Boas-vindas! Meu nome é Vinicius Dias, serei seu instrutor neste curso de PostgreSQL sobre comandos DML e DDL.
Neste curso, vamos aprender sobre modelagem de dados, entendendo o funcionamento de estruturas em um servidor de banco de dados, como o conceito de schemas do PostgreSQL. Apesar de existirem treinamentos específicos sobre modelagem de banco de dados em geral, aplicaremos nossos conhecimentos com PostgreSQL.
Estudaremos a diferença entre comandos DDL e DML, respectivamente, Data Definition Langugage e Data Manipulation Language. Descobriremos mais sobre comandos como CREATE DATABASE E CREATE TABLE, além de novas sintaxes, tabelas temporárias e relatório. Como comentamos, também vamos compreender melhor o que são schemas, os esquemas do banco de dados em que podemos separar elementos.
Exploraremos mais a fundo o comando INSERT, aprendendo a usá-lo a partir de um SELECT. Também descobriremos detalhes sobre o UPDATE, realizando a atualização de uma tabela a partir de outra. Vamos conhecer os conceitos de transações: BEGIN, ROLLBACK e COMMIT.
Finalmente, ainda estudaremos importação e exportação de dados e relatórios. Trabalharemos com particularidades do PostgresSQL, como sequências e criação de tipos.
Em caso de dúvidas, você pode recorrer ao fórum. Temos uma comunidade muito solícita de pessoas alunas, moderados e instrutoras para te ajudar! Vamos estudar?
Vamos fazer uma revisão de conceitos de banco de dados que aprendemos anteriormente.
Ao trabalhar com um banco de dados, sempre precisamos ao menos de um servidor. Em resumo, um servidor é um computador em que armazenamos o software que cuida dos dados e os dados em si. Nesse servidor, por exemplo, podemos instalar o PostgreSQL — um software de gerenciamento de banco de dados.
Nesse computador, conseguimos criar vários bancos de dados (também chamados de bases de dados). Um banco de dados é uma separação no disco rígido (um HD) na qual gerenciamos tudo que queremos armazenar, é onde definiremos o que chamamos de schema. Por exemplo, é possível ter um banco de dados para cada aplicação da nossa empresa.
Em um servidor, podemos ter vários bancos de dados. Em cada banco de dados, podemos ter várias tabelas (ou entidades). Cada tabela armazena várias informações.
Semelhante a uma planilha do Excel, tabelas têm linhas e colunas. Porém, ao criar uma tabela em um banco de dados, é preciso especificar suas colunas. Cada coluna tem algumas definições, como o tipo de dados e outras restrições.
Sendo assim, se uma coluna foi definida com o tipo inteiro, todos os registros (ou linhas) devem ser do tipo inteiro. Se uma coluna for definida com o tipo VARCHAR de 220 caracteres, não conseguiremos incluir um texto de 500 caracteres.
Entre outras restrições, poderíamos informar que uma coluna é única, de modo que será impossível a existência de registrados duplicados nela. Como exemplo, vamos pensar em uma coluna de e-mails de clientes. Sempre que uma inserção for feita, o sistema verificará se o e-mail informado já não consta nessa tabela
Uma restrição muito importante é a chave primária (primary key). Trata-se de um campo que identifica um registro de forma única. Como exemplo, vamos considerar uma tabela com nome de pessoas. Sabemos que duas pessoas podem ter o mesmo nome, porém não o mesmo CPF. Logo, o CPF pode ser a chave primária para garantir a diferenciação de uma pessoa das demais.
Ao utilizar bancos de dados relacionais, é muito comum ter um campo específico de identificação e que não necessariamente faça parte do domínio (como o CPF). Usa-se uma coluna chamada "ID", "Código" ou "Identificador", por exemplo.
Junto do ID, uma funcionalidade interessante é o autoincremento. Assim, ao inserir um novo registro, o próprio banco de dados se encarrega se incrementar o número do ID. Neste curso, aprenderemos uma maneira diferente de trabalhar com esse conceito.
A chave estrangeira (foreign key) é um campo que permite relacionamentos entre tabelas.
Recapitulando: um servidor pode ter vários bancos de dados, que podem ter várias tabelas, que podem ter várias colunas (com tipos e restrições), que podem ter vários registros. Trata-se de uma revisão sucinta do que já aprendemos sobre esquema de banco de dados.
