Data Warehouse: o que é, para quê serve e como funciona


A habilidade de acessar informações de maneira rápida e clara é essencial para realizar tomadas de decisões mais assertivas.
Mesmo que isso não garanta totalmente o sucesso, a quantidade e a qualidade das informações disponíveis elevam consideravelmente as chances de tomar melhores decisões.
Nessa perspectiva, é comum surgir algumas perguntas sobre como assegurar a integridade dos sistemas de informações e garantir que as análises e relatórios sejam confiáveis e precisos.
Afinal, quanto mais informações o time executivo tiver, maiores são as probabilidades de tomar melhores decisões para a estratégia do negócio.
Neste artigo, vamos explorar o sistema Data Warehouse, principalmente a partir da sua importância no momento de insights estratégicos e de sua eficácia em relação à consolidação, armazenamento e gestão.
Assim, embarcamos no seguinte desafio: identificar as melhores formas de obter essas informações críticas, definir os métodos mais eficazes para apresentá-las e determinar quais ferramentas são essenciais para fornecer informações de maneira rápida e clara aos executivos.
Para isso, precisamos primeiro determinar qual é a matéria prima da informação.
Esta resposta é clara: são os dados sobre a empresa, sobre o mercado e até mesmo sobre o ambiente de negócio onde você está inserido.
Considerando que os dados são a matéria-prima da informação, o nosso desafio nessa jornada consiste em compreender a seguinte questão: como podemos transformar dados em informação?
Destaque-se em sua carreira e seja capaz de tomar decisões informadas com base em dados através do Data Warehouse. Vamos lá?
Dados espalhados pela empresa
Considere esta situação: você é uma pessoa responsável por decisões operacionais diárias de uma empresa e por escolhas estratégicas de médio e longo prazo que podem moldar o futuro da organização.
Sendo assim, é essencial estar por dentro de todas as informações relevantes para identificar a melhor decisão.
Logo, é crucial converter dados em informações úteis. Esses dados podem estar dispersos pela empresa em vários formatos, tais como:
Informação em papel: não digitalizada, exemplifica os dados históricos antes da era dos computadores.
Meios eletrônicos: informações que podem não estar nos sistemas centrais da empresa, mas sim em arquivos de texto, planilhas ou documentos armazenados localmente nos dispositivos dos usuários.
Conversas por telefone: informações originadas em diálogos com colegas ou concorrentes sobre, por exemplo, novos produtos.
Bancos de dados transacionais: a empresa possui sistemas que ajudam na operação, seja na área de produção ou administrativa.
E-mail: trocas de e-mails que podem conter dados cruciais para a empresa.
Correio: informações recebidas através de correspondências, cobranças ou anúncios publicitários.
Conversas informais: diálogos cotidianos que podem revelar informações valiosas sobre o mercado ou a concorrência.
Portanto, como etapa inicial, é fundamental coletar esses dados dispersos por toda a empresa e consolidá-los em um local central.
Isso nos permitirá começar efetivamente o processo de transformar esses dados brutos em informações valiosas.
No entanto, mesmo nessa etapa, nos deparamos com desafios adicionais. O processo de coleta de todos esses dados envolve uma dificuldade frequente nas empresas, que passaremos a explorar a seguir.

Conceitos diferentes para as mesmas coisas
Agora pense nessa outra situação: você, na posição de presidência de uma empresa, deseja saber o faturamento do último mês, mas não possui um sistema de BI para obter essa informação rapidamente.
Assim, você decide consultar diretamente a diretoria de vendas. Se trata de algo importante que você precisa saber para tomar uma decisão rápida. Prontamente, lhe fornecem um valor específico.
Porém, buscando confirmação, você entra em contato com a diretoria financeira, que surpreendentemente apresenta um número diferente.
Agora, resta a dúvida: em quem acreditar? Na diretoria de vendas ou no financeiro? Todas são pessoas de sua confiança e estão lhe fornecendo dados diferentes.
