Machine Learning: o que é aprendizado semi-supervisionado


Quando lidamos com um cenário onde a obtenção de dados e variáveis de interesse representam um processo custoso e demorado, precisamos buscar alternativas para aproveitar as informações disponíveis.
O aprendizado semi-supervisionado surge como uma alternativa promissora às abordagens de aprendizado supervisionado e não supervisionado.
Nesse artigo, vamos conhecer o aprendizado de máquina semi-supervisionado, explorando suas aplicações, vantagens e desafios, e desvendando como essa abordagem se diferencia das tradicionais abordagens supervisionadas e não supervisionadas, observando como ela pode ser uma ferramenta valiosa ao se enfrentar problemas com dados limitados.
O que é o aprendizado semi-supervisionado?
A ideia do conceito de supervisão em um modelo de aprendizado diz respeito a saber previamente informações sobre a variável target (alvo) do nosso conjunto de dados, que vai ser posteriormente explorado pelo modelo de aprendizagem.
Por exemplo, se em um determinado grupo de pessoas desejamos saber uma característica específica sobre cada pessoa, como por exemplo, a nacionalidade, podem existir alguns cenários:
- Coletamos informações sobre a característica de nacionalidade de todas as pessoas do grupo e também temos acesso às outras informações, como: nome, endereço, comidas favoritas, e outros.
- Coletamos informações do grupo de pessoas, mas apenas parte dessa amostra possui informações sobre a nacionalidade.
- Não coletamos informações sobre a nacionalidade de cada pessoa, temos acesso apenas às outras informações de cada indivíduo.
As situações acima remetem, respectivamente, às situações de aplicação de: aprendizado supervisionado, aprendizado semi-supervisionado e aprendizado não-supervisionado.
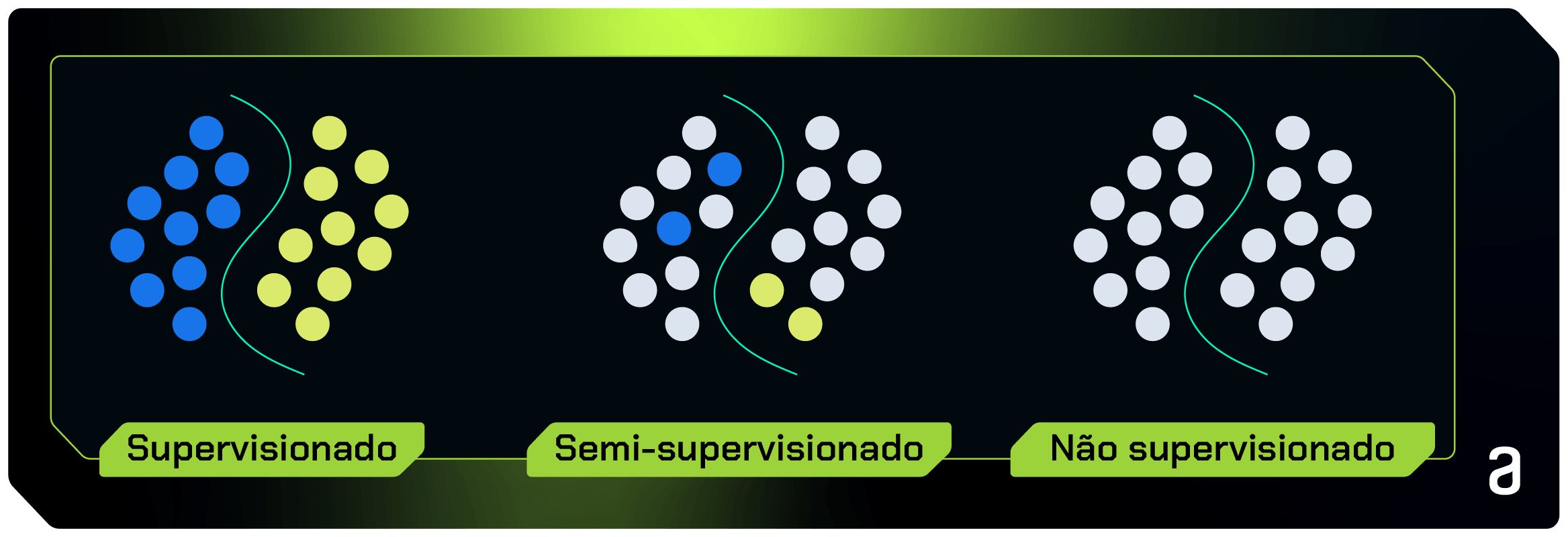
No caso particular do aprendizado semi-supervisionado, o objetivo é trabalhar em um cenário com problemas de rotulação parcial dos dados, onde as informações sobre a variável alvo são poucas.
