Boas vindas ao nosso curso de Introdução à Data Science com Python.
Aqui, carregaremos um conjunto de dados do mundo real, oriundo do MovieLens, que trabalha com filmes e notas.
Exploraremos estas informações via Exploratory Data Analysis (que em tradução livre seria algo como "análise de dados de maneira exploratória"), utilizando diversas bibliotecas do Python.
Estas ferramentas poderiam ser de outras linguagens sem nenhum problema. Optamos pelo Python que, atualmente, está sendo muito bem utilizado no mercado para este tipo de trabalho.
Usaremos ferramentas como NumPy, Pandas, Seaborn para visualização, Matplotlib, ou o próprio Pandas com funções de plotagem próprias, para explorar os dados sobre os quais faremos queries, pesquisas de informações sobre tendências de tais dados, como a Tendência Central, a média ou mediana.
Entenderemos a distribuição das notas dadas aos filmes por meio de histogramas ou boxplots, com os quais faremos comparações. Assim, conseguiremos resumir informações de diversos filmes, como as línguas mais populares contidas no conjunto de dados coletados, por meio de visualizações de gráficos mais interessantes e difíceis de serem compreendidos de início.
Aqui, teremos uma introdução ao assunto, à medida em que exploramos três arquivos de dados diferentes — dois do GroupLens (MovieLens) e um do TMDb (The Movie Database), que contém informações de diversos filmes.
Falaremos sobre a parte de visualização de dados, lidaremos com boas e más práticas, e com questões que poderão ser aprofundadas ou complementadas em outros cursos, de acordo com o seu interesse pessoal.
Talvez você queira seguir estudando Estatística, por exemplo, para fazer testes estatísticos, ou para Data Visualization, para criar dashboards e apresentações gráficas, exibindo visualizações que fazem sentido e contam uma história. Ou então aprofundar mais no Pandas, e em como trabalhar com os seus dados.
Além de modelagens, regressões, entre outros temas, há diversas áreas que podem ser continuações deste curso. Vamos começar?
Nosso primeiro passo consiste em decidirmos que ferramenta usar para escrevermos o código que analisará nossos dados. Existem diversas ferramentas e formas de trabalharmos, e optaremos por uma bastante conhecida quando se usa Python, o Jupyter.
Este projeto permite a criação de um caderno, em que fazemos anotações à medida em que exploramos os dados. Não existe uma maneira única de se trabalhar com ele, e podemos baixá-lo em nossa máquina. Além disso, é possível utilizar equivalentes do Jupyter, ou até mesmo o próprio Jupyter na web, na nuvem.
O site do Kaggle, por exemplo, permite a criação dos notebooks e contém vários dados a serem analisados, os chamados datasets. No nosso caso, usaremos o Colaboratory, do Google. Trata-se de uma versão dos notebooks no cloud, sem a necessidade de baixar ou instalar algo localmente.
O único requisito para usarmos o Google Colab é uma conta do Gmail. Feito o login, clicaremos em "New Python 3 Notebook" na parte inferior da caixa de diálogo. O novo notebook será criado, e o renomearemos de "Introdução à Data Science". Se clicarmos em "File", existem as opções de salvarmos uma cópia no Drive, no GitHub, ou na nuvem.
A célula que é exibida na tela é onde digitamos o código Python, como um simples nome = "Guilherme". Ao clicarmos no botão de play, um círculo escuro com um triângulo logo à esquerda da célula, o código será rodado. A primeira vez costuma demorar um pouco mais, pois é preciso acessar o cloud e uma máquina especial (virtual, ou um contêiner), para que possamos rodar nosso código Python.
Feita a conexão, o código é rodado, mas já que uma expressão como esta não devolve nada, nada é impresso na tela. Criaremos uma célula clicando em "Code" com um quadrado e um símbolo de +, na parte superior e logo abaixo do menu de ferramentas principal. A primeira célula, então, já foi rodada, e nesta escreveremos print(nome) e pressionaremos o play. Teremos o retorno Guilherme, como esperado.
As variáveis ficam em memória à medida em que executamos os códigos, e uma célula pode ter várias linhas de código.