Diante dessa discrepância, você recorre à diretoria de contabilidade, responsável pelos balanços oficiais da empresa, esperando por uma resposta definitiva. No entanto, lhe fornecem um terceiro número.
Agora, o dilema fica ainda mais abrangente: em qual número confiar? Como determinar qual é a informação correta?
Na realidade, todas as diretorias estão corretas à sua maneira. A divergência nos números se deve ao fato de que cada departamento da empresa adota um critério distinto para definir o que constitui o faturamento.
Então, por exemplo, para a diretoria de vendas, o faturamento ocorre no momento da emissão da nota fiscal.
Já para o setor financeiro, se considera faturamento quando o dinheiro efetivamente entra na conta bancária da empresa.
E, finalmente, para a contabilidade, só é possível registrar o faturamento quando o valor é contabilizado na conta contábil.
Há outros exemplos que ilustram esta situação, como no caso de custos e vendas. A presidência, ao desejar saber o lucro dos produtos da linha branca, questionou à diretoria de vendas sobre o faturamento desses produtos e, em seguida, indagou a diretoria da fábrica sobre o custo de fabricação da mesma linha.
Com esses dados, calculou o lucro pela diferença entre os dois valores. Porém, logo depois, percebeu um equívoco no cálculo, pois as definições de “linha branca” variam entre os setores.
Para a diretoria de vendas, a linha branca compreende todos os produtos de cozinha. Por outro lado, para a produção, a linha branca também considera a fabricação de ar-condicionado, uma vez que a mesma linha de montagem produz motores de geladeiras e de ar-condicionado.
Nos dois exemplos, identificamos duas questões chave:
a) Variações nos conceitos dos indicadores em diferentes setores da empresa
b) Diferenças nos critérios para agrupar esses indicadores.
Diante disso, uma conclusão importante surge: no nível operacional, cada departamento da empresa pode manter seus próprios conceitos, seja na definição de faturamento ou na classificação de produtos como “linha branca”.
Contudo, quando se trata de informações gerenciais, cruciais para a tomada de decisões estratégicas que afetam a empresa como um todo, torna-se imprescindível a unificação desses conceitos.
A empresa precisa estabelecer uma definição oficial e uniforme para o que considera como faturamento gerencial.
Da mesma forma, é necessário um consenso sobre como se deve agrupar e interpretar indicadores, especialmente os da linha branca.
Outro aspecto crucial é considerar o tempo. Ao tomar decisões referentes ao faturamento, é vital compreender a sua evolução ao longo do tempo.
Por outro lado, o departamento de vendas necessita de informações mais imediatas, como os produtos vendidos em um dia específico ou até em uma hora.
Esses dados são fundamentais para comunicar ao departamento de produção sobre os níveis de estoque em cada loja e planejar a produção de novos itens.
Enquanto a área operacional foca no presente imediato, a gestão precisa analisar tendências e padrões ao longo de períodos mais extensos, que podem abranger semanas, meses ou até anos.
A uniformização de conceitos, a padronização dos critérios de agregação e uma análise com mais detalhes ao longo do tempo são elementos fundamentais para a transformação eficaz de dados em informações úteis.
Mas como podemos efetivamente resolver essa questão?
O que é Data Warehouse?
A solução envolve criar uma base de dados distinta que diferencie os dados operacionais, que utilizam conceitos específicos a cada departamento, dos dados gerenciais, que seguem um conceito unificado e oficial da empresa.
Assim, o primeiro passo é compreender estas regras oficiais gerenciais e os modelos de informação gerencial que serão implementados na empresa, facilitando a transformação eficiente de dados brutos em informações úteis e estratégicas.
Esta abordagem, que hoje nos parece óbvia, não era evidente no passado. Foi Ralph Kimball, um pesquisador americano, quem identificou os desafios das empresas, como a unificação de conceitos, diferentes métodos de agregação e a variedade de fontes de dados que comprometiam a eficácia do Business Intelligence.
Kimball propôs então a criação de uma estrutura distinta da operacional, dedicada exclusivamente ao BI.
