



No momento de realizar o treinamento de modelos de machine learning, nos deparamos com um grande problema ao lidar com variáveis categóricas. As categorias não podem ser utilizadas em forma de texto, uma vez que os algoritmos compreendem apenas valores numéricos.
Também não podemos simplesmente atribuir um valor numérico para cada categoria, uma vez que esse processo, conhecido como ponderação arbitrária, pode criar uma ordenação e pesos para as categorias que não refletem a realidade.
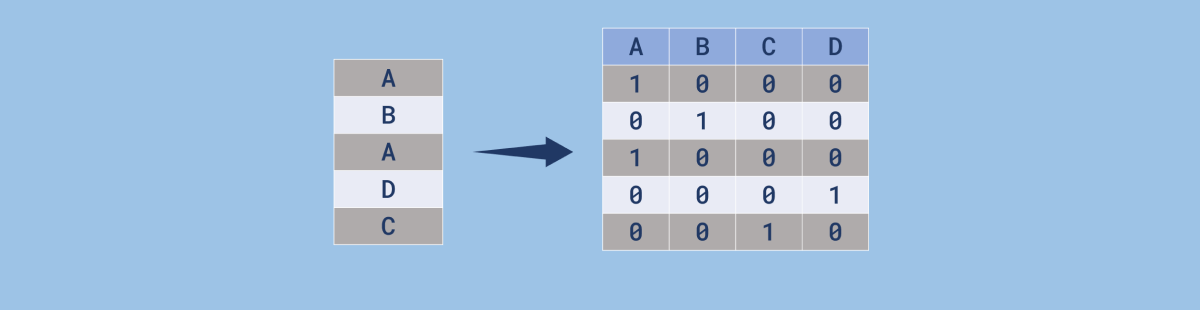
O processo correto de transformação das variáveis categóricas é feito a partir da criação de novas colunas a partir das categorias. Cada uma delas se torna uma nova coluna e o valor na linha correspondente será 1, caso tenha a presença da característica. Do contrário, será 0. Esse processo é conhecido como codificação "one-hot".
Vamos considerar a tabela contendo uma variável com 3 características:
| Variável |
|---|
| Característica 1 |
| Característica 2 |
| Característica 3 |
Ao aplicar o procedimento de "one-hot" nessa tabela, teremos o seguinte resultado:
| Característica 1 | Característica 2 | Característica 3 |
|---|---|---|
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
Para realizar esse processo através da linguagem Python, podemos usar o método get_dummies() da biblioteca Pandas ou o método OneHotEncoder() da biblioteca Sklearn. Vamos entender a diferença entre as duas funções.
get_dummies()
O método get_dummies() é simples de utilizar e faz a transformação de forma direta das variáveis categóricas.
import pandas as pd
dados = pd.DataFrame({'variavel':['caracteristica 1', 'caracteristica 2', 'caracteristica 3']})
pd.get_dummies(dados, columns = ['variavel'])
| variavel_caracteristica 1 | variavel_caracteristica 2 | variavel_caracteristica 3 | |
|---|---|---|---|
| 0 | 1 | 0 | 0 |
| 1 | 0 | 1 | 0 |
| 2 | 0 | 0 | 1 |
Esses dados podem ser passados como dados de entrada de um modelo de machine learning para realizar uma previsão. Porém, imagine que precisamos aplicar o processo para dados novos, contendo uma característica 2, já conhecida, e uma característica 4, que não foi utilizada na construção do modelo. O método get_dummies() não conseguirá gerar todas as colunas necessárias para a previsão. Ele vai considerar como válida uma característica não vista anteriormente e que não será entendida pelo modelo treinado.
dados_novos = pd.DataFrame({'variavel':['caracteristica 2', 'caracteristica 4']})
pd.get_dummies(dados_novos, columns = ['variavel'])
| variavel_caracteristica 2 | variavel_caracteristica 4 | |
|---|---|---|
| 0 | 1 | 0 |
| 1 | 0 | 1 |

OneHotEncoder()
Já o método OneHotEncoder() funciona como outros modelos disponíveis na biblioteca Sklearn. Nele, é necessário instanciar um objeto e depois ajustar aos dados com um método fit(). Dessa forma, esse objeto armazena os passos necessários para realizar a transformação dos dados.
from sklearn.compose import make_column_transformer
from sklearn.preprocessing import OneHotEncoder
colunas_categoricas = ['variavel']
one_hot_enc = make_column_transformer(
(OneHotEncoder(handle_unknown = 'ignore'),
colunas_categoricas),
remainder='passthrough')
dados = one_hot_enc.fit_transform(dados)
dados = pd.DataFrame(dados, columns=one_hot_enc.get_feature_names_out())
dados
| onehotencoder__variavel_caracteristica 1 | onehotencoder__variavel_caracteristica 2 | onehotencoder__variavel_caracteristica 3 | |
|---|---|---|---|
| 0 | 1 | 0 | 0 |
| 1 | 0 | 1 | 0 |
| 2 | 0 | 0 | 1 |
Ao aplicar em novos dados, o método OneHotEncoder() irá construir todas as colunas que foram geradas no treinamento atribuindo valor 0 ou 1, dependendo da presença ou ausência da característica, respectivamente. Logo, esse método é ideal para utilizar em modelos de machine learning.
dados_novos = pd.DataFrame({'variavel':['caracteristica 2', 'caracteristica 4']})
dados_novos = one_hot_enc.transform(dados_novos)
dados_novos = pd.DataFrame(dados_novos, columns=one_hot_enc.get_feature_names_out())
dados_novos
| onehotencoder__variavel_caracteristica 1 | onehotencoder__variavel_caracteristica 2 | onehotencoder__variavel_caracteristica 3 | |
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 |
Assim, a característica 4 contida nos novos dados não se torna uma nova coluna, apenas são atribuídos os valores 0 para cada uma das características utilizadas no momento do treinamento do modelo. Além disso, o processamento que foi criado pelo OneHotEncoder() pode ser armazenado em arquivos pickle, assim como outros modelos de machine learning, para ser utilizado fora do ambiente onde foi criado, permitindo o uso em outros projetos.
import pickle
with open('modelo_onehotenc.pkl', 'wb') as file:
pickle.dump(one_hot_enc, file)
Para importar o modelo em outros projetos, basta usar a função pd.read_pickle():
modelo_one_hot = pd.read_pickle('modelo_onehotenc.pkl')
Desse modo, podemos observar que o get_dummies() é fácil de utilizar, mas é preferível para atividades de análises de dados, enquanto o OneHotEncoder() é mais recomendado para aplicar em modelos de machine learning.






