Bem-vindo ao nosso curso de data Science com saúde. Vamos falar aqui sobre como utilizar diversos dados de diversas fontes, processar esses dados e extrair informações, passar mensagens através dessas informações que encontramos nos dados.
Para este curso específico vamos usar uma fonte de dados. Escolhemos trabalhar os dados do coronavírus de 2019. Esses dados estão na internet em diversos sites, oficiais, não oficiais, de diversos formatos, diversas formas. Vamos encontrar fontes, discutir como encontrar essas fontes, que tipo de fonte é mais fácil de trabalhar, é mais confiável, e assim por diante.
Vamos discutir e implementar esse código utilizando linguagem Python e o Google Jupyter Notebook, no Google Colab. São ferramentas gratuitas que só precisam de uma conexão com a internet. Vamos trabalhar bastante com Python e com lógica de programação. O pré-requisito é conhecer lógica de programação. Se você ainda não conhece você pode fazer o curso de lógica de programação. Também se quiser assiste o começo do curso e vê se está acompanhando ou se prefere fazer o curso de lógica de programação primeiro.
Consigo então estudar os dados, limpar os dados, entender por que eles estão "sujos", o que seria limpar, o que posso fazer, quais as restrições. Quando faço a análise de repente encontro resultados que não fazem sentido, porque está errado mesmo. Isso acontece na vida real e vamos ver acontecendo. Vamos gerar gráficos horríveis que contam verdades ou mentiras, ou o que gostaríamos que fosse verdade. Teremos gráficos estranhos que mostram crescimentos absurdos, e gráficos em relação aos mesmos dados que são expressos em outras representações visuais. Mensagens diferentes passadas baseadas no mesmo dado.
Vamos discutir por que isso é ruim, como melhorar, a parte de data visualization, engenharia de dados, carregar os dados, variações de gráficos, por que não vamos usar gráfico de torta no dia a dia. Depois calcular certas taxas, carregas mais fontes de dados, calcular taxas, como a taxa de letalidade de uma doença. Quando eu peço uma medida de resumo, surgem certos problemas e existem várias formas de calcular uma média, como a própria taxa de letalidade, e veremos as vantagens dessas diferentes formas - seja uma taxa mais "crua" ou uma mais "inteligente", que usa outras variáveis.
Vamos calcular tudo isso, plotar, tirar novas informações, como casos novos. Tudo isso neste curso. E principalmente vamos discutir. Não só aprender a usar a ferramenta, o Python, o Jupyter Notebook e carregar dados da John Hopkins, mas também a discutir. Onde encontrar fontes de dados confiáveis, como decidir se a fonte é confiável, como carregar, como trabalhar os dados, como passar uma mensagem, como deixo claro que o meu processo tem buracos que eu não consigo tampar? Como passar uma mensagem justa e honesta para quem está recebendo meu relatório ou gráfico?
Tudo isso a gente vai discutir aqui. Vamos lá?
Vamos então começar nosso curso? A primeira coisa é acessar os dados para poder fazer uma análise. Preciso deles. Como vamos acessar os dados do coronavírus, eu quero de alguma maneira ter acesso ao número de casos confirmados, mortes, recuperações, de vários países.
Tem muitos lugares onde podemos procurar isso. Existe uma fonte que vou utilizar chamada CSSEGISandData para esse vírus especifico, o COVID-19. O site é o GitHub. Nele, existem diversas bases de dados, entre várias outras coisas de programação. E tenho os dados da COVID-19.
Na página encontramos que esses dados vieram de diversos lugares. Dados providos basicamente da ohns Hopkins University, Organização Mundial da Saúde, informações de pneumonia, informações do China CDC (controle de doenças), entre várias outras informações que estão sendo agrupadas e colocadas aqui para nós. O autor desse repositório está agrupando as informações. Já deve ter mais de uma pessoa trabalhando para fazer esse agrupamento de várias fontes.
