Técnicas de Bagging e Boosting em Machine Learning

Imagine que você está prestes a comprar um novo smartphone e encontra opções no mercado, cada uma com suas próprias especificações, recursos e preços.
Diante dessa diversidade de escolhas, você não tomaria uma decisão precipitada comprando o primeiro smartphone que vê, confiando apenas na opinião de uma pessoa, por exemplo.
Em vez disso, você provavelmente tomaria um tempo para pesquisar, comparar análises de diferentes fontes e ouvir as opiniões de amigos que já possuem smartphones.
Da mesma forma, na área de Machine Learning, quando se trata de avaliar resultados de diversas fontes para obter um resultado final, utilizamos uma técnica chamada de Ensemble.
Assim como você não confiaria em uma única fonte de informação ao escolher um smartphone, os métodos Ensemble combinam as previsões de vários modelos de machine learning para obter resultados mais precisos e confiáveis. Neste artigo, vamos apresentar dois desses métodos: Bagging e Boosting.
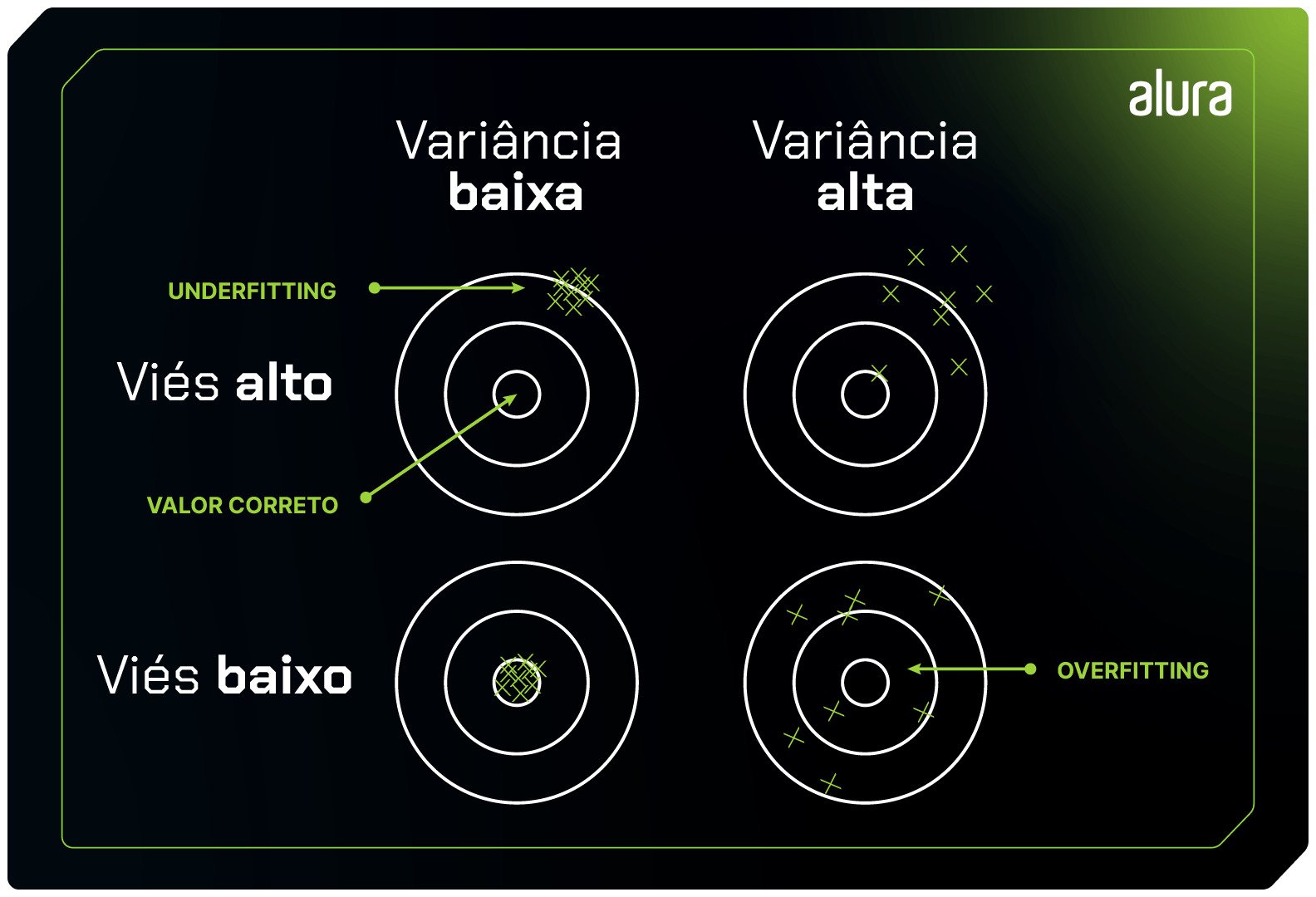
Relação entre variância e viés
A relação entre viés e variância em modelos de machine learning é uma parte fundamental da compreensão do desempenho e da generalização desses modelos. Esses conceitos estão relacionados à capacidade de um modelo se ajustar aos dados de treinamento e à sua capacidade de generalizar para dados não observados.
