Oi, pessoal. Boas-vindas a mais um treinamento da Alura. Meu nome é Rodrigo e eu vou ser seu instrutor nesse curso de Estatística - parte três.
E é parte três, porque a gente vem de dois outros. No primeiro, a gente falou de estatísticas descritivas e coisas mais básicas, para introduzir o assunto.
No segundo, a gente já falou de distribuições de probabilidade, cálculo de probabilidade, estimação, amostragem.
Nesse aqui, a gente vai focar em teste de hipóteses, porque a gente tem bagagem dos cursos anteriores para poder introduzir esse assunto, que é um assunto com um pouco mais de detalhe, sem ficar muito perdido. Legal?
Nesse curso, a gente vai, inicialmente, já realizar um teste de hipóteses, um teste de normalidade, para a gente entender como isso funciona.
Depois, a gente vai com calma, passo a passo, vendo as etapas de um teste, a formulação das hipóteses, a forma de separar as áreas de rejeição e de aceitação das hipóteses do modelo
O cálculo das estatísticas de comparação e todos esses detalhes que envolvem um teste de hipóteses.
A gente vai seguir esse nosso Notebook que está como material de estudo para você, como eu venho deixando nos outros treinamentos.
Ele é um Notebook muito cheio de figuras para facilitar o entendimento, com os textinhos certinhos para a gente entender cada etapa de um teste.
E, quando a gente estiver realizando os testes, a gente vai fazer ele, passo a passo, como se a gente estivesse fazendo ele manualmente, e depois, lógico, de uma forma mais simples usando o ferramental que a linguagem Python oferece para a gente.
Utilizando Scipy, Statsmodel e outras ferramentas. A gente vai falar de testes paramétricos, testes não paramétricos, mais ou menos três testes em cada de grupo destes testes.
E a gente já vai entender exatamente o que significa paramétrico e não paramétrico.
Eu espero que esse treinamento ajude você nos seus estudos, que você consiga entender e fluir bem com ele, e, no próximo vídeo, a gente vai fazer uma visualização dos dados e a configuração do ambiente, e depois vamos para os testes. Até lá.
Pessoal, maravilha. Antes de começar o nosso treinamento, vamos dar uma olhada no ambiente que vamos utilizar para codificar e também nos dados.
Eu vou utilizar, como fiz nos outros cursos, o Colab. Vamos pesquisar no Google "Colaboratory" e a primeira opção, disponível neste link, é que acessaremos.
O objetivo é verificar as versões que eu estou utilizando agora, quando eu estou gravando, para quando você estiver fazendo o curso, no futuro, caso apareça algum problema na execução de algum código, você verifica a versão que você está usando. Se for diferente da minha, pode ser esse problema e você pode voltar uma versão ou duas, sem o menor problema.
No primeiro curso, vídeo de apresentação, eu mostro como fazer essa volta de versão.
Então vou apertar "Esc", porque ele já abriu uma janela. Eu deixei dois arquivos para você fazer download, dois Notebooks. Um é o do nosso curso, que a gente vai executar o curso, e o outro é para a gente verificar as versões.
No Colaboratory, selecionarei "File" no canto esquerdo superior da página. Em seguida, selecionamos "Upload notebook". Na próxima tela, na aba "Upload" direto, vamos apertar o botão "escolher arquivo". Na próxima tela, abriremos o arquivo "Versão_bibliotexas.ipynb". Ele vem configurado de maneira que facilita verificarmos as bibliotecas que estamos utilizando.
Vou rodar clicando em "Shift + Enter". Ele vai rodar de novo, o meu já tinha rodado. Está executando, demora um pouquinho. Ok. Feito!