É claro que essas pessoas podem estar errando algo na hora de agrupar e esse erro vai aparecer nas nossas análises. Senão teríamos que ir em todas as fontes, entender elas. Como é nosso primeiro curso, vamos com uma só. Daqui a pouco vai ter uma aula onde vou focar em como buscar as fontes. Como eu, Guilherme, caí nessa fonte. Mas primeiro eu quero trazer algum resultado, olhar alguma coisa funcionando.
Sabemos que existem os dados, analisamos eles, vamos discutir melhor como chegar nesses dados. Na página do CSSEGISandData, vemos que existem dois tipos de dados que ele está pegando: o CSSE COVID e o WHO, que é a Organização Mundial da Saúde. Ele descreve tudo bonitinho. O CSSE são dados informados pela Johns Hopkins, tanto universidade quanto hospitais e institutos de pesquisa. Vamos usar ele, que na data da gravação do curso havia sido atualizado 13 horas antes. O da Organização Mundial da Saúde foi 7 dias antes, então o outro é mais recente. Tem relatórios diários, mas quero um mais resumido.
Vou olhar a tabela de casos confirmados, em que tenho uma província, o país, latitude, longitude e quantos casos confirmados em cada dia. Lembrando que se eu confirmei hoje no laboratório que tenho um vírus, não quer dizer que hoje peguei esse vírus. Posso ter pego alguns dias atrás. Não quer dizer que meus sintomas começaram hoje. Talvez tenham começado um tempo atrás. É a data de confirmação de que a pessoa tem essa doença. É essa data que vamos usar. Lembrando que cada país, ou mesmo regiões dentro de um país, pode usar um critério diferente para definir o que é confirmado. Na maior parte dos casos, confirmado é depois de uma análise no laboratório que confirmou que o vírus estava presente, porque encontrou anticorpos ou algo assim.
Em situações de epidemia, uma coisa mais grave, um país pode definir como caso confirmado mesmo um diagnóstico clínico baseado em sintomas, como tosse ou febre alta. Poderia ser outro tipo de vírus, como Influenza, mas iremos apostar no coronavírus dado que ele está tendo alta circulação na região do país. Então, países diferentes podem usar critérios diferentes de confirmação. Repare como é difícil de analisar. Tudo isso temos que levar em consideração e ficar atentos, porque vai refletir em taxas de pessoas confirmadas maior ou menor.
Então, temos esses dados para nós, numa tabela bonitinha, mas se vamos programar algo, não dá para ler uma tabela bonitinha. Precisamos de uma tabela padronizada, formatada. Aqui no Github, clicando em "Raw", nós temos os dados crus. Esse arquivo tem a extensão csv, ou "Comma Separated Values", um arquivo em que os valores estão separados por vírgula. É um padrão super utilizado para trocar dados de um lado para o outro, muito comum, e mesmo o Excel tem essa opção como exportação. Fazemos isso direto. As ferramentas que iremos utilizar também leem Excel ou formatos equivalentes.
No meu caso, é esse arquivo cru que eu quero ler. Quero ler em algum lugar. Tenho que programar. Se eu quero programar em Python, tenho que instalar Python, e se quero programar como se fosse um notebook, um caderno onde faço as anotações, preciso instalar algum caderno de anotações de Python, que é o Jupyter Notebook.
O Júpiter Notebook tem variações. JupyterLab, Jupyterlab online, com diversos nomes. O próprio Kaggle, onde podemos colocar notebooks em que a gente escreve programação Python. Mas eu vou usar o Google Colab.
Aqui dentro você pode se logar na sua conta do Google e criar um novo notebook. Fazendo isso você pode começar a escrever nele. Vou dar um nome, "Curso Data Science e Saúde", e digitar como um notebook qualquer, programando como uma linguagem de programação qualquer. Numa linguagem de programação é comum fazer várias coisas. Por exemplo, vou declarar uma variável com meu nome fazendo nome = "Guilherme".
nome = "Guilherme" Toda vez que você abrir o notebook e rodar, ele vai rodar lá no Cloud (a nuvem) do Google. Então a primeira vez que você aperta play demora um pouco, porque ele está inicializando a máquina para poder rodar o comando. Ele vai inicializar, rodar, e maravilha, não aconteceu mais nada, porque eu só atribuí o valor Guilherme à variável nome, como em qualquer linguagem de programação.