Essa nova estrutura, alimentada pelos dados da organização, incorporaria conceitos uniformes aplicáveis a toda a empresa.
Para essa base de dados gerencial, Kimball cunhou o termo Data Warehouse, que em português significa armazém de dados.
Ao planejar o Data Warehouse, é crucial entender as regras gerenciais específicas da empresa.
Mesmo duas empresas concorrentes no mesmo setor e produzindo produtos similares podem ter Data Warehouses distintos, refletindo conceitos diferentes para itens como vendas ou lucros.
Por exemplo, uma empresa influenciada pela abordagem alemã pode priorizar o fluxo de caixa, enquanto outra, seguindo a perspectiva americana focada em marketing, pode adotar o conceito do departamento de vendas.
Importante ressaltar que o Data Warehouse não tem responsabilidades fiscais, permitindo assim sua configuração de acordo com as necessidades e escolhas da empresa.
Portanto, a etapa inicial na implementação de um Data Warehouse é realizar entrevistas com os executivos para compreender e definir os conceitos que nortearão os indicadores gerenciais da organização.
Quanto à condução dessas entrevistas, não há uma fórmula rígida a ser seguida. O aspecto mais importante é buscar entender quais dados são vitais para as tomadas de decisão da empresa.
Ou seja, como identificar esses dados e quais conceitos usar para calcular e agregar esses dados.
Embora não exista um método único para obter essas respostas, existe uma abordagem padrão para representar e compreender essas informações, que deve ser adaptada às necessidades e especificidades de cada organização.
E isto é possível de ser realizado através da Matriz Dimensão Indicador.
Se você quiser se aprofundar no assunto, considere estudar no nosso curso de Modelagem do Data Warehouse: atributos, hierarquia e indicadores, que explora tópicos pertinentes e bem específicos sobre esse tema. Vale à pena!
Como a representação das regras de negócio para um Data Warehouse
Ao planejar o Data Warehouse, o primeiro passo é entender profundamente o negócio: conhecer suas atividades, os principais indicadores, como os executivos tomam decisões e quais informações são essenciais para esses processos.
É comum encontrar profissionais de BI com especialização em determinados segmentos de mercado: indústria alimentícia, bancos, mineração, etc.
No entanto, para construir um Data Warehouse, não é estritamente necessário ter um conhecimento de negócios tão profundo quanto o desses profissionais.
Realizar entrevistas detalhadas dentro da empresa, especialmente com os executivos que são responsáveis pelas decisões, pode ser suficiente.
As entrevistas podem variar em abordagem, porém devem sempre incluir duas perguntas fundamentais:
1. O que queremos analisar? 2. Como queremos analisar?
As respostas a essas perguntas definirão a estrutura do nosso Data Warehouse. Por exemplo, se uma empresa reporta vendas de R$10.000.000,00, é crucial contextualizar esse número. Pois ele pode referir-se a vendas apenas na região Sul, em suco de laranja ou em uma sede específica, como São Paulo.
Como essa contextualização dá mais significado aos números, é necessário definir os indicadores e como eles serão interpretados.
Na ciência de BI, os termos que usamos são importantes. O que queremos analisar, os números, são chamados de indicador, também conhecido como medida ou variável.
A maneira como analisaremos esses indicadores é a dimensão. Por exemplo, ao dizer quero analisar as vendas pela dimensão geográfica, significa que desejamos ver as vendas por área geográfica (região, estado, cidade).
Depois de concluir as entrevistas, definimos as dimensões e os indicadores. Para documentar essas informações, é necessário criar um Matriz Dimensão X Indicador, que contribui no registro dos resultados das entrevistas.
Embora seja possível elaborar essa matriz com ferramentas básicas como lápis e papel, optamos por métodos mais avançados, dada a natureza tecnológica do nosso trabalho.
Você pode usar ferramentas como Word, PowerPoint ou softwares de desenho para esquematizar de forma mais complexa.
Um bom exemplo de aplicação é usar uma planilha do Excel, pois sua estrutura de linhas e colunas é ideal para a construção de matrizes.
