Olá, pessoas! Boas-vindas!! Meu nome é Camila, eu sou doutoranda em Ciência da Computação na Federal de Minas Gerais e eu também dou aula de deep learning desde 2018 lá na UFMG.
Esse curso aqui é sobre redes neurais recorrentes, que são o tipo de rede neural adequada para você trabalhar com dados sequenciais.
Inclusive, nós vamos começar falando o que são dados sequenciais e vamos dar um pouco de destaque a mais para o texto, que é uma das aplicações onde as redes recorrentes tiveram mais sucesso de longe. Vamos falar da motivação para se usar essas redes recorrentes e não uma rede multilayer perceptron simples.
Aliás, um aviso muito importante: esse curso tem pré-requisitos fortes, mas todos os pré-requisitos já existem aqui na Alura, que é o primeiro curso de deep learning que eu fiz aqui; onde eu falo do perceptron, dos elementos de uma rede neural, como funções de perda, funções de otimização. Nada disso eu vou entrar em detalhes aqui nesse curso, mas está tudo lá.
E eu também não vou explicar o passo a passo do treinamento de uma rede neural, eu vou focar mesmo nas particularidades dos dados de sequência, como as redes recorrentes resolvem essas questões e quais são os benefícios de se usar uma rede recorrente.
A nossa primeira prática vai ser uma rede que vai processar caractere por caractere de uma palavra para classificar a nacionalidade daquela palavra. São sobrenomes e nós queremos saber qual é a nacionalidade daquele sobrenome.
Para isso, vamos usar uma RNN ao nível de caractere, que foi uma das primeiras grandes arquiteturas, um dos primeiros grandes usos da RNN que se conhece.
Até aqui vai ser uma abordagem um pouco mais de didática, mas a partir daqui nós já vamos entrar em aplicações do mundo real, como análise de sentimentos que, aliás, vai ser a nossa segunda grande prática desse curso.
Mas primeiro, vamos entender na teoria quais são as variações na arquitetura de uma rede recorrente, o que acontece dentro das unidades avançadas que as tornam tão melhores; se formos comparar uma LSTM, que é uma unidade avançada, com uma rede recorrente simples.
Vamos falar também das variantes - como a RNN Bidirecional, a RNN Profunda, ou seja, com mais de uma camada. Nós vamos finalizar com a nossa super prática de classificação de texto e análise de sentimentos.
E vamos aprender um conhecimento essencial. Se você vai trabalhar com dados de sequência, que é como você lida com sequências de tamanho variável, quais são os artifícios que o Pytorch te oferece para você conseguir empacotar essas sequências e aproveitar o máximo da eficiência do uso de redes neurais - que é o seu poder de paralelismo.
Um último aviso é que tem bastante coisas no “saiba mais” desse curso, então fique de olho e não deixe de fazer os exercícios, só para dar aquela checada de sanidade e ver se você está conseguindo acompanhar bem. É isso, que seja um bom curso para todos nós!
Vamos falar um pouco de redes neurais recorrentes, começando pela parte muito importante, que o tipo de dado que eu vou conseguir processar, que eu vou até conseguir gerar usando esse tipo de rede neural.
Então nós vamos falar um pouco sobre o que é uma sequência, em termos práticos para nós, que é o tipo de dado que nós podemos processar usando redes neurais recorrentes.
Para entendermos os tipos de perguntas que podemos responder ou o tipo de dado que podemos processar usando esse tipo de rede, tem esse exemplo muito clássico, que é: em que direção essa bola verde que está na tela está indo?
É uma pergunta que nós não conseguimos responder com a informação que temos na mão. O que temos na mão? Temos um evento único, que é o instante da posição da bola (tempo = 4). Com essa informação nós não conseguimos responder à pergunta, nós precisamos criar aqui o conceito de instante de tempo.
Então temos aqui que essa é a posição da bola no “tempo = 4”. Precisamos conhecer também o que aconteceu em outros instantes do tempo. Aqui temos o “tempo = 3”, o “tempo = 2” e o “tempo = 1”.