Se eu quiser imprimir a variável nome, uso print() e o nome entre parênteses. Estou usando o Python, que é essa linguagem de programação, e o Jupyter Notebook para executar.
print(nome)Guilherme
Além do botão de "play", também posso usar o "Shift + Enter" para rodar uma célula. Uma sacada legal é que se eu digitar só o nome da variável (nome), ele já me dá uma dica de autocompletar, e se eu apertar "Shift + Enter" ele vai fazer o print() para mim. Ele coloca entre aspas para dizer que é uma string, mas isso é o básico que vamos usar.
nome'Guilherme'
Agora quero utilizar coisas para valer com foco na nossa análise. Se você quiser aprender mais sobre linguagem Python temos os cursos aqui na Alura. Como temos aqui que é importante já termos uma noção de lógica de programação, vou usar esse notebook para criar coisas para os nossos dados.
Clico no ícone de lixeira à esquerda para apagar as células que criamos agora, e tenho uma nova célula aqui. Primeiro, quero ler o arquivo CSV que pegamos no Github. Posso dar um "Ctrl + C" para copiar a URL do arquivo, e toda vez que ele for atualizado vou tê-lo na versão mais recente.
Quero ler esse arquivo da internet. Para ler um arquivo da internet, que vai ser baixado, lido, processado, preciso de algumas ferramentas. Em Python, existe uma ferramenta para análise de dados, que é o Pandas, que iremos importar, e é comum usar o apelido pd para ele.
import pandas as pd O Pandas tem uma função que lê um arquivo CSV, read_csv(). Ela devolve para nós uma tabela de casos confirmados, que chamaremos de confirmed. Vou imprimir esses dados passando somente a variável confirmed. Com "Shift + Enter", ele vai carregar da internet, trazer os dados e imprimir para mim cada linha.
import pandas as pd
confirmed = pd.read_csv("https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv")
confirmed Só que não quero imprimir todas as linhas, só as cinco primeiras. Só a "cabeça" do meu conjunto de dados, ou seja, o head().
import pandas as pd
confirmed = pd.read_csv("https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv")
confirmed.head() Agora, posso querer saber o formato dessa tabela, o shape. São 142 linhas e 45 colunas.
confirmed.shape(141, 45)
E se eu quero agora só a coluna "Country/Region"? Vou usar a variável confirmed e entre colchetes o Country/Region. Isso seleciona só uma coluna.
confirmed["Country/Region"] Repare que como é só uma coluna, a gente não chama mais de quadro de dados, um dataframe. A gente chama de uma série de valores. Isso me trouxe vários países. Eu poderia pegar da última data, que aqui era "03/02/20", e criar uma variável last_date, mantendo o padrão em inglês. Eu poderia renomear tudo para português, mas nesse caso específico vamos manter os dados originais como estão, para não dar confusão.
Quero imprimir agora a coluna referente a esta última data, que conseguirei com confirmed[last_date]. Ele vai mostrar para mim só essa coluna, primeiro "990" casos, depois "414" e assim por diante.
last_date = "3/2/20"
confirmed[last_date] Extraímos essa coluna. O que mais posso fazer? Agora, quantas províncias ou cidades da China estão infectadas? Uso confirmed["Country/Region"]. Repare que não quero ler todos os dados dez vezesm, eu quero valores únicos, ou seja, que "Mainland China" e "US", por exemplo, apareçam uma única vez. Para isso usarei o unique().
confirmed["Country/Region"].unique() Se procurarmos por valores únicos na documentação do Pandas você vai ver que temos uma função unique() que podemos invocar. É ela que vou chamar. Ela me devolve os países afetados até esta data. Posso também filtrar a coluna "Province/State", é a mesma coisa. Ele vai mostrar províncias e Estados afetados que temos informações.