E a falta desses rótulos pode acontecer tanto por questões financeiras para coleta das informações, quanto também de custos operacionais que também dizem respeito a custo e esforço humano.
Um exemplo simples de situação onde temos dados rotulados parcialmente pode ser observado na seguinte imagem:
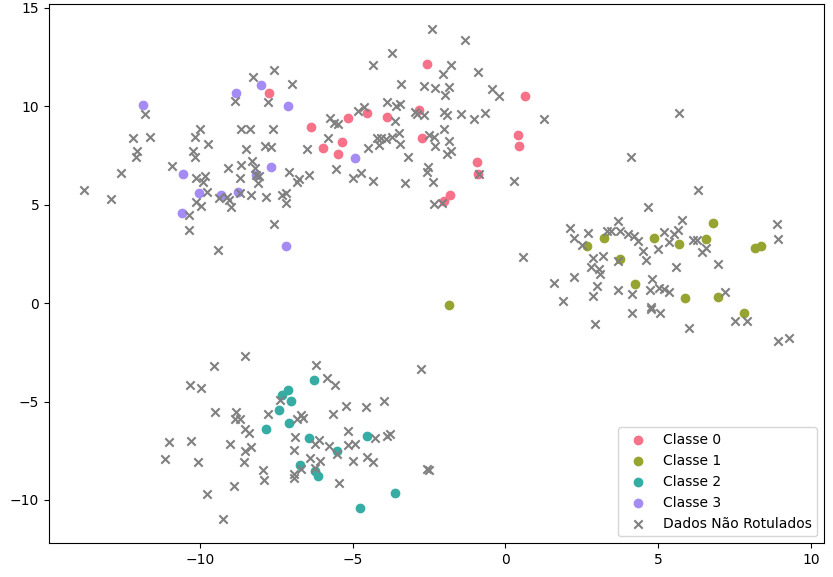
Neste exemplo, temos informações sobre os eixos X e Y para cada ponto, que seriam as suas características (features) no conjunto de dados, mas somente alguns registros possuem informações sobre a classe (o rótulo), que são representadas por quatro cores distintas.
Os pontos não rotulados são representados pelos símbolos “x”, enquanto temos as outras quatro classes espalhadas em clusters (nuvens), onde os pontos semelhantes ficam próximos.
Esse tipo de problema se repete em diversas situações em ciência de dados, inclusive para conjuntos com mais variáveis (maior dimensão).
Contextualização do problema: detecção de fraudes em transações
Imagine que você trabalha em uma instituição financeira e tem um grande conjunto de dados de transações de cartão de crédito. Seu objetivo é detectar atividades fraudulentas, onde transações fraudulentas são aquelas que não foram autorizadas pelo titular do cartão.
Podemos ter um conjunto de transações rotuladas como "fraude" ou "não fraude". Nesse cenário, você poderia usar técnicas de aprendizado supervisionado, como Random Forest, para construir um modelo que aprenda apenas com as transações rotuladas.
O modelo seria treinado usando as características das transações, como valor da transação, localização, horário do dia e etc. para prever se uma transação futura é uma fraude ou não.
No entanto, a rotulação de fraudes é custosa e pode estar ausente na maioria dos dados. Em relação ao volume total de transações, a proporção de fraudes é bem menor, e o custo associado para verificar e investigar fraudes dificulta o processo para validar os rótulos.
Agora, considere que você tem um grande número de transações não rotuladas. Para encontrar padrões e anomalias nessas transações não rotuladas, você pode aplicar técnicas de aprendizado não supervisionado, como algoritmos de agrupamento (por exemplo, K-Means).
Isso pode ajudar a identificar grupos de transações que têm comportamento semelhante e destacar transações que parecem atípicas ou anômalas em relação aos grupos.
