O que é um pipeline de dados?


Com a crescente necessidade de lidar com grandes quantidades de dados, a engenharia de dados tem ganhado cada vez mais relevância no mercado. A cada dia novas tecnologias surgem, e aumentamos a quantidade de dispositivos e sensores conectados, gerando uma quantidade considerável de dados. Empresas e organizações têm acesso a uma quantidade exponencial de informações provenientes de fontes diversas. No entanto, lidar com esses dados de maneira eficiente e eficaz requer uma abordagem estruturada. Nesse contexto, surge o conceito de pipeline de dados, uma solução estratégica para gerenciar o fluxo de informações em todas as áreas relacionadas aos dados.
Componentes de um pipeline de dados
Um pipeline de dados é uma sequência de etapas interconectadas que permitem a coleta, armazenamento, transformação, análise e visualização de dados, com a intenção de facilitar o fluxo contínuo e automatizado de informações, desde a sua origem até o destino final, a fim de obter insights valiosos e tomar decisões informadas.
O principal objetivo de um pipeline de dados é fornecer uma estrutura eficiente e confiável para lidar com grandes volumes de dados, garantindo sua integridade, segurança e acessibilidade. Mas, independente da ordem do fluxo que escolhemos, um pipeline de dados conta com alguns componentes principais como fontes de dados, transformações e destinos.
Fontes de dados
Dentro de um pipeline, os dados podem ser coletados de diferentes fontes, como aplicativos, bancos de dados, APIs e webhooks. Cada fonte envia informações para o pipeline de forma programada ou em tempo real, dependendo dos requisitos do projeto. A coleta pode ser sincronizada para permitir o processamento em tempo real ou agendada em intervalos regulares para coletar dados periodicamente.
Transformações
A etapa de transformação ocorre após a coleta dos dados. Aqui, os dados brutos podem passar por várias operações e transformações para se tornarem algo mais útil para análise e tomada de decisões. Durante essa etapa, podem ser aplicadas operações como classificação, formatação dos dados, remoção de itens duplicados, validação e agregação. O objetivo principal é moldar os dados de acordo com os requisitos específicos do projeto e garantir que eles estejam em um formato adequado para o uso.
Destinos
Os destinos são os locais onde os dados processados e transformados são armazenados para acesso futuro e análise. Isso pode incluir data warehouses, data lakes ou outras aplicações de análise de dados e business intelligence. Esses destinos servem como pontos de coleta para os dados transformados, permitindo que sejam facilmente consultados e explorados posteriormente. São os dados transformados, contidos nos destinos, que fornecem a base para a geração de insights e a tomada de decisões. Caso queira ler um pouco mais sobre data lakes e data warehouses, o Allan Spadini fez um artigo sobre Data Lake vs Data Warehouse e recomendo também o Alura+ em que a Millena Gená e do João Miranda falam sobre O que são Data Lakes?.
É importante destacar que esses são os componentes principais de um pipeline de dados, mas um pipeline pode variar em complexidade e detalhamento, ou seja, até mesmo a ordem que as etapas de um pipeline serão executadas vai depender das necessidades específicas de cada projeto.

Fluxo de um pipeline de dados
O pipeline de dados segue várias etapas essenciais desde a obtenção dos dados brutos até a disponibilização de insights e resultados. Duas abordagens comuns para esse fluxo são o ETL (Extract, Transform, Load) e o ELT (Extract, Load, Transform).