Estamos usando a versão do Pandas e essas são as bibliotecas que eu vamos utilizar: Pandas 0.24.2; Numpy 1.16.3; Scipy 1.2.1; Statsmodels 0.9.0.
import pandas, numpy, scipy, statsmodels, seaborn, matplotlib
print('Versão do pandas -> %s' % pandas.__version__)
print('Versão do numpy -> %s' % numpy.__version__)
print('Versão do scipy -> %s' % scipy.__version__)
print('Versão do statsmodels -> %s' % statsmodels.__version__)
print('Versão do seaborn -> %s' % seaborn.__version__)
print('Versão do matplotlib -> %s' % matplotlib.__version__)
Temos, mais ao final, algumas bibliotecas de visualização de gráficos, estudaremos uma coisinha ou outra, é pouca coisa. O Seaborn 0.9.0 e o Matplotlib 3.0.3.
Execute e confira qual é a versão que você está usando, e qualquer coisa você volta uma versão.
Eu já deixei aberto o Notebook e nós vamos começar a trabalhar. Ele já está todo organizado e nós vamos começar a discutir sobre teste de hipótese.
Mas a primeira coisa que eu quero mostrar é o dado que a gente vai, vez ou outra, utilizar no nosso treinamento. Tá bom? E depois, no final, tem sempre um Notebook com os exercícios, utilizar esse Dataset para ficar um projeto bem legal.
Abrindo o tópico "Conhecendo os dados" que está no Colab, o Dataset é o mesmo que a gente temos utilizado nos outros cursos. É um Dataset que eu obtive da pesquisa nacional por amostra de homicídios do IBGE, no ano de 2015. Ele tem as seguintes variáveis: renda; idade; altura foi uma variável que eu fiz, eu a elaborei a partir de uma variável aleatória normal para fins didáticos, isto é, para entendermos o funcionamento de algumas coisas.
Temos também "UF", que é unidade da federação; sexo; anos de estudo; e cor, que é a raça. Todas no Dataset estão codificadas, estão em número. Se você quiser transformar na descrição é só executar um procedimento simples.
Observações importantes. É bom fazer isso sempre que a gente estiver trabalhando com Dataset. Eu fiz alguns tratamentos que estão aqui: foram eliminados registro de renda quando eram inválidos ou missing.
Eu só assumi as pessoas de referência do domicílio, ou seja, eu só estou pegando as pessoas de referência, que talvez sejam os chefes do domicílio. Perfeito.
Vamos abrir agora o nosso Dataset. Primeira coisa: importar as bibliotecas que vamos utilizar. Eu vou usar o sistema de ir importando as bibliotecas conforme a gente for precisando. Mas, inicialmente, a gente já vai precisar do Pandas pelo menos.
import pandas as pd
Para economizar, vamos utilizar o Numpy em alguns pontos do nosso treinamento, então eu já vou importar o Numpy também, import numpy as np. Estamos usando esses dois apelidos que são comuns na comunidade: "pd" para Pandas e "np" para Numpy. Ok?
import pandas as pd
import numpy as np
Agora basta apertar "Shift + Enter". Rodou, Ok. Vamos criar um Dataframe com os dados que eu esqueci de mostrar. Abrindo aba lateral do nosso notebook, selecionando Files - nos outros cursos a gente fez isso e o meu já está aberto aqui, por isso que eu esqueci - eu posso acessar Upload. Os dados já estão disponíveis para você fazer download. Seguindo, na próxima tela, selecionaremos o arquivo "dados.csv" e agora poderemos utilizá-lo.
Lembrando também que você precisa estar logado no Colab para poder fazer esse Upload, para poder executar o nosso curso numa boa.
Então, eu estou logado. Ok. Vamos criar uma variável dados e vou chamar o Pandas, pd e a função read.csv(), para ler o arquivo CSV e colocá-lo dentro de um Dataframe, e vou passar aqui dados.csv, que é o arquivo que fizemos o Upload.
dados = pd.read_csv('dados.csv')
Tudo certo. Vamos apertar "Shift + Enter". Rodou. Vamos visualizar os cinco primeiros registro com dados.head() e apertando "Shift + Enter". Está aqui, o Dataset já está carregado com UF, sexo, idade, cor, estudo, renda e altura.