Criaremos mais uma linha de código devolvendo o resultado da linha digitada anteriormente:
idade = 30
idadePor fim, poderemos substituir variáveis:
idade = 38A qualquer instante, é possível clicar em "Runtime" e reiniciar tudo que está sendo executado com "Restart runtime...". Quando clicarmos em "Yes", perderemos todas as variáveis em memória, isto é, tudo o que foi executado anteriormente. As saídas anteriores são mantidas na tela para o caso de querermos consultá-las, mesmo que não existam mais.
Com o atalho "Shift + Enter" conseguimos rodar as células, no entanto, se o fizermos após a reinicialização, obteremos um erro indicando que a variável nome não foi definida. Porém, se usarmos o mesmo atalho em cada uma das células anteriores e executarmos o código, deixaremos de ter esse erro.
No caso, removeremos todas as células clicando nos três pontos localizados do lado direito de cada uma delas, e em "Delete cell". Com isso, estamos prontos para começar a analisar os nossos dados!
Trabalharemos com um conjunto de dados real, a avaliação de diversos filmes por usuários da internet, do MovieLens. O site abriga variações destes dados, que podem ser baixados sob licença de uso. Existem versões de 20 milhões, 100 mil, 27 milhões de notas (ratings) para filmes, e por aí vai.
Neste curso optaremos pelo arquivo contendo 100 mil. Cada versão disponibilizada pelo site é atualizada periodicamente, então, se baixarmos uma delas hoje, provavelmente dali um tempo o mesmo arquivo terá notas e filmes diferentes. Isso porque trata-se de uma amostra aleatória para análise.
A exata versão que usaremos neste curso pode ser baixada neste link.
Após o download e descompactação, usaremos inicialmente o arquivo ratings.csv, com as avaliações organizadas em uma tabela cujos cabeçalhos são: "userId", "movieId", "rating" e "timestamp", ou seja, usuário, filme avaliado, nota e o momento em que ela foi atribuída no site, respectivamente. Na nossa análise apenas as três primeiras colunas nos interessam.
Ao abrirmos o arquivo, notaremos que os números são separados por vírgulas, pois CSV remete a comma-separated values. E é este o arquivo que queremos ler para analisar os dados.
No Python, existe uma biblioteca com um módulo feito para a leitura de arquivos neste formato, o Pandas. Solicitaremos sua importação, e então a leitura do arquivo CSV:
import pandas as pd
pd.read_csv("ratings.csv")Rodaremos o código com "Shift + Enter", mas nos depararemos com uma mensagem informando que o arquivo .csv não foi encontrado. Claro, pois ele se encontra na nossa máquina local, enquanto o código está sendo rodado no cloud. Caso você rode o código no Jupyter da sua máquina, basta que ele esteja no mesmo diretório, com o path adequado. Caso o arquivo esteja na nuvem do Google, como o subiremos?
Clicaremos na aba escura com um >, localizada na extrema esquerda da tela, em "Files" e "Upload". Será exibida uma mensagem indicando que os arquivos são deletados toda vez que zeramos a nossa runtime, após o qual o nosso arquivo é listado. Rodaremos tudo mais uma vez e, agora sim, o arquivo é lido e trazido com sucesso.
São muitas informações, portanto atribuiremos tudo isso a notas e, em vez de todas, pediremos para que apenas as cinco primeiras avaliações sejam exibidas, isto é, a "cabeça" (head) da lista de elementos:
import pandas as pd
notas = pd.read_csv("ratings.csv")
notas.head()Há diversas maneiras de saber quantas avaliações existem, e uma delas é pedir o formato da tabela, com notas.shape. Isto nos retornará a informação de que há 100836 avaliações e 4 colunas. O contador à esquerda, na tabela, será denominado índice, que não consideramos como sendo uma coluna.
Continuando, caso queiramos trabalhar com o português, e não inglês, alteraremos os nomes das nossas colunas com o atributo columns:
notas.columns = ["usuarioId", "filmeId", "nota", "momento"]Feita esta redefinição, solicitaremos a impressão dos dados com notas.head(), na mesma célula. Assim sendo, notas é um objeto do Pandas com várias colunas e 0 ou várias linhas, um tipo conhecido como Pandas DataFrame, cuja documentação corrente (versão 0.24.1) indica suas inúmeras possibilidades.