ETL: Extract, Transform, Load (Extrair, Transformar, Carregar)
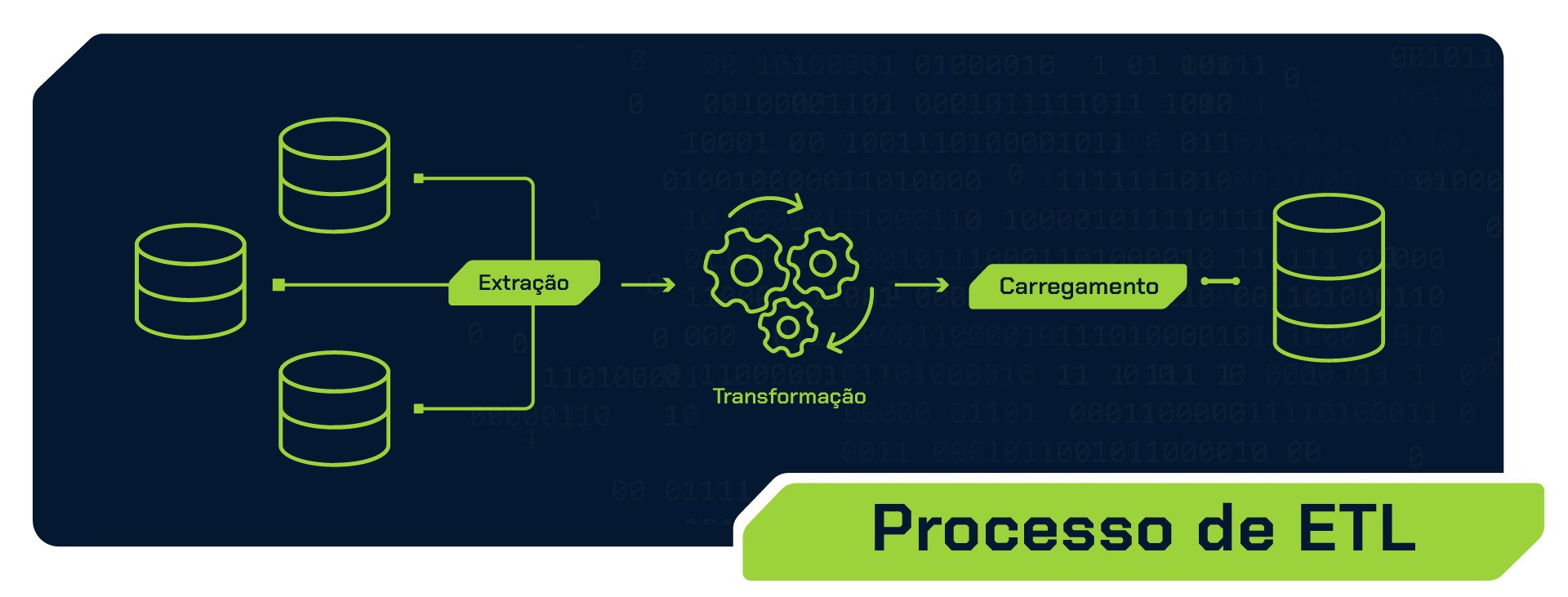
O processo ETL se inicia com a extração dos dados brutos de uma ou várias fontes, como aplicativos, bancos de dados ou APIs. Em seguida, ocorre a etapa de transformação, na qual os dados passam por etapas de processamento, limpeza, filtragem, normalização e agregação. Durante essa fase, também é possível integrar informações de diferentes fontes para garantir consistência.
Após a transformação, os dados são carregados em um destino final, para um local de armazenamento, onde ficam prontos para análise e consulta. Esse passo é especialmente útil quando há uma carga de trabalho intensa na transformação ou quando os requisitos de análise demandam uma remodelagem significativa dos dados antes da realização das análises.
ELT: Extract, Load, Transform (Extrair, Carregar, Transformar)
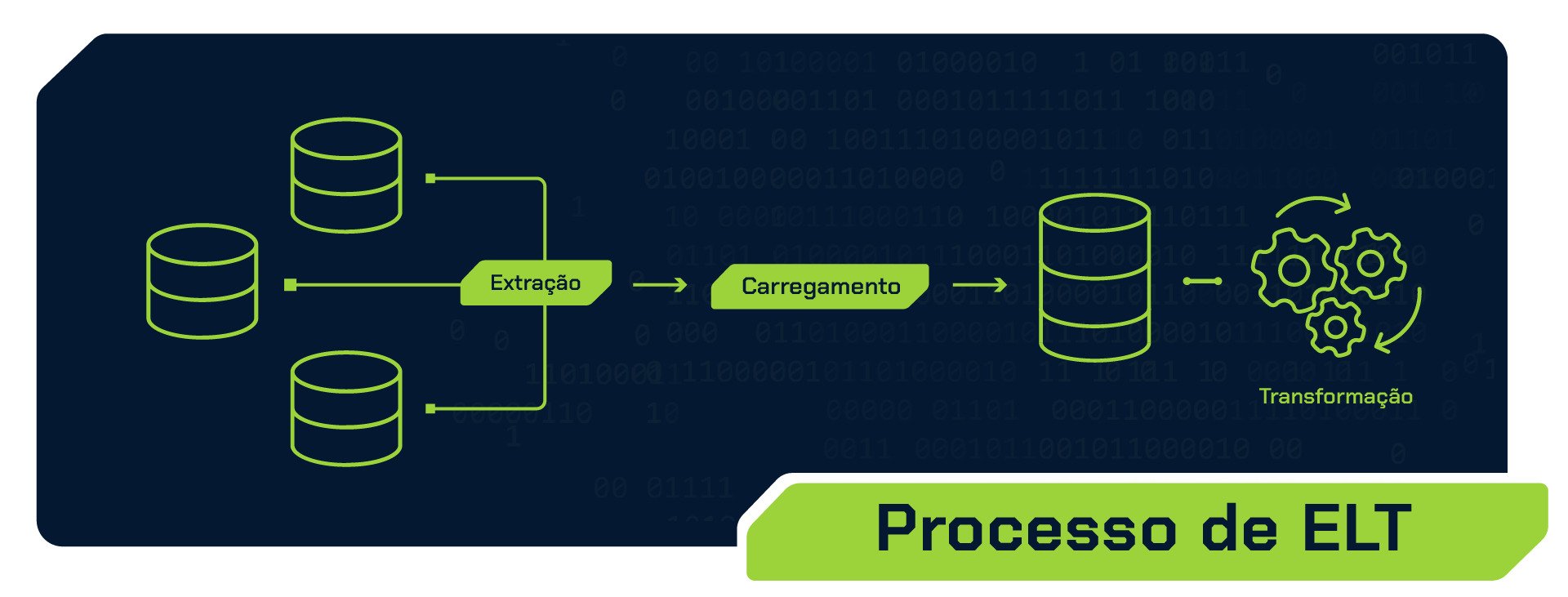
No caso do ELT, o fluxo é ligeiramente diferente. Como no pipeline ETL, começamos pela extração dos dados brutos das fontes. Mas, diferente do fluxo do ETL, na etapa seguinte, os dados são carregados diretamente em um destino final. Nesse momento, os dados são armazenados em seu formato original, sem passar por transformações imediatas.