confirmed["Province/State"].unique() Mas calma, cuidado. Repare que nem todos estão preenchidos. Quando abrimos todos os valores, vimos que existem alguns casos no confirmed que não estão preenchidos. Vou pegar uma amostra aleatória, um sample(), de 20 elementos para ver isso. Os não preenchidos aparecem como "NaN", "not a number". Esses dados estão sujos, no sentido de que não estão limpos, no sentido de que tem valores que não estão preenchidos, em branco.
confirmed.sample(20) O que eu faço quando não sei o que um valor está preenchido? Temos que tomar algumas decisões. Queria pegar agora uma linha específica. Vamos pegar, por exemplo, a linha 0, a linha em que o índice é 0. Para isso, vou nos confirmados (confirmed) pegar a localização baseada no número da linha, que conseguiremos com iloc. Como retorno teremos uma província da China.
confirmed.iloc[1]Province/State Anhui Country/Region Mainland China Lat 31.8257 Long 117.226 1/22/20 1 (...)
Eu poderia pegar a linha seguinte, que é a segunda linha, a linha 1, que retornará as informações de Beijing. Agora, se eu quiser procurar pelo nome de uma cidade, como Beijing. Repare que o índice é um número. Vou trocar o índice para a província e Estado, e farei isso com confirmed.set_index("Province/State"). Agora o índice é outro e posso fazer .loc passando a cidade que eu quero. O loc localiza pelo índice, enquanto o iloc pela linha, que continua atendendo por números. Vamos usar os dois dependendo do que precisarmos.
Ainda só fiz seleções de colunas e linhas. Nós sabemos os países, que vimos no conjunto de casos confirmados. Consigo até ver de forma única. Mas não é isso que eu quero. Quero contar quantas vezes aparece "Mainland China", quantas vezes aparece "US". Quero contar os valores, e farei isso com value_counts(). Sinta-se à vontade de procurar na documentação do Pandas as funções que precisar.
confirmed["Country/Region"].value_counts() O value_counts verifica em quantas está escrito a palavra que quero procurar. Ele conta em quantas linhas cada ocorrência aparece, mas tenho que tomar cuidado. Alguns países não estão nesse relatório separado por cidades, então vai aparecer um número menor, podendo ter um número muito maior de casos. A Coreia, por exemplo, na data da gravação deste curso, tem mais casos que os Estados Unidos, mas os Estados Unidos reportou nesse relatório um número maior de regiões.
Então esse é um valor falso, porque o erro é muito grande. Como o erro é grande, vamos descartar essa análise. Tem muita disparidade no padrão, então a gente desconsidera.
Eu quero o número de pessoas confirmadas. Vamos pegar o confirmed e, ao invés de contar os valores, agrupá-los com o groupby(). Ao escrevermos a função, o Google Colab já vai dando dicas de como funciona o groupby() com um pop up. Vou agrupar pelo país, "Country/Region".
confirmed.groupby("Country/Region") Ele me devolve um agrupador. Agora eu quero pegar cada uma dessas colunas e somar com a função sum().
confirmed.groupby("Country/Region").sum() Agora tenho aqui todos os valores de países/regiões agrupados, que chamarei de confirmed_by_country ("confirmados por país"). Para analisarmos os dados, ao invés de mostrar todos, vou mostrar só os primeiros com head(){. Também podemos usar o sample() para ver, por exemplo, 10 valores aleatórios.
confirmed_by_country = confirmed.groupby("Country/Region").sum()
confirmed_by_country.head()confirmed_by_country.sample(10) Note que cada vez que executarmos o sample(10), novos valores aleatórios serão exibidos. Queria uma última coisa antes de parar essa aula. Repare que temos os confirmados por país e já sabemos buscar pelo índice. Repare que ele já criou um índice por país. Vamos dar uma olhada na China localizando-a pelo índice. Tenho toda essa linha, só que equivalente à China. Nos dois primeiros valores temos latitude e longitude. Se eu quiser o primeiro valor, é o valor 0 (confirmed_by_country.loc["Mainland China"][0]), latitude, não vou usar. O valor 1 é longitude, não vou usar. Eu estou interessado no valor 2 em diante, que conseguiremos com [2:]. Com isso teremos casos confirmados na China por dia.