Nas linhas da matriz, anotamos os indicadores — o que desejamos analisar, como vendas, custos e lucros.
Nas colunas, inserimos as dimensões, que representam como o cliente deseja visualizar a informação, por exemplo, linha de produção, custo para o almoxarifado e tempo de produção.
Na matriz, é necessário marcar as intersecções que fazem sentido entre dimensões e indicadores, com base nas informações coletadas nas entrevistas.
Exemplos
Para exemplificar, considere a seguinte matriz:
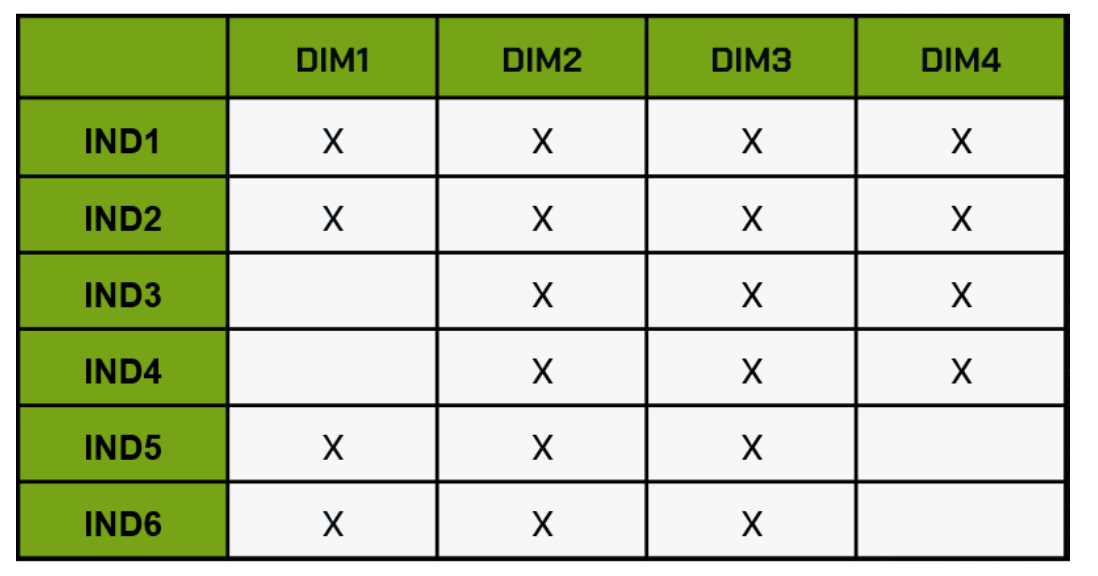
Neste exemplo, nem todos os indicadores se cruzam com todas as dimensões, como ilustrado pelo Ind3, que não se relaciona com a Dim1. As escolhas de cruzamento se baseiam nas respostas das entrevistas.
Agora, observe uma matriz mais simples:

Neste segundo exemplo, vendas se relaciona com cliente e produto, pois a venda envolve um cliente específico e um produto.
No entanto, o custo da matéria-prima para fabricar o produto não está diretamente ligado ao cliente.
O modelo de matriz e indicadores reflete o modelo de negócios da empresa. Em uma indústria, a incerteza recai sobre e quais produtos serão vendidos para quais clientes.
Já em uma empresa de construção naval, que lida com projetos específicos, sabe exatamente para qual cliente cada navio está sendo construído.
Como construir o Data Warehouse
Assim que a matriz estiver completa e aprovada pelas pessoas usuárias-chave da empresa, o próximo passo é desenvolver a base de dados gerencial.
A matriz servirá como um guia essencial para essa construção, estabelecendo um método claro para o processo.
Em geral, a base de dados gerencial é construída em bancos de dados relacionais. Nesses sistemas, é preciso definir as tabelas, os campos com seus respectivos tipos de dados e configurar chaves primárias e estrangeiras para estabelecer relações entre as tabelas. O Data Warehouse adota essas mesmas características fundamentais.