Então com vários eventos na ordem correta nós conseguimos responder perguntas como qual a direção que a bola está indo. É isso que você precisa olhar no seu dado e na pergunta que você quer responder, para saber se a rede recorrente é o tipo de rede certa.
Vamos expandir um pouco mais, para que fique claro nos tipos de dados que podemos trabalhar usando essas redes. Um exemplo muito comum para entendermos o que é essa memória de sequência, é recitar o alfabeto. Quando você recita o alfabeto, você vai à corrida: A, B, C, D, E, F, G, H, I... Você nem pensa direito para falar.
Já, se eu te peço para recitar o alfabeto de trás para frente, você vai demorar. Eu, pelo menos, vou demorar bastante de lembrar, que é: Z, Y, X, W, V, U... É um negócio que você não memorizou a sequência nessa ordem, então é algo mais difícil para você recitar.
Se eu te pedir para recitar a partir da letra Q, pessoalmente eu vou dar uma corrida na minha cabeça com o início do alfabeto e daí por diante vou engatar: Q, R, S, T, U, W, V... Aí vai.
Então no começo você vai lutar um pouco com as primeiras letras, mas depois que seu cérebro entender e pegar aquele padrão, você vai conseguir engatar - igual você engataria com o alfabeto desde o início.
Isso acontece com muitos outros dados, muitas outras coisas do nosso dia a dia que indicam a presença de uma memória de sequência. Tem uma razão muito lógica para isso ser difícil: você aprendeu essas coisas como uma sequência e a existência das letras individuais não é o que faz você saber o alfabeto, é a sequência que você foi ensinado.
Os seres humanos têm esse conceito de memória sequencial, que é um mecanismo que torna mais fácil para o cérebro reconhecer os padrões. De novo - eventos individuais, nesse caso, significam muito pouco; uma letra significa muito pouco sobre o alfabeto, mas a sequência de letras é o que define o alfabeto que conhecemos.
Aqui temos uma série de outros eventos que apresentariam essa mesma dificuldade, como o alfabeto, uma letra de música. Se você tivesse que cantar uma música fora de ordem, por exemplo, seria um pouco problemático.
Mais exemplos que podemos pensar e eu penso rapidamente, são: em números de telefone, CPF e senhas. Então nós vamos falar de tipos de dados que na prática vamos usar redes recorrentes para processarmos.
Nós vamos falar de um conceito muito importante agora, que é o conceito de unidade atômica desse dado. Um tipo de dado, por exemplo, é o texto. As redes neurais recorrentes são muito populares por processamento de texto.
Tem a GPT-3, por exemplo, que a partir de uma entrada consegue um primeiro parágrafo, gerar um texto completo, simplesmente interpretando o que aquele primeiro parágrafo significa.
Aqui temos um exemplo de um parágrafo, que não foi por acaso que eu escolhi, porque fala sobre a Ada Lovelace: Ela foi uma matemática e escritora inglesa, hoje é reconhecida por ter escrito o primeiro algoritmo para ser processado por uma máquina, a máquina analítica de Charles Babbage.
Esse texto aqui, para que nós transformemos em um dado que a rede neural vai conseguir processar, a primeira coisa que precisamos detectar é o que é uma unidade atômica.
Podemos dizer que o evento único desse texto, o evento indivisível, são as palavras: “Ada”, “Lovelace”, “foi”, “uma”, “matemática”, “...”. Cada palavra do meu texto vai ser um elemento da minha sequência que acontece em um instante de tempo.
A palavra “Ada” aconteceria no “tempo = 0” ou no “tempo = 1”, se você preferir. “Lovelace” aconteceria no “tempo = 2” e a palavra “foi” no “tempo = 3”. Do mesmo jeito que a bola tem uma sequência, as letras também têm uma sequência que nós associamos a instantes de tempo mesmo, para indicar que eles acontecem do passado para o futuro.
Ou eu posso dizer também que os elementos atômicos são as letras, que cada uma dessas letras acontece em um instante de tempo, então: “A”, “d”, “a”, “L”, “o”, “v”, “e” e daí por diante. Teríamos uma sequência de letras, e não de palavras.
