funcionais não triviais em uma tabela devem ser determinadas por chaves candidatas. A BCNF é uma forma normal mais forte que a 3NF e, em muitos casos, tabelas que atendem à 3NF também atendem à BCNF.
No entanto, existem situações em que a BCNF pode exigir uma divisão adicional das tabelas para eliminar dependências funcionais não triviais.
Conclusão
Neste artigo, conseguimos então ter uma visão geral sobre o que é o processo de normalização e a sua importância na criação de estruturas de banco de dados eficientes e livres de anomalias.
Durante a leitura, fomos capazes de:
Compreender os principais tipos de anomalias dentro de um banco de dados
Reconhecer a importância das aplicações das formas normais
Bacana né? Esse foi apenas um de diversos conteúdos sobre Modelagem de Dados apresentados na plataforma da Alura.
Um abraço e nos vemos nos cursos da formação Modelagem de Dados da Alura.