No entanto, a configuração específica das tabelas, campos e chaves é determinado com base nos resultados obtidos da matriz e do modelo específico de Data Warehouse que se opta por implementar.
Utilizando a matriz dimensão-indicador, podemos começar a elaborar as tabelas do Data Warehouse.
Esse processo começa com a análise de todos os indicadores que compartilham os mesmos cruzamentos entre dimensões, conforme representado na matriz.
Os indicadores com cruzamentos comuns serão agrupados em tabelas de fato. No exemplo a seguir, esse agrupamento é ilustrado com cores distintas, facilitando a visualização dos indicadores que compartilham os mesmos pontos de intersecção.

Assim a partir deste cruzamentos derivamos as tabelas de fato.
Inicialmente, é importante compreender o conceito de uma tabela de fato. Este termo origina-se do inglês Fact Table, porém, aqui, Fact está mais associado a uma ocorrência ou evento.
Registramos um dado na tabela fato quando ocorre algo relacionado a um determinado indicador. Através da matriz, podemos identificar quais são essas tabelas de fato, pois elas documentam as ocorrências ou eventos relevantes para os indicadores identificados.
Após a definição das tabelas de fato, passamos à construção das tabelas que representam as dimensões.
Inicialmente, identificamos se existem relações entre as dimensões, isto é, as colunas da matriz dimensão-indicador. Ao notar essas relações, agrupamos as entidades correspondentes em níveis, e o que designamos como dimensão passa a ser o conjunto de colunas da matriz que têm possibilidade de se relacionar entre si.
Essas entidades, quando agrupadas, formam uma dimensão que pode ser representada de diferentes maneiras em um banco de dados relacional. Duas abordagens comuns são o modelo estrela e o modelo flocos de neve.
No modelo estrela, todas as entidades agrupadas em uma dimensão são representadas em uma única tabela, que é desnormalizada.
Por outro lado, no modelo flocos de neve, cada entidade é representada em sua própria tabela e se relaciona com as demais por meio de chaves estrangeiras.
A escolha de representar as dimensões como estrela ou flocos de neve vai depender de alguns fatores relacionados com desempenho, clareza na representação e na facilidade de manutenção.
Alguns tópicos relevantes para tomada de decisão de escolha de uma ou outra forma de representação:
Modelo estrela
As vantagens do modelo estrela são:
Simplicidade e Clareza: Estrutura mais simples e fácil de entender, especialmente útil para usuários finais e ferramentas de BI.
Desempenho: Consultas geralmente são mais rápidas devido à desnormalização, pois requerem menos joins.
Facilidade de Manutenção: Mais fácil de manter e alterar devido à sua estrutura simplificada.
As desvantagens são:
Redundância de Dados: A desnormalização pode levar a redundância de dados, aumentando o espaço de armazenamento necessário.
Integridade de Dados: Maior risco de inconsistências de dados devido à redundância.
Atualizações: As atualizações podem ser mais complexas e demoradas devido à duplicação de dados.
Modelo Flocos de Neve
As vantagens do modelo Flocos de Neve são:
Normalização: Reduz a redundância de dados e melhora a integridade dos dados.
Economia de Espaço: Ocupa menos espaço de armazenamento devido à menor duplicação de dados.
Flexibilidade: Permite maior detalhamento e complexidade nas relações entre as dimensões.
As desvantagens são:
Complexidade: Estrutura mais complexa, o que pode dificultar a compreensão e o uso por parte de usuários finais e analistas.
Desempenho: Consultas podem ser mais lentas devido ao maior número de joins necessários.
Manutenção: Pode ser mais difícil de manter e modificar devido à sua complexidade estrutural.
Em resumo, o modelo estrela é geralmente preferido por sua simplicidade e eficiência em consultas, enquanto o modelo flocos de neve é escolhido quando a integridade e a redução da redundância de dados são prioritárias.
A escolha entre eles depende das necessidades específicas do projeto, das características dos dados e das preferências dos usuários.
Claro que, após a criação das tabelas que representam as dimensões, fazemos uma associação com as tabelas de fato fechando o desenho do Data Warehouse.