Viés (Bias): O viés refere-se à tendência de um modelo fazer suposições simplificadas sobre os dados, o que pode levar a erros sistemáticos. Um modelo com alto viés tende a subestimar ou superestimar consistentemente os valores reais dos dados. Isso pode acontecer quando o modelo é muito simples para capturar a complexidade dos dados. Modelos de baixa complexidade, como regressão linear simples, geralmente têm alto viés.
Variância: A variância está relacionada à sensibilidade de um modelo às variações nos dados de treinamento. Um modelo com alta variância se ajusta muito bem aos dados de treinamento, mas não generaliza bem para novos dados. Isso pode ocorrer quando o modelo é muito complexo e captura até mesmo o ruído presente nos dados de treinamento. Modelos de alta complexidade, como árvores de decisão profundas ou redes neurais complexas, tendem a ter alta variância.
A relação entre viés e variância pode ser visualizada através do conceito de "trade-off" entre eles:
Baixo Viés e Alta Variância: Modelos com baixo viés e alta variância têm a capacidade de se ajustar muito bem aos dados de treinamento, mas eles tendem a se comportar mal em dados não vistos, devido à sua sensibilidade às variações. Isso resulta em overfitting, onde o modelo memoriza o ruído nos dados de treinamento.
Alto Viés e Baixa Variância: Modelos com alto viés e baixa variância são mais simplificados e não se ajustam bem aos dados de treinamento. Eles geralmente não capturam a complexidade dos dados e, portanto, não generalizam bem. Isso resulta em underfitting, onde o modelo não consegue aprender os padrões presentes nos dados.
Equilíbrio entre Viés e Variância: O objetivo é encontrar um equilíbrio entre viés e variância, resultando em um modelo que se ajuste adequadamente aos dados de treinamento e generalize bem para novos dados. Isso envolve escolher a complexidade apropriada do modelo e ajustar seus hiperparâmetros conforme necessário.
A seguir, temos uma figura que representa a relação entre o viés e a variância, onde podemos identificar onde ocorre tanto o Underfitting quanto o Overfitting.

Métodos Ensemble
Um algoritmo que utiliza vários modelos em conjunto com o objetivo de obter um modelo final com melhores resultados é chamado de método Ensemble. O processo envolve a criação de um conjunto de modelos, que pode ser composto por diferentes algoritmos ou variações do mesmo algoritmo.
Os modelos que são combinados através desse método são chamados modelos base. Geralmente, esses modelos obtêm resultados apenas um pouco melhores do que uma classificação aleatória. Logo abaixo, podemos analisar o funcionamento de um método ensemble.

Ao tomar decisões importantes, é útil considerar diferentes pontos de vista. Por exemplo, podemos pensar na predição do preço de imóveis. Nesse caso, precisamos estar atentos a várias características da propriedade (como tamanho, configuração, estado de conservação etc.), bem como para características do entorno destes imóveis, para ajudar a prever o preço adequadamente.
Entretanto, confiar em apenas um modelo preditivo pode não ser a melhor decisão, pois ele pode não ser suficiente para estimar os preços dos imóveis.
Assim como as decisões embasadas tendem a ser mais sólidas, os métodos Ensemble também seguem essa abordagem. Nesse caso, utilizamos as predições do preço de imóveis de vários modelos preditivos para obter uma predição final mais precisa.
Com isso, a ideia dos métodos Ensemble é combinar vários modelos base para obter um modelo final aprimorado. Dois métodos populares são o Bagging e o Boosting, cada um com sua abordagem única para a combinação de modelos e aprimoramento do desempenho.
Bagging
Trata-se de uma técnica de Ensemble que visa reduzir a variância e, assim, evitar o overfitting. No Bagging, várias instâncias do mesmo algoritmo são treinadas paralelamente em subconjuntos aleatórios e independentes dos dados de treinamento. Esses subconjuntos são criados por meio de amostragem com reposição, o que significa que um mesmo dado pode aparecer em múltiplos subconjuntos, como pode ser analisado na sequência.