A seguir, um diagrama representando os tópicos abordados neste vídeo:
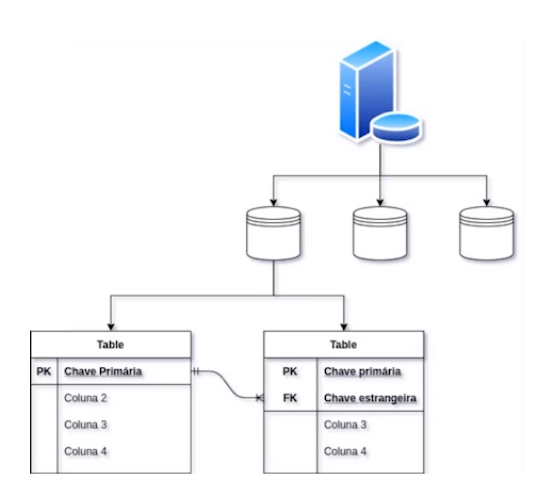
No próximo, começaremos a aprender novos conceitos.
Vamos aprender sobre outro tipo de separação no PostgreSQL. Como comentamos, há servidores com bancos de dados, dentro dos quais criamos tabelas. Porém, é possível ter mais uma camada de separação de tabelas.
Para esclarecer, vamos considerar um exemplo, a seguir. Desenvolvendo o sistema da Alura, notamos que temos conceitos como alunos e cursos, que fazem parte da área acadêmica da empresa. As tabelas dessa área podem ficar separadas em um schema com o rótulo "Acadêmico". Por outro lado, também existem conceitos como pagamentos e matrículas financeiras, cujas tabelas podem ficar separadas em um schema com rótulo "Financeiro":
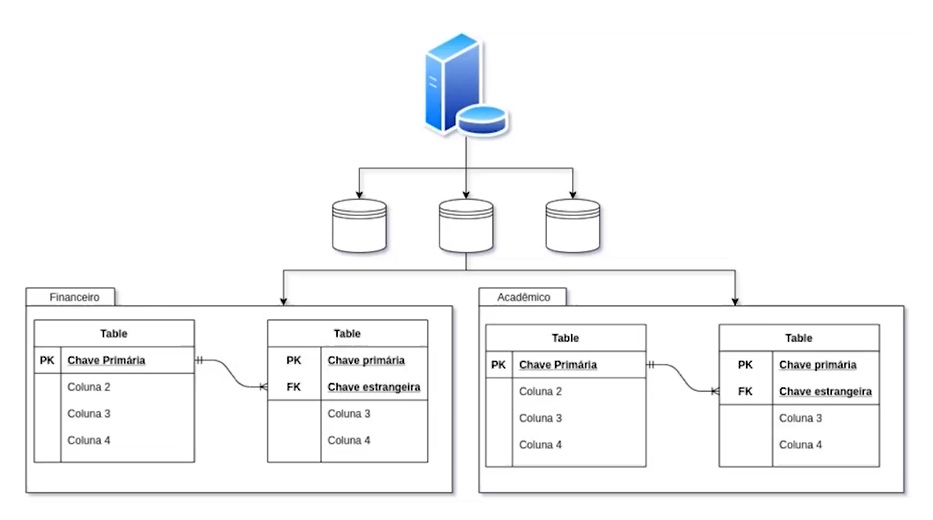
Assim, temos uma separação eficaz. Inclusive, é possível ter tabelas com o mesmo nome em schemas diferentes. Por exemplo, podemos ter uma tabela chamada "Matrícula" no schema financeiro e outra tabela chamada "Matrícula" no schema acadêmico. Não haverá conflitos, mesmo que estejam no mesmo banco de dados.
A seguir, vamos aprender como trabalhar com schemas no PostgreSQL. Na verdade, descobriremos que já estamos trabalhando com eles!
No último curso, usamos o pgAdmin para criar um banco de dados chamado "alura", com as tabelas "aluno", "categoria", "curso" e "aluno_curso". O código resultante foi o seguinte:
CREATE DATABASE alura;
CREATE TABLE aluno (
id SERIAL PRIMARY KEY,
primeiro_nome VARCHAR(255) NOT NULL,
ultimo_nome VARCHAR(255) NOT NULL,
data_nascimento DATE NOT NULL
);
CREATE TABLE categoria (
id SERIAL PRIMARY KEY,
nome VARCHAR(255) NOT NULL UNIQUE
);
CREATE TABLE curso (
id SERIAL PRIMARY KEY,
nome VARCHAR(255) NOT NULL,
categoria_id INTEGER NOT NULL REFERENCES categoria(id)
);
CREATE TABLE aluno_curso (
aluno_id INTEGER NOT NULL REFERENCES aluno(id),
curso_id INTEGER NOT NULL REFERENCES curso(id),
PRIMARY KEY (aluno_id, curso_id)
);
Criamos várias tabelas, sem nos preocupar com schemas. Porém, no PostgresSQL, sempre trabalhamos em algum schema! Se não o especificamos, automaticamente usamos o padrão, chamado "public". No painel à esquerda do pgAdmin, em "Servers > postgres > Databases > alura > Schemas", encontraremos o schema "public". Ou seja, o "public" é o schema padrão, mas temos a opção de criar outros schemas.