| UF | Sexo | Idade | Cor | Anos de Estudo | Renda | Altura | |
|---|---|---|---|---|---|---|---|
| 0 | 11 | 0 | 23 | 8 | 12 | 800 | 1.603808 |
| 1 | 11 | 1 | 23 | 2 | 12 | 1150 | 1.739790 |
| 2 | 11 | 1 | 35 | 8 | 15 | 880 | 1.760444 |
| 3 | 11 | 0 | 46 | 2 | 6 | 3500 | 1.783154 |
| 4 | 11 | 1 | 47 | 8 | 9 | 150 | 1.1690631 |
Alguns dados estão codificadas em número. Por exemplo, sexo: 0 e 1. A gente só precisa vir aqui em cima e ver o que significa o 0 e 1. Aqui. O 0 é masculino, o 1 feminino. Perfeito?
Então pessoal, esse primeiro vídeo é isso. No próximo a gente já começa colocando a mão na massa de verdade. Vamos fazer um teste de hipóteses de primeira.
Ok? Só para a gente assustar um pouco. Teste de normalidades no próximo vídeo. Até lá.
Vamos começar realmente a trabalhar com testes de hipóteses.
No curso anterior, começamos a mexer com inferência estatística, teremos agora uma continuidade desse assunto.
No curso anterior, nós estudamos estimação, estimação pontual, estimação intervalar. Aprendemos a calcular o intervalo de confiança, tamanho de amostra.
Aprendemos a obter probabilidades de uma distribuição normal, o que era nível de confiança, nível de significância. Todas essas coisas que a gente vem aprendendo lá, vamos aplicar agora dentro de testes de hipóteses.
Compreenderemos a aplicação prática de tudo isso, em conjunto, dentro de teste de hipóteses.
O que é teste de hipóteses? É uma regra de decisão que ajuda a avaliar hipóteses feitas sobre os parâmetros populacionais e aceitá-las ou rejeitá-las como provavelmente verdadeiras ou falsas, tudo isso tendo como base uma amostra.
É o que já começamos a estudar. A partir de uma amostra, temos uma estimativa de um parâmetro da população e desocobre se ele é representativo ou não.
Algo interessante é que podemos testar várias coisas. O primeiro teste com o qual vou dar um susto em vocês, assim como eu prometi no vídeo anterior, é o teste de normalidade.
Antes analisávamos se uma variável é normal ou não verificando se nela aparecia um "sininho", só visualmente.
Mas existe uma forma de fazer isso mais formalmente, um teste mais robusto, que tenha um valor estatístico, diga-se, com tanta probabilidade que você pode aceitar ou rejeitar a hipótese dessa distribuição, se seguiu a normal.
Outro exemplo de porque a gente está usando teste de hipóteses é um bem clássico, da diferença de renda entre sexos, homens ganham mais, mulheres ganham menos. Será que isso realmente é verdade, com base em um dado concreto?
Por exemplo, o nosso Dataset tem essa informação, a gente vai testar isso no nosso treinamento. Outra coisa, por exemplo, também é um fabricante te passar uma informação e você tem que tomar aquilo como verdade. Podemos testar se essa afirmação do fabricante é verdadeira ou não usando o teste de hipóteses.
Vamos começar com o teste de normalidade. Como eu disse, eu vou dar um susto em vocês, alguns conceitos você não vai entender mesmo.
Mas a ideia realmente é essa: entender como faz, aplicar um primeiro teste e nos próximos vídeos, vamos fazer esse passo a passo, e eu vou mostrando para você como calcular essas estatísticas na mão, com o lápis. Ok?
E no final eu ensinarei como você executa um teste, assim como eu vou fazer agora, pegando uma funcionalidade do Scipy, do Statsmodels, do Python, para executar isso rapidamente.
Então, vamos lá. Primeira coisa, no nosso Colab, localizaremos o item "2.1 Teste de normalidade". Neste item, encontraremos "Importando bibliotecas" e, em seguida, um link. Com este link, vou importar o Normaltest. É o mais simples, um teste de normalidade.
Algo que eu quero chamar a atenção é que é sempre bom ler a documentação desses testes que estamos utilizando.