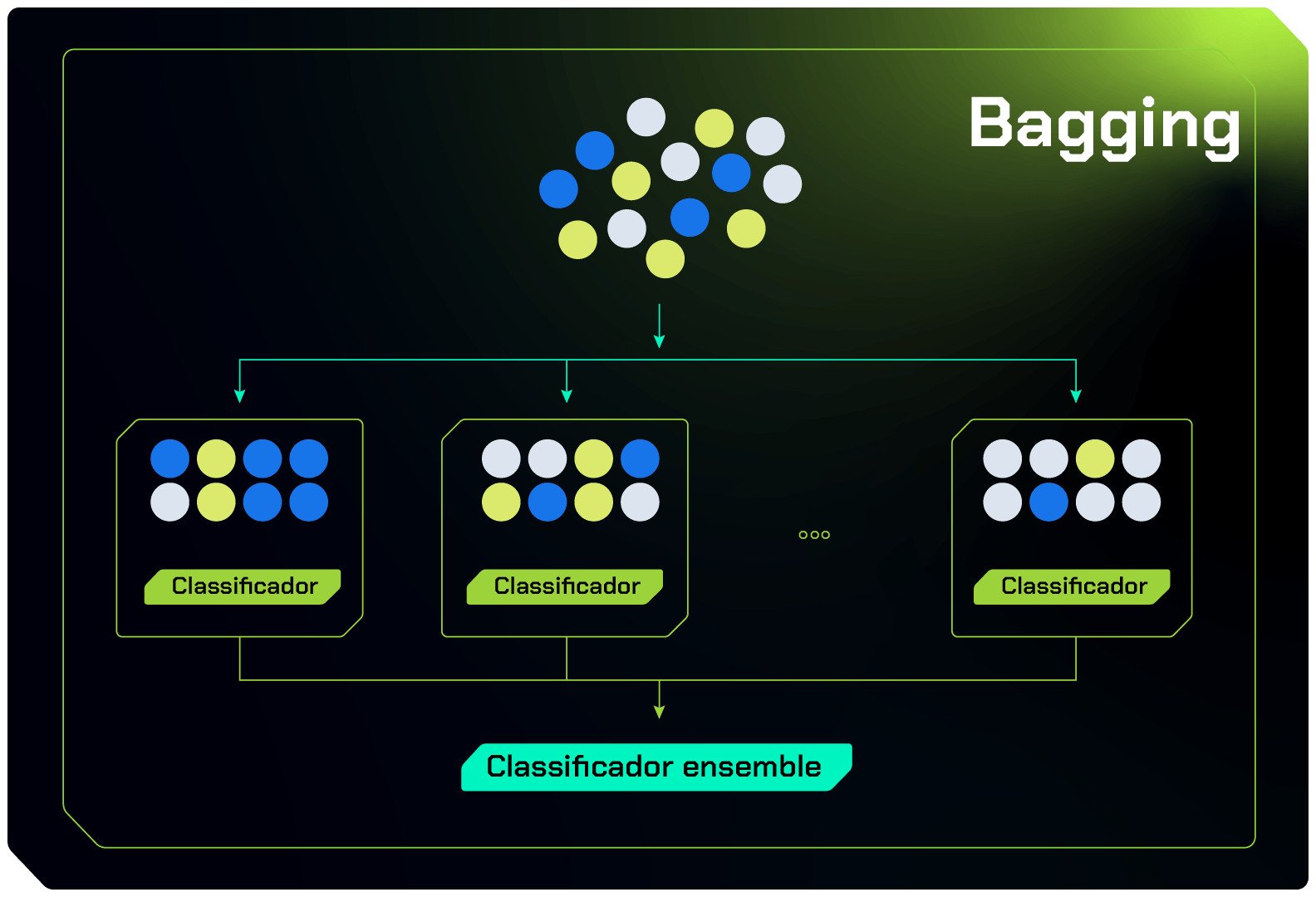
Os resultados desses modelos base, como se pode analisar na imagem acima, são combinados por média (para problemas de regressão) ou por votação (para problemas de classificação), resultando em uma previsão final mais estável e geralmente mais precisa.
Um exemplo de algoritmo que faz uso da técnica de Bagging é o RandomForest, que utiliza conjuntos de árvores de decisão. Quando várias árvores se juntam, formam uma floresta (forest). As árvores que compõem uma floresta podem ser rasas (com poucos níveis) ou profundas (com muitos níveis).
A abordagem do RandomForest é um método de Bagging em que árvores profundas, ajustadas em amostras com reposição, são combinadas para produzir uma saída com menor variância. Por esse motivo, esse algoritmo é conhecido por sua capacidade de lidar com o overfitting.