confirmed_by_country.loc["Mainland China"][2:] Quero plotar esse valor, desenhar, usando a função plot(). O que a gente tem? Os casos confirmados na China, começando bem baixinho, aumentando, crescendo, um crescimento parecido com o exponencial (com um pouco de extrapolação), e aí depois ele meio que estabiliza, dá para aproximar de outras maneiras visualmente. O número de casos novos começa a diminuir bastante, de acordo com esses relatórios que a gente tem acesso.
confirmed_by_country.loc["Mainland China"][2:].plot()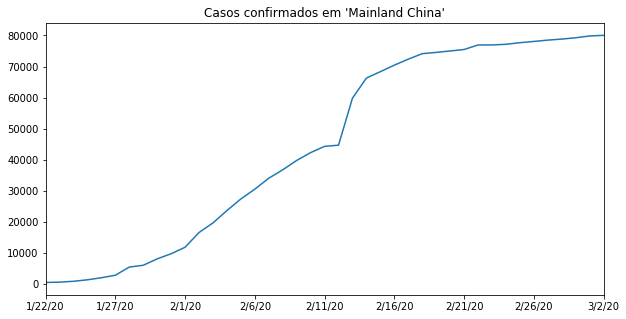
Vamos fazer muito mais, mas já deu para ter uma boa ideia de onde podemos chegar.
Vimos como montar um gráfico simples, em que temos uma série temporal, que é o tempo e uma série de dados em função desse tempo. Ficou meio feio por diversos motivos. Primeiro, não tem título. Para colocar um, acessarei uma biblioteca usada pelo pandas para plotar, a Matplotlib, com import matplotlib. Ela é comumente importada com o apelido plt. Eu não preciso instalar essas bibliotecas porque estou rodando os códigos na nuvem do Google. Se você quiser, você pode instalar o Python na sua máquina e rodar, mas eu recomendo começar no Google Colab para entender como as coisas funcionam sem precisar instalar nada, e ainda mantendo um backup na conta do Google.
O título desse gráfico vai ser "Casos confirmados em ‘Mainland China’". As aspas simples são porque "Mainland China" tem diversas definições e eu não quero entrar nesse escopo político, algo que não faz sentido analisarmos. Vou importar da maneira como os dados são trazidos para nós, considerando que quem fez a classificação como "Mainland China" foram as fontes dos nossos dados.
import matplotlib.pyplot as plt
confirmed_by_country.loc["Mainland China"][2:].plot()
plt.title("Casos confirmados em 'Mainland China'")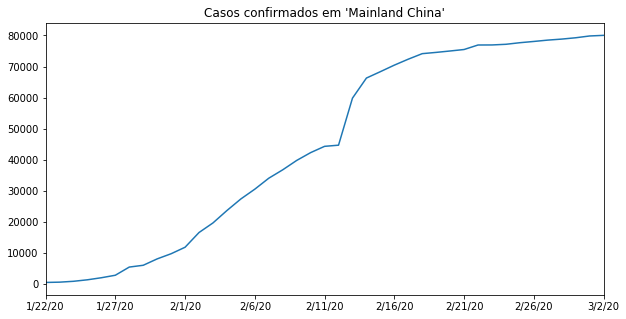
Repare que toda vez que executamos o código, ele imprime um resultado. Esse é o resultado da última operação que fizemos. Para evitarmos isso, é comum usarmos um plt.show() para mostrar somente o gráfico.
Eu também queria aumentar um pouco esse gráfico. Antes de desenhá-lo, vou chamar a função plt.figure() passando um atributo figsize com dois parâmetros, (12, 7). Considerando que ficou muito grande, substituiremos por (10, 5). Agora, tem um detalhe. Repare que quando estamos falando de visualizar os dados, tiro informações dos dados crus. Nesse caso, através de uma visualização, ou seja, data visualization, uma área super importante do data Science. Vai muito além do que estamos vendo só nesse gráfico. Iremos discutir um pouco neste curso e temos vários outros na Alura sobre o assunto.