Inclusive, os primeiros modelos usando redes neurais recorrentes para texto interpretavam por caractere aquele texto. Posteriormente nós veremos porque é mais difícil interpretarmos como palavras do que como caracteres.
E mais um tipo de dado seria uma partitura de música. A música eu acho muito interessante, porque se eu te perguntar qual é o elemento atômico de uma partitura de música, talvez o primeiro instinto das pessoas é dizerem que é a nota da música, que é um dó ou um fá.
Só que tem um conceito que é mais importante e mais forte aqui quando nós estamos falando de processamento de dados e sequência, que são os instantes no tempo. Qual é o evento único que acontece em um instante de tempo da música? Não é uma nota, é um conjunto de notas!
Esse conceito precisa estar bem definido para, na hora em que você olhar para o seu dado, você conseguir separar o que é um evento que você precisa processar com a sua rede. No caso da música, são várias notas que são tocadas ao mesmo tempo.
Temos a voz também, que podemos brincar com o conceito de dimensionalidade do dado. Porque a voz pode ser representada como um sinal, um “D”, um sinal com uma única dimensão, que é a amplitude desse sinal. A cada instante do tempo, eu tenho um número, que é a amplitude da voz.
Ou eu posso representar exatamente esse mesmo dado como um espectrograma, que você não precisa entender exatamente o que é, mas ele mapeia várias frequências de sinal em um único instante de tempo.
Para um ter “tempo = 1” temos inúmeras frequências de sinais que estamos mapeando - que no espaço da amplitude, que é a primeira representação que vimos, equivaleria a um número só. A dimensionalidade vai variar de acordo com como você representa o seu dado.
Temos outro exemplo, onde essa questão da dimensionalidade fica mais clara, que é um eletroencefalograma. Eu vou chutar aqui que tem 20 neurônios, onde cada linha é um neurônio diferente.
Para cada neurônio, é um sinal, um “D”; é um número a cada instante de tempo. Mas como estamos mapeando 20 neurônios de uma vez, a cada instante de tempo nós iríamos mapear 20 dimensões ao mesmo tempo, cada dimensão referente a um neurônio.
É interessante olharmos esse tipo de coisa, o que é um evento e associarmos o evento a um instante do tempo - que é o que vai definir que estamos lidando com uma sequência e que a rede neural recorrente é adequada.
Esses são dois conceitos que precisam existir na sua cabeça. Temos eventos únicos e atômicos, que têm uma relação entre si e a ordem deles é um fator relevante.
E o papel da rede neural é justamente mapear, entender e processar qual é a relação entre esses eventos; para ser capaz de classificar aquele evento, por exemplo, se a música é jazz ou é rock, ou para ser capaz de gerar novos eventos - que seria o caso de gerar novos parágrafos para um texto - e daí por diante.
É isso que nós vamos falar ao longo desse curso!
No vídeo anterior, nós falamos que as redes neurais recorrentes são ideais para nós lidarmos com sequências. Agora nós vamos falar porque isso é verdade.
Vamos entender porque eu não posso simplesmente usar a rede neural tradicional, aquela totalmente conectada - que se você não conhece muito bem, saiba que nós temos um curso aqui na Alura que fala sobre fundamentos de redes neurais e nele você consegue entender melhor o que é e quais são as limitações da rede tradicional.
Mas vamos falar especificamente de dados de sequência. Para isso, eu vou usar o problema de rotulação de sequências, que basicamente é pegar cada evento individual dessa minha sequência e dar um rótulo.
No caso do texto “Nós fizemos um acordo”, eu decidi dar um rótulo sintático aqui. Por exemplo: a palavra “Nós” eu vou dizer que é um pronome, que a palavra “fizemos” é um verbo, a palavra “um” é artigo indefinido e a palavra “acordo” é substantivo.
Agora vamos focar na palavra “acordo” e como ela vai mudar de significado, o rótulo dela vai mudar segundo o contexto que ela está inserida.
