



Quando estamos trabalhando com dados utilizando a biblioteca Pandas do Python, principalmente na fase de mineração e preparação, é comum termos que remover colunas e linhas de DataFrames para ajustar nossos conjuntos de dados. Essas operações são feitas com métodos como o drop do Pandas
Muitas vezes, precisamos excluir coluna no Pandas ('remover coluna pandas') para eliminar informações desnecessárias, ou até mesmo remover linhas que contêm dados inválidos.
Mas, afinal, ter mais dados não seria sempre melhor?
Quando estamos analisando dados, principalmente para treinar modelos de inteligência artificial, alguns dados podem prejudicar ao invés de ajudar. Por isso, temos que utilizar apenas os dados que fazem sentido para o modelo.
Legal! Já sabemos que precisamos tratar os dados, mas como podemos utilizar o método drop do Pandas para remover colunas ou linhas de um DataFrame na prática?
Como remover coluna no Pandas com o método drop?
Neste exemplo, vamos analisar dados de gorjetas em transportes como táxis, utilizando a biblioteca Pandas, que facilita a manipulação de conjuntos de dados.
No Pandas, trabalhamos principalmente com o tipo de dado chamado DataFrame, que pode ser comparado a uma planilha, com linhas (observações) e colunas (variáveis).
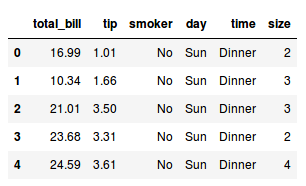
Para visualizar as primeiras linhas do DataFrame, podemos utilizar o método head():
tips.head() # Verificando se a coluna foi realmente removida" 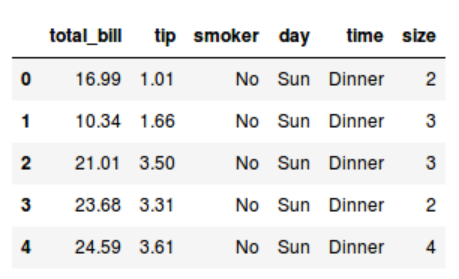
Podemos ver que o DataFrame lembra muito uma planilha. Cada coluna, também chamada de variável, possui um nome, enquanto cada linha, chamada de observação, tem um índice e os valores correspondentes a cada variável.
Para a análise que eu quero fazer, não preciso saber se as pessoas são fumantes ou não, por isso, não faz necessário analisar a coluna No contexto desta análise, a coluna 'smoker', que informa se a pessoa é fumante ou não, não é necessária. Como podemos removê-la do DataFrame?
A primeira etapa é excluir a coluna 'smoker', pois ela não é relevante para a análise. Para isso, utilizamos um método do Pandas próprio para esse fim
No Pandas, existe o método drop (pandas drop) para DataFrames. Com esse método, conseguimos tanto remover colunas (drop column pandas) quanto linhas, passando os parâmetros corretos:
>>> # no interpretador
>>> tips.drop(2)No exemplo acima, removemos a linha de índice 2. Mas como queremos remover uma coluna, precisamos utilizar o parâmetro columns, que recebe uma lista com o nome das colunas a serem removidas, como 'smoker' neste caso.
Após isso, vamos falar para o Pandas nos mostrar o cabeçalho desse data frame:
tips.drop(columns=['smoker'])
tips.head()Você deve ter notado que a coluna ainda aparece. O que aconteceu?
Por padrão, operações como remoção de colunas ou linhas em um DataFrame não alteram o objeto original. Ou seja, ao realizar essas operações, o Pandas retorna um novo DataFrame com as alterações, mantendo o original inalterado.
Para aplicar a alteração de forma definitiva, basta atribuir o resultado retornado pelo método à mesma variável:
tips = tips.drop(columns=['smoker'])
tips.head()Pronto! Agora que removemos a coluna desejada, vamos avançar para outra etapa importante no tratamento dos dados.
Como podemos remover as linhas que não atendem a essa condição específica?

Como remover linhas no Pandas usando o método drop e filtragem
Sabemos que podemos utilizar o método drop() para remover uma linha específica. Mas como podemos eliminar todas as linhas em que há apenas um passageiro?
Uma solução possível seria utilizar um loop para verificar cada linha do DataFrame e checar se o número de passageiros é maior que um. Se sim, mantemos a linha; caso contrário, removemos. No entanto, essa abordagem não é eficiente
Mas o Pandas já tem diversas formas para trabalhar com seus data frames. O que podemos fazer é criar um filtro (também conhecido como boolean indexing ou máscara booleana) no qual é retornado um novo DataFrame com os dados já filtrados. Esta abordagem é eficiente e é a forma recomendada para filtrar dados no Pandas.
O Pandas permite filtrar um DataFrame com base nos valores de suas colunas. Por exemplo, para selecionar apenas as linhas em que o número de passageiros (coluna size) é maior que um:
filtro = tips['size'] > 1 Esse procedimento é muito usado para manter apenas os dados relevantes em DataFrames, especialmente antes de usar funções de análise ou visualização, e também pode ser complementado pelo método drop do Pandas para eliminar linhas individualmente.
filtro = tips['size'] > 1
gorgetas_em_grupo = tips[filtro]Esse filtro retorna um novo DataFrame contendo apenas as linhas em que o número de passageiros é maior que 1.
gorgetas_em_grupo.head() Remover colunas e linhas: maneiras avançadas de usar drop no Pandas
Os filtros podem ser ainda mais complexos, incluindo condições como E (and), OU (or) e verificações envolvendo múltiplas colunas. É possível, por exemplo, combinar critérios para realizar filtragens mais específicas.
Por exemplo, é possível checar se alguma linha possui valores nulos ou valores de tipos diferentes do esperado. Para isso, o Pandas utiliza o conceito de 'comparação rica' (rich comparison), permitindo maior flexibilidade na criação de filtros.
Além de operações de remover colunas e linhas com drop no Pandas, você pode, por exemplo, renomear colunas, adicionar novas, juntar diferentes DataFrames e manipular dados de texto.
Como aprender mais sobre Python e Pandas?
Se você quer dar um passo na sua carreira que te diferencie do mercado, entender profundamente sobre Data Sciente com Python é um dos melhores caminhos.
Aqui na Alura, temos uma trilha de Data Science com Pandas. Nela você verá como manipular data frames de diversas formas. Além de ver como criar gráficos, visualizar estatísticas descritivas, tratar dados faltantes e muito mais.
Avalie este artigo
✨ Agradecemos pela sua avaliação! ✨