A documentação diz qual é a hipótese nula do teste. A gente já vai entender o que é isso, hipótese nula. O que ele está testando exatamente? Ele vai dizer para você.
No nosso caso, ele está dizendo que a função normaltest testa a hipótese nula, que é o H0, vamos conhecer, de que a amostra é proveniente de uma distribuição normal. Essa é a hipótese nula. É isso que eu tenho que rejeitar ou aceitar de acordo com o que vamos obter de resultado do teste.
Vamos importar.
from scipy.stats import normaltest
O que eu quero fazer aqui, eu vou definir um nível de significância. Eu vou colocar isso dentro de uma variável. A gente já conhece o que é significância, o que é nível de confiança.
O nível de confiança, trocando em miúdos, é a probabilidade de dar certo, do meu estimador estar correto; e o de significância é dele estar errado. Perfeito?
Eu tenho uma célula aqui vazia, depois eu apago. Significância, vou colocar dentro desta variável, eu vou dar 5%, 0,05. É aquela significância padrão, nível de confiança 95%.
significancia = 0.05
Testando a variável renda do nosso Dataset, que a gente abriu no vídeo anterior. Vamos pegar a renda e visualizar primeiro como é que essa renda está se comportando.
Então dados.renda.hist(). O Pandas tem a função que já é herdada do Matplotlib para a gente plotar um histograma.
Eu vou colocar dentro um parâmetro que se chama bins e eu vou falar que é igual a 50. Ele está dizendo que eu quero 50 "barrinhas" no meu histograma. Vai ficar um pouco mais fácil de visualizar.
dados.Renda.hist(bins = 50)
Então está aqui. Visualmente, aquele nosso padrão de visualizar teste e visualizar uma normal, eu esperaria que a normal tivesse uma forma de sino, e eu estou vendo aqui que não tem esse padrão.
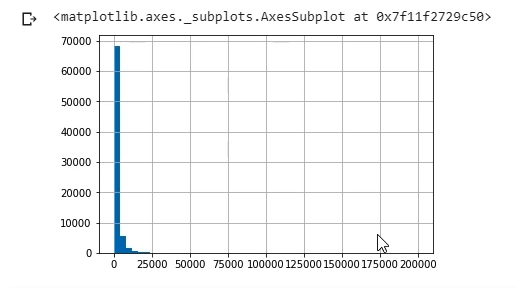
Parece que é uma coisa assim: sobe, desce e vem para o lado direito. É uma coisa meio assimétrica. A gente já viu isso nos outros cursos.
Visualmente, eu consigo perceber que isso não segue uma normal, mas vamos testar isso usando um teste formal, para termos uma estatística e dizer se, realmente, essa variável não segue uma distribuição normal. Com certeza. Sem precisar visualizar.
Vamos começar. Vou fazer direto o teste. É só chamar, normaltest(), que a gente já importou lá em cima, e passar o dado para ele por dados.Renda. Roda isso. Ele já rodou o teste, está aqui.
normaltest(dados.Renda)
NormaltestResult(statistic=152380.75803960307, pvalue=0.0)
O Output desse teste são dois valores: um é o Estatística de teste e o outro é o P valor. Tudo isso a gente vai conhecer ao longo do nosso curso.
Como ele tem dois Outputs, é uma tupla, eu posso passar isso para duas variáveis. Vou chamar de stat_test, vírgula, p_valor. Perfeito. E eu posso printá-los embaixo.
stat_test, p_valor = normaltest(dados.Renda)
print(stat_test)
print(p_valor)
152380.75803960307
0.0
Vamos separá-los, porque eu posso precisar usar isso para alguma outra coisa. Assim conseguimos visualizá-los separadamente.
Aqui em cima eu já deixei uma regrinha de decisão: Rejeitar H0 se o valor de p for maior ou igual a 0,05. Quando eu rejeito o H0 e o que ele é? O H0 é a afirmação de que a amostra é proveniente de uma distribuição normal.