Se eu tenho a frase “Eu acordo cedo” - inclusive, no português, falamos diferente porque ela tem outro significado; ela é a conjugação de um verbo, mas ela escreve exatamente do mesmo jeito. No texto eu só tenho como saber que a sintaxe mudou porque eu tenho um contexto aqui para associar.
Nesse caso seria: “Eu” como um pronome, “acordo” seria um verbo e a palavra “cedo” seria um advérbio. Então eu tenho uma palavra aqui que mudou de rótulo de acordo com o contexto.
E se eu usasse um multi layer perceptron, que é a rede neural tradicional, para conseguir solucionar esse problema de rótulo sintático para palavras em um texto? Vamos tentar ver!
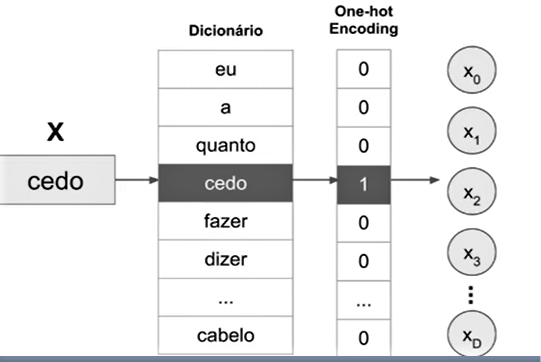
Primeiro vamos transformar essas unidades atômicas em dados numéricos. Aqui nós já começamos a entender que para uma rede neural receber um dado, precisamos dar uma representação numérica para ele, porque tudo na rede são números. Por mais que eu esteja lidando com um texto, tenho que transformá-lo em um vetor numérico.
No caso da unidade atômica ser em forma de palavras, a maneira mais simples de você representar a palavra numericamente é criando um dicionário - que é esse que estamos vendo aqui no meio.
Literalmente, o dicionário são todas as palavras que você quer mapear no seu problema. Isso seria o seu dicionário do idioma, digamos assim, ou das palavras mais importantes do idioma. Eu vou representar cada palavra com um vetor todo de números 0 com o número 1 somente na posição referente onde aquela palavra se encontra no dicionário.
Eu tenho aqui com “0” não é a palavra “eu”, “0” não é a palavra “a”, “0” não é a palavra “quanto” e “1” é a palavra “cedo”. Na direita nós vamos ter uma representação vetorial, vamos ter um vetor X, que vai ter X0, X1, X2 - e esse setor vai ser todo preenchido com 0, exceto na posição da palavra no dicionário.
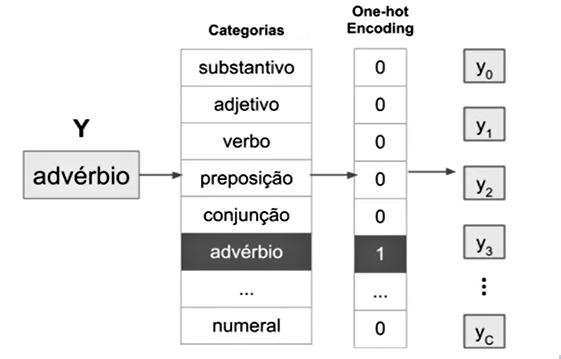
Nós vamos fazer o mesmo com as categorias de rótulo sintático, vamos criar um dicionário, digamos assim, de categorias e vamos criar a mesma representação - que se chama representação One-hot, que vai ativar só na posição daquela categoria.
Essa é uma representação muito comum para problemas de classificação - que é o nosso caso aqui, nós queremos classificar palavras. Então à direita de novo temos um vetor Y, que é o vetor de saída e que só está ativado na posição daquela categoria.