E embora seja possível trabalhar descartando todos os rótulos e apenas usando as informações das transações, utilizar técnicas semi-supervisionadas favorecem alguns benefícios:
- Precisão aprimorada: A abordagem semi-supervisionada incorpora dados rotulados para melhor distinguir entre tipos de fraudes, tornando o modelo mais confiável e capaz de identificar nuances sutis.
- Redução de falsos positivos: Incorporar exemplos rotulados ajuda a minimizar os falsos positivos, melhorando a precisão das previsões de fraude.
- Aproveitamento de dados não rotulados: A abordagem semi-supervisionada maximiza o uso de dados não rotulados, útil quando rótulos de fraude são escassos ou caros de obter.
- Adaptação a mudanças: A abordagem semi-supervisionada permite ao modelo se adaptar a padrões de fraude em evolução, aproveitando tanto dados rotulados quanto não rotulados.
- Controle personalizado: Ajustar o uso de dados rotulados e não rotulados oferece maior controle sobre o treinamento do modelo, permitindo uma abordagem personalizada.
Mas, para garantir que podemos utilizar o aprendizado semi-supervisionado com um bom aproveitamento, é necessário seguir alguns critérios.

Premissas para utilizar técnicas de aprendizado semi-supervisionado
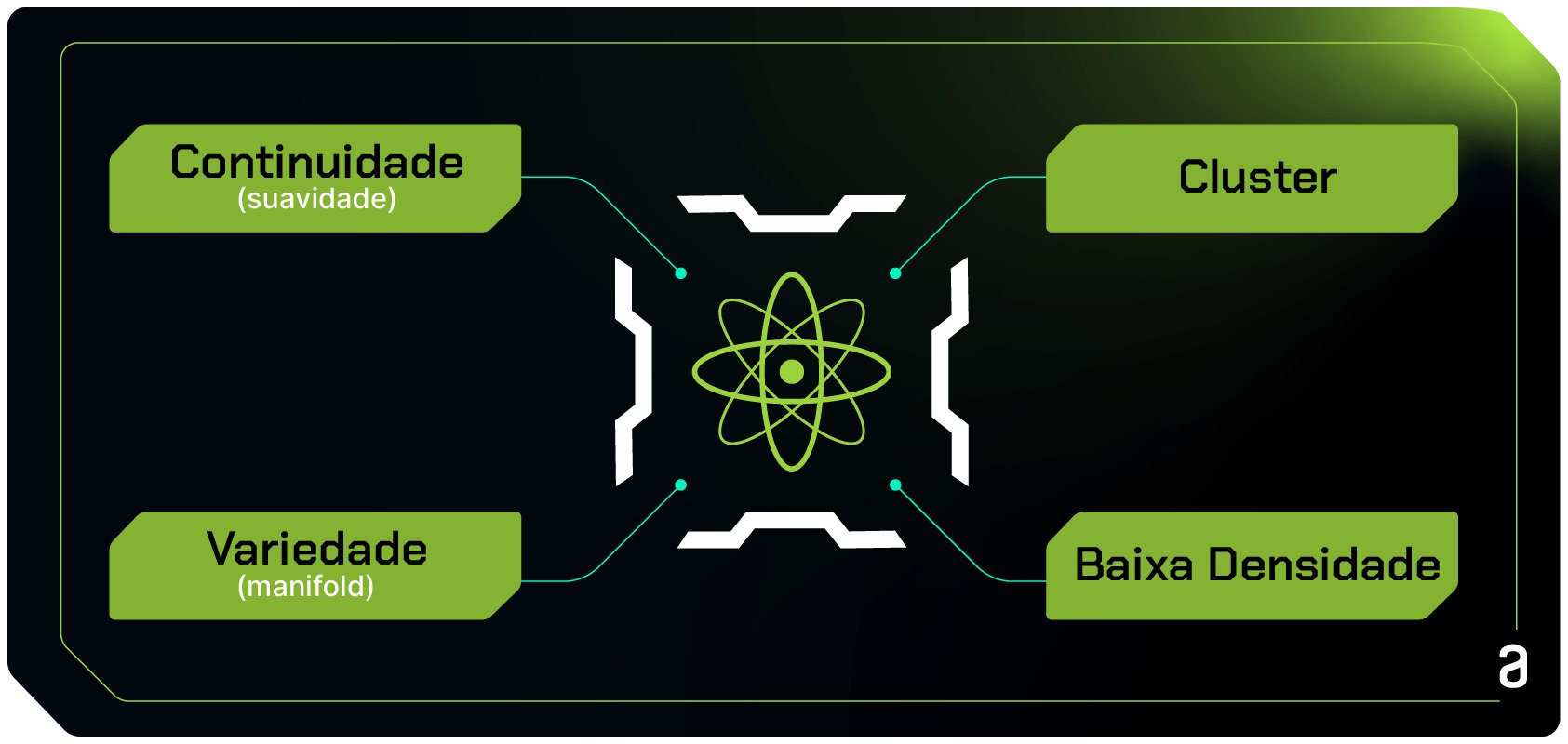
Existem algumas pressuposições gerais (premissas) que podem afetar a eficácia do aprendizado de máquina semi-supervisionado, e, para garantir a validez dos resultados, são interessantes de seguir.