Para criar um schema chamado "academico", vamos digitar o seguinte comando ao final do arquivo:
CREATE SCHEMA academico;
Após executar essa query, é preciso atualizar os schemas. No painel à esquerda do pdAdmin, basta clicar com o botão direito sobre "Schemas" e selecionar "Refresh...". Agora, acima do "public", consta também o schema "academico".
Vamos apagar todas as tabelas do banco de dados, executando um comando DROP:
DROP TABLE aluno, categoria, curso, aluno_curso;
Em seguida, vamos recriá-las no schema "academico". A partir de agora, para nos referir às tabelas, usaremos o nome do schema como prefixo do nome da tabela. Ou seja, em vez de apenas "curso", usaremos "academico.curso" e assim em diante. Utilizando essa sintaxe, conseguiremos usar schemas em qualquer tipo de query — seja em um comando CREATE TABLE (como faremos a seguir) ou em DROP TABLE, SELECT, INSERT, entre outros.
Primeiramente, criaremos as tabelas "aluno", com o seguinte código:
CREATE TABLE academico.aluno (
id SERIAL PRIMARY KEY,
primeiro nome VARCHAR(255) NOT NULL,
ultimo_nome VARCHAR(255) NOT NULL,
data_nascimento DATE NOT NULL
);
Repetiremos o processo com a tabela "categoria":
CREATE TABLE academico.categoria (
id SERIAL PRIMARY KEY,
nome VARCHAR(255) NOT NULL UNIQUE
);
Na criação da tabela "curso", fazemos referência à tabela "categoria" gerada anteriormente. Não podemos nos esquecer de colocar o prefixo "academico." nela também. Do contrário, o sistema buscaria uma tabela chamada "academico" no schema "public":
CREATE TABLE academico.curso (
id SERIAL PRIMARY KEY,
nome VARCHAR(255) NOT NULL,
categoria_id INTEGER NOT NULL REFERENCES academico.categoria(id)
);
O comando de criação da tabela "aluno_curso" também referencia outras tabelas:
CREATE TABLE academico.aluno_curso (
aluno_id INTEGER NOT NULL REFERENCES academico.aluno(id),
curso_id INTEGER NOT NULL REFERENCES academico.curso(id),
PRIMARY KEY (aluno_id, curso_id)
);
No painel à esquerda, clicaremos com o botão direito sobre o schema "academico" e selecionaremos "Refresh..." para atualizar. Agora, em "Schemas > academico > Tables", teremos quatro tabelas.
A seguir, vou contar uma experiência profissional que tive, lidando com schemas separados. Eu trabalhei em uma empresa com um banco de dados bastante grande. Nele havia aproximadamente uma centena de schemas, cada um com cerca de cem tabelas.
Para evitar digitar nomes extensos de schemas, a equipe de modelagem de banco de dados optou por abreviar nomes. O schema financeiro chama-se "fin"; o schema de matrículas chama-se "mat"; o de informações de sistemas, "sis".
Não existe nenhuma regra ou recomendação quanto à nomeação de schemas. A equipe de analistas de requisitos, junto do time de modelagem de banco de dados e outras pessoas responsáveis podem definir quais padrões de nomes serão usados.
Em bancos de dados simples, que possuem apenas alguns CRUDs, não é necessário ter schemas. Em modelos maiores, em que pode existir tabelas ambíguas ou muitos domínios, é interessante fazer a separação por schemas para manter a organização dos projetos.
Neste curso, provavelmente focaremos apenas no schema acadêmico.
Caso você tenha familiaridade com programação orientada a objetos, é possível que você conheça conceitos como módulos, pacotes ou namespaces. Trata-se do mesmo conceito de schemas, é uma separação lógica.
No vídeo, conversaremos sobre análise de requisitos e modelagem.
O curso PostgreSQL: comandos DML e DDL possui 101 minutos de vídeos, em um total de 47 atividades. Gostou? Conheça nossos outros cursos de SQL e Banco de Dados em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Catálogo de tecnologia para quem é da área de Marketing
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Acesso ao catálogo da Casa do Código e leitura dentro da plataforma
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