Vou mudar um pouco esse gráfico colocando o figsize como 20, 5. Com a imagem mais larga, o crescimento parece mais leve, uma linha diagonal. Se eu mudo para 5, 5, parece um crescimento absurdo. Com 2, 5, mais ainda. Visualizar os dados pode ser feito de diversas maneiras, através de palavras, números, gráficos. São maneiras de visualizar dados, e aí tentamos tirar informações. Quando fazemos isso, estamos interpretando aquilo que está sendo fornecido. Quando passa pela interpretação, temos todas as questões sensoriais de como interpretamos.
Quando você olha um gráfico, você olha a inclinação, é isso que chama a atenção. Não olho o eixo. Sem querer, a informação é a mesma, já que os dados são os mesmos, mas a mensagem muda de acordo com as visualizações que são geradas. Não sei qual é mais condizente com a realidade, não existe uma regra perfeita, mas com certeza se eu colocar um gráfico extremamente pequeno estaremos sendo inadequados ao passar uma mensagem errada. Longe do adequado. Essa com certeza não é a mensagem que está naqueles dados. Mas claro, tudo depende da mensagem. Nesse caso, a opção 10, 5 parece ser a mais razoável.
É por isso que em Data Visualization é fundamental estarmos atentos aos dois eixos. Para analisarmos isso melhor,vou fazer uma pequena variação. Ao invés de imprimir tudo a partir do dia 1°, vamos a partir do dia 15 de fevereiro, que é a linha 25.
plt.figure(figsize=(10,5))
confirmed_by_country.loc["Mainland China"][25:].plot()
plt.title("Casos confirmados em 'Mainland China'")
plt.show()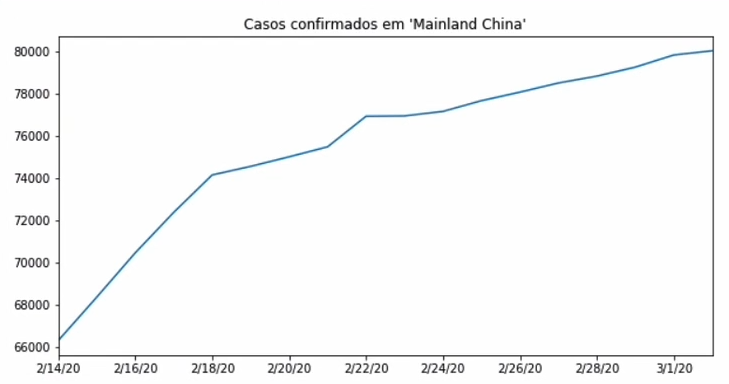
Olha esse gráfico. Agora vou limitar das linhas 25 a 33.
plt.figure(figsize=(10,5))
confirmed_by_country.loc["Mainland China"][25:33].plot()
plt.title("Casos confirmados em 'Mainland China'")
plt.show()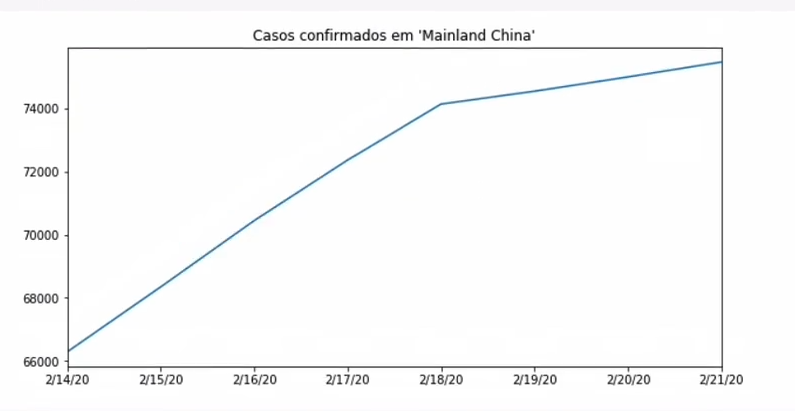
É absurda a diferença entre os gráficos, não é? Mas os dados representam sempre a mesma coisa, mas temos um problema com o eixo, que vai de 0 a 80000 em alguns casos, e de 66000 a 74000 em outros. Vou limitar o eixo y de 40 mil até 80 mil. Com isso, teremos o mesmo gráfico que geramos anteriormente, mas com outro eixo. Parece absurdo esse crescimento. Ainda que exista um crescimento forte, nesse gráfico passamos uma mensagem muito mais grave. Tanto no eixo x quanto y, se mudarmos as dinâmicas, as janelas, ampliamos a imagem, alteramos a mensagem final, alteramos a mensagem passada ao usuário. Esse é um exemplo ruim de como manusear os eixos.