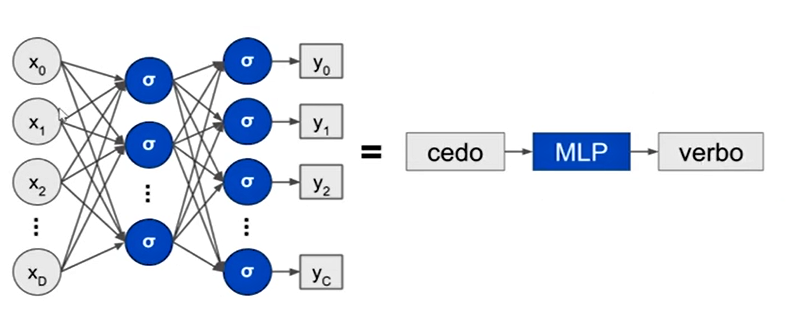
Agora vamos simplificar a representação da rede neural, só para facilitarmos o que vem adiante. Sempre que virmos essa sequência de retângulos, a entrada, o MPL e a saída, isso significa um vetor do tamanho do meu dicionário de palavras, uma rede totalmente conectada que pode ter qualquer número de camadas, qualquer número de neurônios; e o meu vetor de saída, que vai ter o tamanho da quantidade de categorias do meu problema.
Vamos na primeira tentativa de solucionar esse problema usando uma rede neural tradicional. Vamos aplicar à rede um elemento de cada vez, que é como se usa esse tipo de rede - nós damos uma entrada e essa entrada vai gerar uma saída.
Nessa tentativa, o que significa é que não estamos fazendo nenhuma associação entre palavras (entrada: Eu; MLP; saída: pronome), tanto faz para a rede neural a ordem que ela vai ver essas palavras porque ela não guarda nenhuma memória.
Então “eu” vai dar uma entrada, a palavra “eu” - lembrando que ela é um vetor gigante - vai processar com a minha rede neural e ela vai me dar uma saída, que é uma categoria.
Vou para a próxima palavra, vou dar a entrada, vou processar e ela vai me dar uma saída, dizendo nesse caso aqui que “acordo” é um substantivo. Porque “acordo” pode ser um substantivo em algum momento, mas não nesse caso.
“Cedo” vai me dizer que é um verbo, que é do verbo “ceder”, que poderie ser um verbo, mas nesse caso, não.
Então tanto faz se eu alimentar em qualquer ordem aqui a rede neural, porque ela não tem noção do que vem primeiro e do que vem depois, ela não guarda nenhum registro daquele processamento.
A limitação dessa abordagem é que esse modelo não vai incorporar relação entre palavras, já que ele recebe uma palavra de cada vez e atualiza seus pesos de acordo com a informação individual de cada palavra.
Essa é a forma que nós treinamos tradicionalmente as redes, porque no caso de classificação de imagens queremos que cada entrada individualmente seja processada do zero, digamos assim, nós não queremos nenhum vestígio de processamentos anteriores.
No caso da sequência de palavras nós queremos esse registro dos acontecimentos do passado, eles são superimportantes para nós.
Vamos tentar de novo agora. Já que nós precisamos associar as palavras de uma frase, vamos predizer toda a sequência de uma vez. A frase aqui é “eu acordo cedo quando chove”. Vamos alimentar toda essa frase para o nosso MLP e ele vai nos dar todas as classes na saída.
E o que isso significa na prática? Significa que se eu tinha um vetor que era do tamanho do meu dicionário para representar uma única palavra, então nessa frase toda eu vou ter cinco vezes o tamanho do dicionário.
Eu vou ter um vetor cinco vezes mais gigante do que um dicionário de palavras, que já é gigante, porque tem todas as palavras do idioma. Mas esse também não é o único problema, nós vamos ver.
E a saída, no caso, estaria associando todas as palavras e possivelmente ela conseguisse acertar a categoria de cada uma das palavras - se você conseguisse treinar isso, que nós vamos ver que é muito difícil.
Aqui nós temos duas limitações muito importantes: a primeira eu nem coloquei aqui, que é a dimensionalidade absurda desse dado, que seria dificílimo de treinar, mas tem problemas piores com essa abordagem.
A entrada e a saída precisam ter tamanho fixo, porque lembrando que com essas redes totalmente conectadas você precisa definir logo de partida quantos neurônios ela tem que ter. Esse número de neurônios precisa saber quantas dimensões tem o seu dado. Lembrando que cada neurônio processa uma dimensão do dado.