Esse tipo de fluxo é interessante em cenários de streaming, em que os dados são capturados e carregados em tempo real em um destino final. Dessa forma, os dados brutos são imediatamente disponibilizados para análise, e as transformações podem ser realizadas sob demanda, quando necessário. Essa abordagem oferece uma resposta rápida às necessidades de análise em tempo real, permitindo tomar decisões de forma rápida e aproveitar as oportunidades de forma eficiente.
Ao decidir qual fluxo utilizar para o seu pipeline de dados, é essencial levar em consideração as necessidades e objetivos específicos do projeto. Ao avaliar cuidadosamente esses fatores, você poderá selecionar o fluxo que melhor atenda às necessidades específicas de dados, análise e tomada de decisões do seu projeto. O custo, desempenho e modelagem de dados também devem ser levados em conta para fazer a escolha adequada. Esses fatores são fortemente relacionados às ferramentas envolvidas na implementação do pipeline.
Principais ferramentas
Para pequenos projetos, especialmente durante o processo de aprendizagem, é possível montar um pipeline completo utilizando apenas manipulação de bancos de dados e scripts Python personalizados para a extração, transformação e carga de dados. No entanto, com o aumento da demanda por soluções mais robustas e complexas, surgiram ferramentas poderosas, como:
Apache Airflow: uma plataforma de orquestração de fluxos de trabalho que permite agendar, monitorar e gerenciar pipelines de dados de forma flexível e extensível. Ele usa uma abordagem baseada em código para definir tarefas e dependências, o que o torna uma ferramenta poderosa para criar fluxos de trabalho complexos e dinâmicos.
Databricks: uma ferramenta muito utilizada na parte de processamento de dados, é uma plataforma de análise de dados baseada em Apache Spark, projetada para permitir o processamento e análise distribuída de grandes volumes de dados. Ele oferece um ambiente de colaboração para cientistas de dados, engenheiros e analistas trabalharem juntos em projetos de big data.
Azure Data Factory: um serviço de orquestração de fluxos de trabalho de dados da Microsoft, projetado para simplificar a ingestão, transformação e carga de dados entre várias fontes e destinos, como bancos de dados, serviços em nuvem e sistemas de armazenamento.
AWS Glue: um serviço totalmente gerenciado pela Amazon Web Services, que facilita a preparação e movimentação de dados entre diferentes fontes e destinos, permitindo criar transformações em grande escala.
Saber utilizar essas ferramentas pode ser interessante para que as organizações obtenham benefícios significativos, como maior produtividade, processamento de dados em escala e capacidade de lidar com requisitos complexos de transformação e análise. Essas soluções também oferecem recursos de monitoramento, agendamento e recuperação de falhas, aprimorando a confiabilidade e a eficiência do pipeline de dados.
A engenharia de dados desempenha um papel crucial na gestão eficiente e na obtenção de insights valiosos em um mundo orientado por dados. Nesse sentido, os pipelines são ferramentas essenciais ao possibilitarem a coleta, transformação e armazenamento estruturado das informações. Com uma abordagem definida e o uso de ferramentas apropriadas, as empresas podem maximizar o potencial dos dados, impulsionando decisões informadas, identificando tendências e oportunidades de negócio. Essas estruturas garantem a integridade, segurança e acessibilidade dos dados, otimizando a análise de grandes volumes e transformando-os em conhecimentos acionáveis.
Créditos
- Conteúdo: Paulo Calanca
- Produção técnica: Rodrigo Dias e Millena Gená
- Produção didática: Thaís de Faria
- Designer gráfico: Alysson Manso