
 Inteligência Artificial
Inteligência Artificial
 Inteligência Artificial
Inteligência Artificial Inteligência Artificial
Inteligência Artificial Inteligência Artificial
Inteligência Artificial Inteligência Artificial
Inteligência Artificial
 Inteligência Artificial
Inteligência Artificial Inteligência Artificial
Inteligência Artificial
 Inteligência Artificial
Inteligência Artificial Inteligência Artificial
Inteligência Artificial Inteligência Artificial
Inteligência Artificial
 Inteligência Artificial
Inteligência Artificial
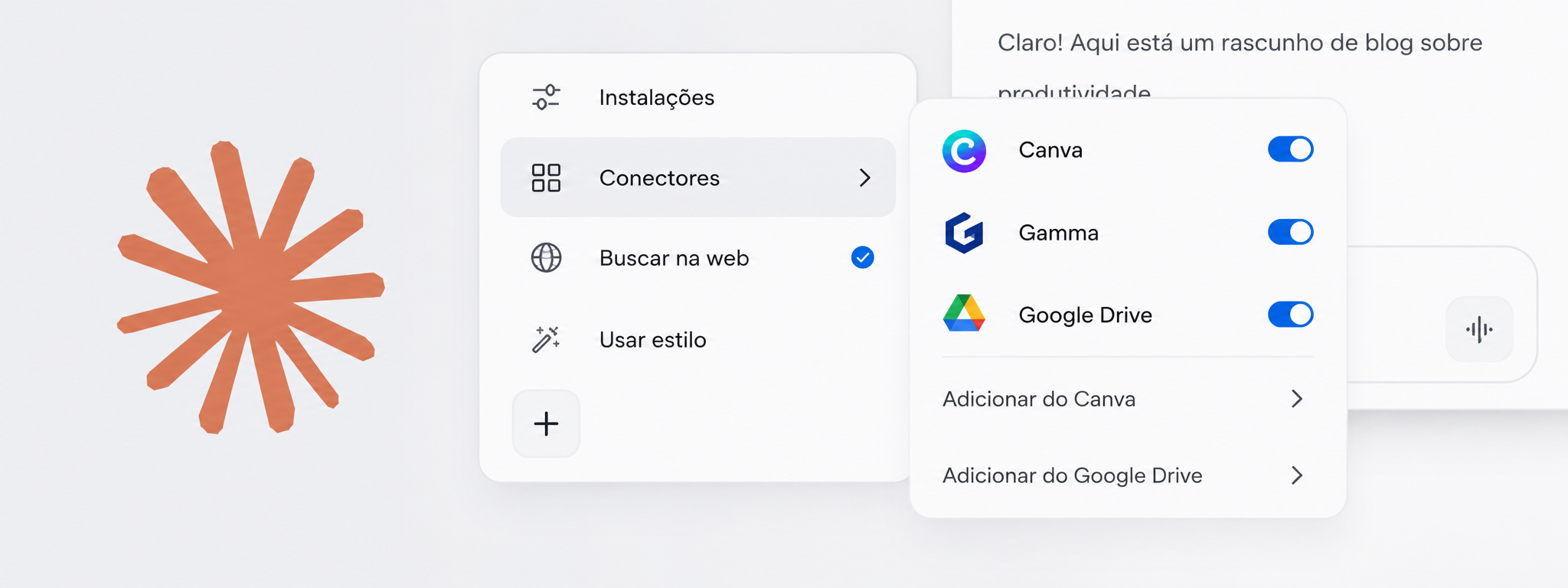 Inteligência Artificial
Inteligência Artificial Inteligência Artificial
Inteligência Artificial Inteligência Artificial
Inteligência Artificial