Como exemplo prático, vamos supor que estamos trabalhando em um problema de classificação de imagens para distinguir entre gatos e cachorros. Com o RandomForestClassifier, podemos construir diversas árvores de decisão independentes, cada uma delas examinando diferentes características dos pacientes.
Posteriormente, essas árvores individuais se unem, combinando suas decisões através de votação, para gerar uma classificação final mais robusta e precisa. Podemos conferir o código desse exemplo logo abaixo:
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Carregar os dados
data = load_digits()
X = data.data
y = data.target
# Dividir os dados em conjuntos de treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Criar o modelo RandomForest
model = RandomForestClassifier(n_estimators=100, random_state=42)
# Treinar o modelo
model.fit(X_train, y_train)
# Fazer previsões
predictions = model.predict(X_test)
# Avaliar a precisão
accuracy = accuracy_score(y_test, predictions)
print(f"Precisão do RandomForest: {accuracy:.2f}")
Boosting
Trata-se dos modelos base que são treinados de forma sequencial, em que cada modelo se concentra em corrigir o modelo anterior. Isso significa que os modelos seguintes dão mais atenção aos dados que foram classificados incorretamente nas etapas anteriores, como se pode reconhecer na imagem abaixo:

À medida que as iterações acontecem, o modelo Ensemble aprimora a sua capacidade de lidar melhor com os padrões complexos nos dados, resultando em uma melhoria contínua no seu desempenho. Assim como um atleta que treina incansavelmente para se tornar cada vez mais habilidoso, ele aprimora sua performance passo a passo.
No caso do Boosting, temos como exemplo o AdaBoost (Adaptive Boosting), que é um algoritmo que atribui pesos diferentes aos dados durante o treinamento. Ele começa treinando um modelo fraco e, em seguida, atribui pesos maiores aos exemplos classificados incorretamente pelo modelo fraco anterior.
Os modelos seguintes são treinados para focar nos erros cometidos pelos modelos anteriores. O AdaBoost é capaz de melhorar o desempenho de modelos fracos, criando um modelo final mais forte e preciso.
Como exemplo prático, vamos seguir o mesmo exemplo utilizado anteriormente. Abaixo, podemos conferir o código do AdaBoost:
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# Carregar os dados
data = load_digits()
X = data.data
y = data.target
# Dividir os dados em conjuntos de treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Criar o modelo base (mais complexo)
base_model = DecisionTreeClassifier(max_depth=5, random_state=42)
# Criar o modelo AdaBoost com o modelo base
model = AdaBoostClassifier(base_model, n_estimators=50, random_state=42)
# Treinar o modelo
model.fit(X_train, y_train)
# Fazer previsões
predictions = model.predict(X_test)
# Avaliar a precisão
accuracy = accuracy_score(y_test, predictions)
print(f"Precisão do AdaBoost: {accuracy:.2f}")
Principais diferenças
Para resumir as principais diferenças entre os métodos Bagging e Boosting, podemos conferir a tabela abaixo:

Como podemos perceber, enquanto o Bagging foca na redução da variância, construindo modelos independentes que são agregados via média ou votação, o Boosting se concentra na mitigação do viés, sequencialmente ajustando modelos para corrigir erros anteriores com uma média ponderada. Além disso, o Bagging tende a ser menos sensível ao overfitting, enquanto o Boosting pode apresentar maior sensibilidade.
Conclusão
Os métodos Ensemble constituem uma abordagem fundamental para aprimorar a performance dos modelos, pois combinam múltiplos modelos base em um único modelo final.
Neste artigo, exploramos como a relação entre o viés e a variância nos modelos, também chamada de “trade-off”, está relacionada com a capacidade de um modelo se ajustar à complexidade dos dados de treinamento e a lidar com dados novos.
A partir disso, conhecemos dois métodos ensemble que buscam o equilíbrio nessa relação: o Bagging e o Boosting. Enquanto o Bagging opera em paralelo, visando mitigar a variância por meio da média ou votação das previsões, o Boosting adota uma abordagem sequencial, buscando a redução do viés por meio de iterações corretivas.
A escolha entre esses métodos deve ser guiada pela natureza dos dados e objetivos específicos do modelo.
E aí, curtiu a leitura? Aqui na Alura temos muitos outros conteúdos para te ajudar a estruturar seus conhecimentos em Machine Learning. Bora mergulhar em tecnologia? Venha estudar conosco! 🤿
Créditos
- Conteúdo: Marcelo Cruz
- Produção técnica: Rodrigo Dias e Bruno Raphael
- Produção didática: Cláudia Machado
- Designer gráfico: Alysson Manso