De maneira rápida, o que conseguimos analisar com o que temos até aqui?
A coluna "nota" contém os valores 4.0 e 5.0, mas será que eles são únicos? Para consultarmos todos os valores desta coluna, digitaremos e rodaremos o seguinte código:
notas['nota']Já entendemos que são 100836 valores, e anteriormente os dados eram impressos de forma visualmente agradável, em uma tabela, por ser um dataframe. Agora que solicitamos uma única coluna, por padrão, ela será uma série de números, que chamamos de Pandas Series. Trata-se de uma série de dados, e de acordo com sua documentação, ela também fornece uma grande quantidade de possibilidades.
Por exemplo, para sabermos quais são os valores colocados nesta coluna de maneira única, utilizamos unique(). Ao usarmos o código notas['nota'].unique(), e o rodarmos com "Shift + Enter", o retorno será:
array([4., 5., 3., 2., 1., 4.5, 3.5, 2.5, 0.5, 1.5])
As notas, portanto, variam de 0.5 a 5, e a nota 0 não foi dada em nenhum momento. O Pandas serve para a leitura e escrita de um conjunto de dados de diversas maneiras, e também para extrair informações a partir destes dados.
Se quisermos saber quantas vezes uma nota específica aparece nesta coluna, poderemos usar:
notas['nota'].value_counts()Isso imprimirá duas colunas de valores, sendo a primeira com as notas e a segunda a quantidade de vezes que ela foi dada, ordenadas de forma decrescente (do maior para o menor). Para encontrarmos a média destas notas, utilizaremos:
notas['nota'].mean()O que trará o valor 3.501556983616962. Existem outras medidas que serão vistas neste curso, mais ou menos relevantes dependendo do contexto. A seguir, continuaremos explorando tudo isso e mais.
Observação: Devido à mudanças recentes na biblioteca, é necessário incluir
x=notas.notaao chamarsns.boxplotpara garantir que o gráfico seja exibido na orientação vertical. Exemplo:sns.boxplot(x=notas.nota).
Nós já aprendemos a carregar os dados com o Pandas e a analisar os valores em um dataframe ou uma série, seja em uma tabela ou em um array.
Dessa vez, queremos explorar esses mesmos dados, mas de maneira visual. A impressão visual de um conjunto de dados é chamada de "plotar" (plot), e o Pandas possui um método plot() justamente para isso.
Inicialmente, plotaremos nossa série de dados com notas.nota.plot().
A declaração
notas.notaé uma maneira mais sintática de expressarmos os dados da coluna "nota", e que usaremos ao longo do curso toda vez que estivermos nos referindo aos dados de somente uma coluna.
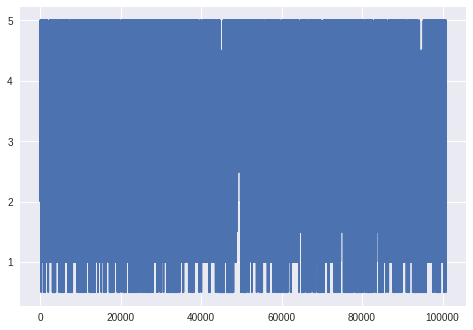
Esse gráfico não parece fazer muito sentido, não é? As notas realmente estão no y, mas o que são os números de 0 a 100.000 no eixo x? Por padrão, o gráfico plot() de uma série cruza os índices da tabela com os valores da coluna que apontamos (no caso, nota), criando pontos para cada resultado. Todos os pontos são, então, ligados por retas, gerando o gráfico ilegível da imagem acima.