São elas: premissa de continuidade (suavidade), premissa de cluster, premissa de baixa densidade e premissa de variedade (manifold):
Premissa de continuidade (suavidade)
Ela postula que dados próximos no espaço de características compartilham características semelhantes e tendem a pertencer à mesma classe. Em outras palavras, pontos de dados vizinhos têm maior probabilidade de possuir rótulos semelhantes.
Essa premissa é frequentemente utilizada por algoritmos semi-supervisionados para estender os rótulos das amostras rotuladas para dados não rotulados próximos, melhorando a generalização do modelo.
Premissa de cluster
Ela postula que os dados possuem uma estrutura de agrupamento natural (cluster), ou seja, pontos de dados semelhantes tendem a formar grupos distintos.
O aprendizado de máquina semi-supervisionado explora essa premissa ao usar dados rotulados para inferir a estrutura de agrupamento subjacente e, assim, atribuir rótulos a dados não rotulados próximos a um determinado grupo.
Essa premissa é particularmente eficaz quando as amostras de uma mesma classe formam aglomerados bem definidos quanto às diferenças nas características do conjunto.
Premissa de baixa densidade
A premissa de baixa densidade parte do princípio de que as regiões de baixa densidade de dados contém informações valiosas. Em outras palavras, áreas com poucos dados rotulados podem representar desafios mais complexos de classificação ou regressão.
Os algoritmos de aprendizado de máquina semi-supervisionado buscam aproveitar essas regiões, explorando os dados não rotulados para melhorar a capacidade de generalização em áreas menos densamente populadas, onde um modelo supervisionado poderia ter dificuldades pela falta de informação.
Premissa de variedade (manifold)
A premissa de variedade, também chamada de hipótese de manifold, sugere que os dados de alta dimensão muitas vezes residem em um espaço topológico de baixa dimensão (variedade).
É uma análise matemática que considera problemas de machine learning onde os dados podem ser representados em um espaço euclidiano, e assume que os dados não rotulados próximos a dados rotulados provavelmente seguem a mesma estrutura subjacente da variedade.
Algoritmos semi-supervisionados exploram essa premissa para prever rótulos em regiões pouco exploradas, melhorando a generalização do modelo em espaços de características complexas.
Agora que conhecemos algumas das premissas necessárias para utilizar a técnica de aprendizado semi-supervisionado, vamos conhecer também alguns dos principais algoritmos.
Algoritmos para aprendizado semi-supervisionado
Existem diferentes tipos de técnicas para resolver o problema dos rótulos dos dados. E entre esses algoritmos, se destacam: Label propagation, Self-training, Co-training e SVM semi-supervisionada.
Label Propagation
O Label Propagation é um algoritmo clássico e amplamente utilizado para aprendizado semi-supervisionado. Ele aproveita a ideia de que dados semelhantes têm rótulos semelhantes.

O algoritmo propaga os rótulos dos dados rotulados para os não rotulados com base nas similaridades entre eles.