Então a entrada e a saída precisam ter tamanho fixo. Problemas do mundo real vão envolver sequências de tamanho variável e esse é um problema muito difícil de otimizar, não só pelo tamanho, mas por uma coisa que não cabe nós explicarmos aqui. É um problema de predição estruturada, onde existe uma alta correlação entre os dados e as saídas.
Se vocês quiserem saber mais, eu vou deixar um “para saber mais” aqui com links que explicam a predição estruturada e o grande problema dessa abordagem.
Vamos para uma terceira tentativa agora de usar o MLP – e essa aqui é promissora. Nós podemos aplicar a rede totalmente conectada em janelas de elementos e prever um elemento de cada vez.
O que isso seria? A frase é: “eu acordo cedo quando chove”. Eu vou processar um conjunto pequeno de palavras. No caso aqui, eu escolhi três palavras, “eu acordo cedo” e eu só vou classificar a palavra do meio.
Então eu quero saber o que significa a palavra “acordo” dentro desse contexto, “eu acordo cedo”. Eu consigo prever que essa palavra é um verbo, porque eu tenho aquele contexto direto ao redor da palavra.
E eu vou fazer isso com várias janelas. Eu tenho a janela “eu acordo cedo” e eu tenho a janela que eu deslizei, “acordo cedo quando”, e eu vou ter a terceira janela, “cedo quando chove”. Daí por diante eu vou prevendo palavra por palavra, mas a entrada é um contexto maior.
Essa abordagem era utilizada até recentemente em um modelo muito bom de linguagem, chamado n-gram - que a letra “n” é do tamanho dessa janela, no caso seria 3 para a nossa janela anterior. O “gram” tem alguma origem que eu esqueci de onde é, que significa “grafia”, “palavra”, essas coisas. N-gram é a sequência contínua de N itens, dado um texto.
Esse tipo de abordagem era utilizado no autocompletar do celular. Antes de se usar modelos recorrentes ou outros modelos que tenham memória, você usava redes neurais tradicionais que processavam só uma janela da sua frase. Você tinha várias possibilidades, dada aquela sequência; são as possibilidades de autocompletar que apareciam no seu celular.
Claro que isso aqui tem muitas limitações, porque as dependências de longo prazo vão ser perdidas, já que eu estou processando só uma janela fixa pequena da minha frase, então essa janela pode não atender bem em todos os casos porque algumas frases exigem um contexto maior.
Por exemplo: tinha o exemplo da Ada Lovelace, que vimos anteriormente, mas eu botei aqui um exemplo de autocompletar que não conseguiria fazer o seu papel se ele fosse baseado em n-gram.
“Ludmila já morou na França. Passou dois anos estudando. Hoje em dia ela fala muito bem o...”. Ele não tem o contexto do início da frase que a Ludmila morou na França, então ela fala muito bem o francês, mas ele não consegue saber se ele pega uma janela de três, quatro ou até cinco palavras. As janelas precisam ser pequenas, senão nós caímos no mesmo problema da dimensionalidade absurda do dado.
Em resumo, as redes feed-forward, que são as redes que não guardam memórias, são as redes que vão do início para o final sem nenhum loop interno e apresentam limitações para lidar com sequências. Em grande parte, essas limitações estão associadas à incapacidade de guardar memória das instâncias anteriores.
Diferentemente das unidades feed-forward, que é essa rede neural da direita da sua imagem, as unidades recorrentes guardam o seu próprio estado e compõem uma memória interna. Além de dar uma saída, ela também devolve a saída com a entrada da próxima etapa.
Se a feed-forward fazia esse processamento de trás para frente e pronto, a rede neural recorrente vai ter uma saída que não só vai servir para você classificar a sua entrada, mas vai servir de entrada para a próxima iteração.
Nós vamos falar dessa questão de iterações na próxima aula.
O curso Redes Neurais Recorrentes: Deep Learning com Pytorch possui 202 minutos de vídeos, em um total de 45 atividades. Gostou? Conheça nossos outros cursos de Machine Learning em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