plt.figure(figsize=(10,5))
confirmed_by_country.loc["Mainland China"][2:].plot()
plt.title("Casos confirmados em 'Mainland China'")
plt.ylim(40000, 80000)
plt.show()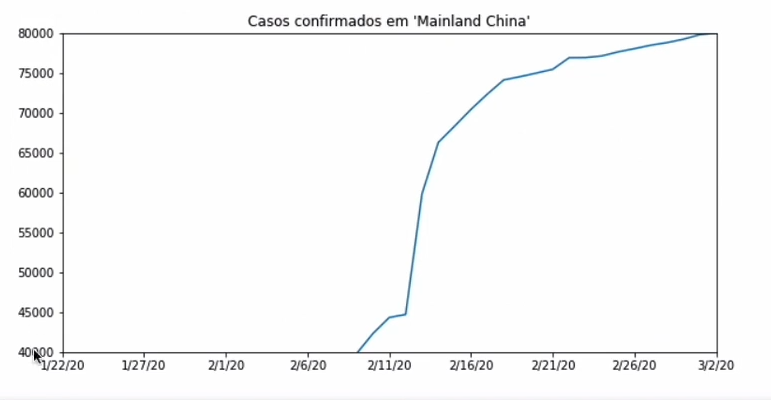
Se eu fizer um gráfico com limites de zero a trezentos mil, terei uma mensagem bem diferente em relação ao crescimento no número de casos. Aqui estou comparando o crescimento real com esse número, trezentos mil. no gráfico original, estávamos comparando o início da epidemia local com a situação atual no momento da coleta dos dados. Cada gráfico passa uma mensagem diferente. É isso que passamos de informação. Faz sentido? Poderíamos usar como limite no eixo Y a população da China que pegamos no Google, que é 1,3 bilhões. Fazendo isso, o gráfico some. Em comparação com a população inteira, não aconteceu nada.
Reparou como é perigoso? Poderia ser uma doença que mata 100% em dois dias. Se eu passo esse gráfico, que história estou passando? Que a doença não é grave. Mas para cada pessoa contaminada ou que morreu, é sim uma doença grave.
Nesse último gráfico a mensagem é completamente diferente, ruim e até mesmo errado. Ao usarmos a população do país como eixo Y, "fingimos" que a doença não é grave. Sendo que na realidade esse gráfico não possui informação nenhuma sobre a gravidade da doença, porque só tem casos confirmados, não fala letalidade, não fala incidência, nada disso. Sem contar que quais são as províncias infectadas? Toda a China? Eu estou comparando com a população de toda a China. É errado. Passa uma mensagem errada com comparações injustas. Podemos sem querer fazer esse tipo de gráfico, e tem gente que faz por querer, o que seria muito pior.
Repare a importância do data visualization no dia a dia. Daqui a pouco veremos mais.
O curso Data Science: análises para saúde e medicina possui 152 minutos de vídeos, em um total de 22 atividades. Gostou? Conheça nossos outros cursos de Data Science em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