Se quiser conhecer mais profundamente sobre esse assunto, estude conosco no curso de SQL Server: construção do Data Warehouse e explore tópicos pertinentes sobre os diversos esquemas de construção de Data Warehouses. Vale a pena conferir!
Carga de dados
Depois de projetar o Data Warehouse, o próximo passo crucial é realizar a carga de dados.
Este processo exige a implementação de procedimentos capazes de identificar as fontes de dados, transformá-las conforme as regras de negócio estabelecidas durante as entrevistas e, por fim, carregá-las na base de dados gerencial.
É possível executar esse carregamento através de três formas:
Programas em várias linguagens de programação com capacidade de interagir com dados externos, utilizando procedures integradas aos próprios bancos de dados;
Processos de extração de dados presentes nos sistemas de gestão empresarial (ERPs);
Ferramentas especializadas disponíveis no mercado, projetadas especificamente para estes tipos de processos.
Para realizar a carga de dados no Data Warehouse, podemos adotar duas abordagens distintas, que são representadas pelas letras E, T e L.
Essas letras representam as etapas do processo, cada uma com um significado específico:
E de Extract (Extrair): Refere-se à etapa de extração de dados das fontes originais.
T de Transform (Transformar): Esta etapa envolve a transformação dos dados extraídos, ajustando-os de acordo com as regras de negócio e as necessidades do modelo.
L de Load (Carregar): A última etapa é o carregamento dos dados no destino.
Com a compreensão das letras E, T e L, podemos explorar as duas abordagens principais no processo de movimentação de dados: ETL e ELT.
ETL (Extract, Transform, Load)
Nesta abordagem, os dados são inicialmente extraídos (E) de suas fontes originais.
Em seguida, eles são transformados (T) na memória, ajustando-se às regras de negócio da empresa.
Por fim, esses dados transformados são carregados (L) no Data Warehouse. Esta metodologia é considerada mais tradicional, com foco direto no processamento para o Data Warehouse.
ELT (Extract, Load, Transform)
Esta segunda abordagem altera a ordem das etapas. Os dados são primeiramente extraídos (E) das fontes e, em seguida, carregados (Ldiretamente em um repositório chamado Data Lake, sem transformações prévias.
A etapa de transformação (T) ocorre posteriormente, quando os dados são transferidos do Data Lake para o Data Warehouse e ajustados conforme as regras de negócio.
Atualmente, com a capacidade de armazenamento não sendo uma grande limitação, a abordagem ELT tem ganhado popularidade.
Isso se deve ao fato de que os dados armazenados no Data Lake ficam prontamente disponíveis para múltiplos usos, não apenas servindo como fonte para o Data Warehouse, mas também para outros propósitos analíticos e operacionais.
Independentemente do método selecionado, seja ETL ou ELT, o simples carregamento de dados em um Data Warehouse, projetado com base nas regras de negócio da empresa, não assegura automaticamente que esses dados se transformem em informação.
Cursos da Alura sobre Data Warehouse
Para explorar ainda mais sobre esse assunto, confira a seguir as indicações:
[Curso Oracle PL/SQL: procedures, funções e exceções]https://cursos.alura.com.br/course/oracle-pl-sql-procedures-funcoes-excecoes
Curso Data Warehouse e Integration Services: carregando dados dimensionais
Data Mart
O Data Warehouse funciona como o repositório central de informações gerenciais de uma corporação.
Agora, pense na quantidade de indicadores e dimensões que uma empresa, especialmente de grande porte, pode ter.
Além disso, considere o acúmulo de tabelas que armazenam dados ao longo de um extenso período.
Embora os bancos de dados relacionais sejam eficientes para armazenar dados, a consulta direta em grandes volumes pode impactar negativamente o desempenho, especialmente no caso de dados gerenciais, que tendem a ser mais consolidados.
Diante disso, uma estratégia eficaz é a criação de Data Marts, ou “Mercados de Dados”, que são basicamente pequenos bancos de dados focados em consultas específicas.
