


Fazendo um pouco de estatística com R
Dados, dados e dados. Aplicações web onde os usuários, de forma direta ou indireta, enviam milhares de dados para o servidor; dados esses que no futuro podem ser analisados e ajudar a área de negócios a tomar decisões mais embasadas. Esse sempre foi o grande apelo da web 2.0.
Mas o que fazer com tantos dados? Como analisar? A resposta é simples: estatística. O Google já disse algumas vezes que estatística é a profissão do futuro.
Mas, e como fazer todo esse processamento? Qual software usar? Um dos mais populares softwares de estatística é o projeto R. O R é uma linguagem de programação totalmente pensada para estatísticos. A linguagem é totalmente otimizada para lidar e calcular testes estatísticos em cima de grandes conjuntos de dados.

Uma das grandes vantagens do R é justamente a sua simplicidade. É bem fácil começar com a linguagem. Além disso, a quantidade de bibliotecas que fazem as mais diferentes tarefas é grande. Para começar, instale o R no seu sistema operacional. No site do projeto, tem o download para as mais diferentes plataformas. Para facilitar, baixe também o RStudio, que é uma interface gráfica que ajuda.
Vamos começar. O primeiro passo é ter um conjunto de dados. Dados são geralmente representados por listas, afinal geralmente temos "um monte" de números de uma só vez. Vamos declarar então uma lista, chamada notas, que tem as notas dos alunos de uma turma específica:
notas <- c(7,2,4,8,7,3,9,10)
A linguagem é bastante expressiva. Podemos, por exemplo, fazer conta com essa lista. Se multiplicarmos por dois, temos o resultado:
notas \* 2 \[1\] 14 4 8 16 14 6 18 20
É fácil também calcular média, mediana, quartis, e etc. Podemos, por exemplo, usar a função summary, que nos dá um "resumo" daquele conjunto de dados.
summary(notas)
Min. 1st Qu. Median Mean 3rd Qu. Max. 2.00 3.75 7.00 6.25 8.25 10.00
O R também nos deixa traçar diferentes gráficos. Um histograma, por exemplo, que é aquele gráfico usado para mostrar frequência dos elementos em uma lista:
hist(notas)
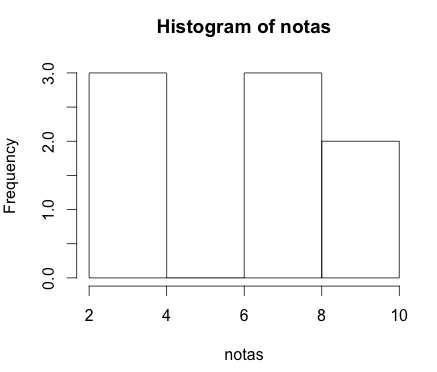
Obviamente um comando como o hist possui diversos outros parâmetros.
Vamos declarar agora uma outra lista, que marca a quantidade de faltas que um aluno teve no semestre. Veja que a quantidade de elementos bate com a quantidade de notas, ou seja, para um mesmo aluno temos a sua nota, e as suas faltas:
faltas <- c(2,5,4,0,1,4,1,0)
Será que nessa turma, um aluno que falta muito tem notas mais baixas? Podemos verificar se existe uma correlação entre as duas variáveis (se uma cresce, a outra cresce também?). Uma teste de correlação comum é o Spearman. Vamos lá:
cor.test(faltas,notas)
Pearson's product-moment correlation
data: faltas and notas t = -8.0341, df = 6, p-value = 0.0001987 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.9923313 -0.7726657 sample estimates: cor -0.9565303
Veja que o teste nos disse -0.95, que significa que existe uma alta correlação, ou seja, quanto maior uma variável (faltas), menor a outra (notas). Ou seja, vá pra aula, que sua nota melhorará! :)
Neste texto não expliquei os detalhes de um teste de correlação ou a diferença entre média e mediana. Para usar o R, você obviamente precisa conhecer de estatística. Mas veja como a ferramenta é fácil e simples de ser usada. Existem diversos plugins, como por exemplo, o plugin que conecta no MySql, para que você extraia os dados por meio de SQLs. Enfim, R é uma excelente escolha para os desenvolvedores que precisam fazer uso de estatística.
Você usa métodos estátisticos no seu dia a dia? Qual ferramenta usa?