Um exemplo gráfico do comportamento dos dados de rótulos ao se utilizar algoritmos para prevê-los pode ser observado na imagem abaixo, onde é utilizado o Label Propagation:
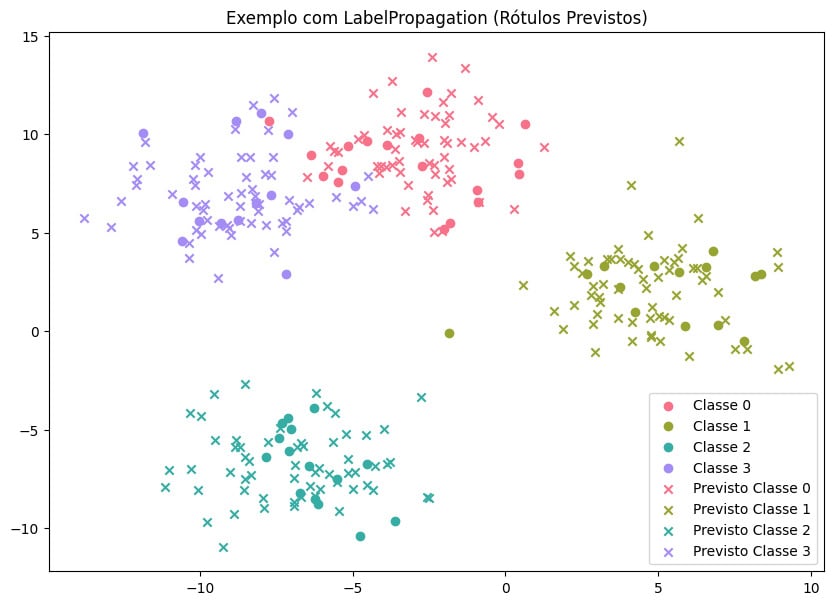
Nessa imagem, pode-se observar que os pontos próximos aos clusters foram previstos como pertencentes a estes, e parece haver uma boa definição sobre o valor predito para cada registro.
Na documentação do SKLearn, é possível encontrar informações sobre a implementação dessa técnica:
Self-Training
O algoritmo de self-training envolve treinar um modelo de aprendizado somente com os dados rotulados, e usá-los para rotular os dados não-rotulados com resultados mais assertivos (confiantes) e, em seguida, adicionar esses dados rotulados à base de treinamento. E esse processo é repetido em várias iterações. Esse método é relativamente simples e eficaz,
Na documentação do SKLearn, é possível encontrar informações sobre a implementação dessa técnica:
Co-Training
O co-training é uma abordagem derivada do self-training, que é especialmente útil quando há múltiplas fontes de dados ou características disponíveis, e a quantidade de rótulos disponíveis é pequena em relação ao tamanho do conjunto de dados analisados.
O método envolve treinar modelos independentes em diferentes conjuntos de características e, em seguida, usar as previsões mais confiantes de cada modelo para treinar um outro modelo definitivo. A ideia fundamental por trás do co-training é que, quando duas ou mais fontes independentes de dados concordam em relação a um exemplo não rotulado, a confiança na rotulação desse exemplo aumenta, tornando-o mais confiável.
Semi-Supervised SVM (Máquina de vetores de suporte Semi-Supervisionada):
As SVMs semi-supervisionadas são uma extensão dos Support Vector Machine (SVMs) tradicionais para dados rotulados e não rotulados. Elas buscam encontrar um hiperplano que separe as classes rotuladas, levando em consideração os dados não rotulados.
Na documentação do SKLearn, é possível encontrar informações sobre a implementação dessa técnica:
Conclusão
E aí, curtiu? Nesse artigo, nós conhecemos alguns dos tipos de aprendizagem para machine learning e abordamos com mais detalhes o aprendizado semi-supervisionado, entendendo sobre as suas premissas de uso, algoritmos e algumas aplicações.
Aqui na Alura nós temos vários conteúdos voltados a Machine Learning, Data Science e muito mais. Convidamos você a conhecer a Formação Machine Learning e também Formação Machine Learning Avançada, que conduzirão seu mergulho no universo de aprendizagem de máquina.
Mergulhe em tecnologia! 🤿🌊
Créditos
- Conteúdo: Marcus Almeida
- Produção técnica: Rodrigo Dias
- Produção didática: Pedro Drago
- Designer gráfico: Alysson Manso