Nessa analogia, se o Data Warehouse é um grande centro de distribuição de mercadorias, os Data Marts funcionam como lojas locais que obtêm seu estoque do centro principal.
Esses Data Marts permitem consultas mais rápidas e eficientes, aliviando a carga sobre o Data Warehouse principal.
A implementação dos Data Marts pode ocorrer tanto no mesmo banco de dados relacional onde o Data Warehouse está hospedado, quanto em um tipo diferente de banco de dados, projetado especificamente para otimizar a performance.
Esses são conhecidos como bancos de dados OLAP (On Line Analytical Processing). Nesta arquitetura, os cruzamentos entre indicadores e dimensões são calculados antecipadamente, facilitando a consulta rápida no momento da geração dos relatórios.
Uma vez que esses dados pré-calculados tendem a ocupar um volume significativo de espaço, os Data Marts geralmente são limitados a um escopo específico dentro da empresa, evitando um crescimento descontrolado.
No entanto, independentemente de como os Data Marts são estruturados, é fundamental que a única fonte de dados para alimentá-los seja o Data Warehouse.
O uso de outras fontes de dados, fora do escopo do Data Warehouse, deve ser evitado para garantir a consistência e a integridade das informações.
Para uma abordagem mais aprofundada sobre esse assunto, considere estudar:
Curso Data Mart e Analysis Services: construindo um modelo OLAP multidimensional
Curso Data Mart e Analysis Services: entendendo a linguagem de consultas MDX
Visualização da informação
Depois de carregar os Data Marts, passamos à etapa de visualização dos dados, momento em que eles se transformam em informação útil.
Isso é feito por meio do que chamamos de dashboard ou painéis de informações.
Os dashboards apresentam os dados de maneira clara e objetiva, utilizando gráficos coloridos e representações visuais atraentes.
Assim, a pessoa usuária final pode visualizar a informação sob diferentes perspectivas.
Além disso, disponibilizamos ferramentas para análises Ad-Hoc. O termo “Ad-Hoc”, de origem latina, significa “para este fim” ou “para esta ocasião específica”.
Como o próprio nome sugere, essas ferramentas permitem que as pessoas usuárias explorem os dados armazenados nos Data Marts, criando suas próprias visões e análises.
Elas oferecem flexibilidade para examinar as informações sob diversos ângulos, selecionando as dimensões desejadas para as colunas e linhas, e analisando os indicadores com base em critérios de consolidação variados.
Isso enriquece a experiência de análise, proporcionando insights mais profundos e personalizados.
Um equívoco comum na atualidade é a crença de que, com as novas ferramentas avançadas para criação de Dashboards, não há necessidade de se estabelecer Data Warehouses e Data Marts.
Essa ideia, muitas vezes promovida pelos fornecedores dessas ferramentas, pode criar uma dependência indesejada das empresas em relação a esses produtos.
Com o desenvolvimento tecnológico, essas ferramentas de dashboard começaram a incorporar funcionalidades de extração e transformação de dados.
Elas sugerem que, simplesmente ao se conectar às fontes de dados operacionais, é possível gerar Dashboards de maneira rápida e eficiente, sem a necessidade dos processos abrangentes de ETL ou ELT discutidos anteriormente neste artigo.
No entanto, essa abordagem pode trazer desafios, como a falta de uma visão unificada e consolidada dos dados, o que é fundamental para uma análise empresarial eficaz e abrangente.
Para dados locais ou individuais, as capacidades de extração e transformação oferecidas pelas ferramentas de Dashboard podem ser bastante eficazes.
Contudo, no contexto de informações gerenciais corporativas, confiar exclusivamente nessas ferramentas para essas funções pode ser arriscado.
Isso se deve ao fato de que as regras de negócio críticas, que foram tão enfatizadas no início deste texto, acabam sendo implementadas diretamente na ferramenta de visualização.
Um problema potencial surge quando diferentes técnicos utilizam a mesma ferramenta para construir diferentes Dashboards que incluem um indicador comum.