A regra de rejeição é simples: a minha variável de p_valor é menor ou igual a 0,05? O Alfa? Que é o quê? A minha significância, aquela variavel que eu criei mais acima no código.
p_valor <= significância
True
O que ele está dizendo? Que é verdadeira essa afirmação. Então, o que eu faço? Eu rejeito o H0. Que é o quê, novamente? É a hipótese de que a amostra é proveniente de uma distribuição normal.
O que ele está dizendo aqui é que não, não é proveniente de uma distribuição normal, eu rejeito essa hipótese aqui totalmente. Visualmente a gente confirma isso e, agora, com uma estatística mais formal, a gente também confirma isso.
Agora, vamos descobrir uma variável que realmente siga uma distribuição normal e saber o que esse teste mostra para a gente.
A variável "Altura", como eu disse no vídeo anterior e venho falando isso nos outros cursos, fui eu que gerei ela a partir de, justamente, uma distribuição normal, que é uma variável aleatória proveniente de uma normal.
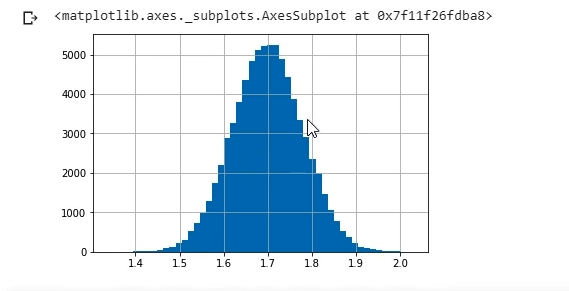
Vamos visualizar de novo, só para termos certeza de tudo que eu estou falando, Altura.hist. E vou colocar o mesmo bins igual a 50 para ficar igualzinho.
dados.Altura.hist(bins = 50)
Olha lá que beleza, o "sininho". Com média de 1,70 m (Um metro e setenta). Eu criei assim mesmo, de propósito.
Aqui, novamente, a regra de rejeição. Vamos copiar esse trecho de código do stat_test, para adiantarmos o nosso trabalho. E já vamos copiar esse p_valor <= significância também.
Nós vamos substituir o p_valor e o stats aqui. A única coisa que eu tenho que fazer é mudar de Renda para Altura e rodar o teste.
stat_test, p_valor = normaltest(dados.Altura)
print(stat_test)
print(p_valor)
0.19973093957002253
0.9049591541967501
É possível notar os números da estatística no trecho acima. Depois a gente vai entender o que é estatística. Não estamos usando, mas vamos precisar dela para tirar algumas decisões. E o nosso P valor, que é o principal. Todo teste que você vai rodar, vai plotar o P valor para você, não se preocupe.
E a regra de decisão é sempre essa. Já é um valor alto, quase 1. Vou rodar a minha regra de decisão, que eu criei aqui.
p_valor <= significancia
False
E o que ele está dizendo? Falso. Eu rejeito H0 se valor de P for menor ou igual 0,5. O que ele está falando é que não, que é falso.
O que eu faço? Não posso rejeitar. Eu não posso rejeitar a hipótese nula, H0, de que a amostra é proveniente de uma distribuição normal. E realmente é, fui eu que criei.
E está aqui. Visualmente, realmente parece uma normal. Bonitinho o sino.
Pessoal, é isso que eu queria mostrar nesse vídeo, esse susto inicial. Não se preocupem, a gente vai ver o que é P valor, a gente vai aprender a calcular um P valor manualmente e também H0, hipótese nula, rejeição, aceitar hipótese alternativa. Os níveis de significância a gente já conhece. Mas todas essas coisinhas que eu fui falando aqui, a gente vai ver passo a passo.
No próximo vídeo, já vamos entender os passos. E no outro a gente vai começar a colocar a mão na massa. Vamos fazer testes, passo a passo, e, no final, eu mostro como fazer isso, de uma forma bem simples e prática, utilizando funcionalidades do Python.
No próximo vídeo a gente vê as etapas básicas de um teste. Até lá.
O curso Estatística com Python: testes de hipóteses possui 179 minutos de vídeos, em um total de 66 atividades. Gostou? Conheça nossos outros cursos de Estatística em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