Na verdade, queremos saber quantas vezes cada informação aparece nesse conjunto de dados, o que pode ser visualizado em um histograma. Para gerá-lo, usaremos, no método plot(), o argumento kind com o valor hist:
notas.nota.plot(kind='hist')
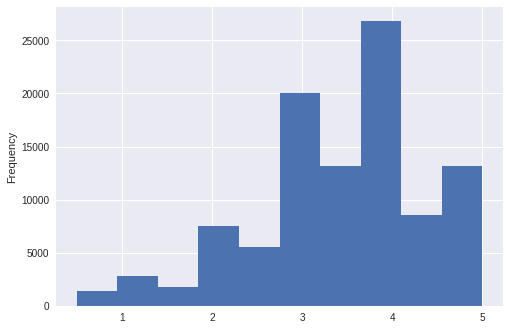
Analisando o histograma, perceberemos que a nota 5 apareceu diversas vezes; a nota 4,5 nem tantas; a nota 4 é a que mais apareceu. Ao longo do curso, iremos explorar nossos dados tanto de maneira numérica, quanto com medidas (por exemplo a média) ou visualizações.
Vamos supor agora que metade das notas do nosso conjunto são maiores que 3, e a outra metade são menores. Mas e se quiséssemos saber exatamente qual é o valor que divide nossos dados na metade? Esse valor é a mediana ("median"). Para efeito de comparação, vamos imprimir tanto a média quanto a mediana na tela.
print("Média",notas['nota'].mean())
print("Mediana",notas['nota'].median())
Como resultado, teremos:
Média 3.501556983616962
Mediana 3.5
Nesse caso, a mediana foi muito próxima da média, mas isso não é uma garantia. É possível, ainda, tirar essas e outras medidas de uma só vez, pedindo o describe() dessa série (ou de um dataframe):
notas.nota.describe()
count 100836.000000
mean 3.501557
std 1.042529
min 0.500000
25% 3.000000
50% 3.500000
75% 4.000000
max 5.000000
Name: nota, dtype: float64
Saberemos, assim, que temos 100.836 dados; a média das notas é 3.501557; o valor mínimo é 0,5; o máximo é 5; a mediana é 3.5; 25% dos dados (um quartil) estão abaixo de 3; e outros 25% estão acima de 4.
Outra visualização que nos permite analisar esses dados é o boxplot, que descreve em uma espécie de "caixa" a posição dos valores plotados. Para gerá-lo, teremos que utilizar outra famosa biblioteca de visualização do Python: o Seaborn.
Primeiramente, importaremos essa biblioteca com import seaborn as sns (a importação padrão). Em seguida, chamaremos a função sns.boxplot(), passando como parâmetro notas.nota. Executando o código, teremos:
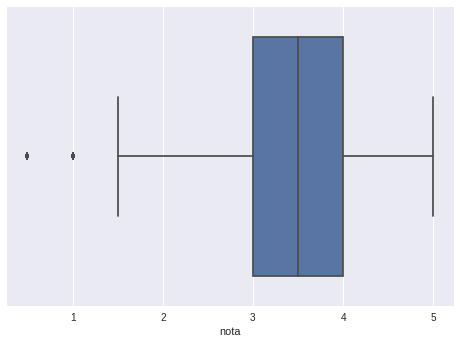
A mediana está representada no meio do retângulo azul — ou seja, no 3,5, dividindo, em duas partes, 50% dos dados (entre 3 e 3,5, e entre 3,5 e 4. Outros 25% dos nossos dados estão entre 4 e 5, e o restante está abaixo de 3.
Com todas essas análises, que tipo de informações podemos extrair? Uma delas é que metade dos usuários (uma parcela muito grande!) deu avaliações entre 3 e 4, e que as notas entre 0,5 e 1,5 figuram pouco significativamente nessa amostra.
Na estatística, existem diversos tipos de análises e visualizações de dados, e motivos para empregá-las. Já aprendemos algumas, mas se quiser conhecê-las mais a fundo, não deixe conferir nossos cursos de Data Analysis e Data Visualization!
O curso Data Science: analise e visualização de dados possui 127 minutos de vídeos, em um total de 41 atividades. Gostou? Conheça nossos outros cursos de Exploração de Dados em Dados, ou leia nossos artigos de Dados.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Back-end, Dados, Front-end, DevOps, Mobile, Gestão & Negócios, UX & Design, Cibersegurança, Cloud, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Catálogo de tecnologia para quem é da área de Marketing
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
20% de desconto na Pós Tech
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Acesso ao catálogo da Casa do Código e leitura dentro da plataforma
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