Como podemos garantir a consistência na implementação da transformação de dados? Se cada técnico aplicar sua interpretação das regras de negócio, pode haver variações significativas na forma como os dados são processados e apresentados.
Isso pode levar a inconsistências nos Dashboards, resultando em análises divergentes ou até mesmo conflitantes para o mesmo indicador.
Portanto, no caso de dados relacionados a informações gerenciais corporativas, a manipulação e transformação dos dados devem ser restritas ao Data Warehouse e aos Data Marts.
As ferramentas de Dashboard, por sua vez, devem ser utilizadas exclusivamente para a exibição de dados já processados e consolidados, provenientes dessas bases.
Para dar continuidade, explore ainda mais sobre esse assunto através de nossas formações. Nelas, você terá acesso a alguns cursos da Alura onde estas ferramentas de Dashboard são apresentadas:
Data Warehouse na empresas
Quando falamos de empresas de grande porte a existência de um Data Warehouse corporativo é unânime.
Dentro da área de TI existem profissionais que se dedicam a manter e atualizar estes bancos de dados gerenciais que sirva de grande centralizador de dados gerenciais para serem fornecidos aos mercados locais que irão distribuir a informação.
Com o uso mais difundido dos grandes provedores de nuvens, muitos bancos de dados já provêem instâncias especializadas para armazenar informações gerenciais.
Vários grandes provedores de serviços em nuvem oferecem ferramentas robustas para a construção e gerenciamento de Data Warehouses. Alguns dos mais notáveis incluem:
Amazon Web Services (AWS): Oferece o Amazon Redshift, uma solução de Data Warehouse em nuvem, que é amplamente utilizada por sua capacidade de processar grandes volumes de dados e sua integração com outras ferramentas e serviços da AWS.
Microsoft Azure: O Azure fornece o Azure SQL Data Warehouse (agora conhecido como Azure Synapse Analytics), que integra armazenamento de dados empresariais e análise de big data.
Google Cloud Platform (GCP): O Google BigQuery que é um Data Warehouse totalmente gerenciado e sem servidor que permite consultas rápidas em grandes conjuntos de dados.
IBM Cloud: Oferece o IBM Db2 Warehouse on Cloud, que é um Data Warehouse totalmente gerenciado, construído sobre a tecnologia Db2.
Oracle Cloud: A Oracle oferece o Oracle Autonomous Data Warehouse, conhecido por sua automação e otimização autônomas.
Snowflake: Embora não seja um provedor de nuvem tradicional, a Snowflake oferece um serviço de Data Warehouse em nuvem que opera em várias plataformas de nuvem, incluindo AWS, Azure e GCP.
Cada um desses provedores de serviços em nuvem possui características e especializações distintas, o que torna essencial para as empresas uma avaliação criteriosa de suas necessidades específicas ao selecionar a solução mais apropriada.
Conclusão
Atualmente, observa-se uma tendência crescente das empresas em se afastar da construção de bancos de dados On-Premises (localmente), optando por criar instâncias nas plataformas mencionadas anteriormente para o desenvolvimento de seus Data Warehouses.
Esta mudança reflete o desejo das organizações de aproveitar a flexibilidade, escalabilidade e eficiência que as soluções de nuvem oferecem para a gestão de grandes volumes de dados.
Entretanto, a utilização de Data Warehouses não está restrita apenas a grandes corporações.
É vital que pequenas e médias empresas também adotem esse modelo para a implementação de seus bancos de dados gerenciais.
Essa abordagem é fundamental para assegurar a integridade das informações em seus sistemas de gestão, proporcionando uma base de dados confiável e estruturada, essencial para uma análise de negócios eficaz e decisões bem informadas.
A adoção de Data Warehouses, portanto, é uma estratégia valiosa para empresas de todos os tamanhos que buscam aprimorar sua capacidade de gerenciamento e análise de dados.
Créditos
Criação Textual:
Participação externa - Especialista de mercado:
Produção técnica:
Produção didática:
Designer gráfico:
Apoio: