Olá! Te desejo boas-vindas ao curso de Classificação: aprendendo a classificar dados com Machine Learning! Meu nome é João Miranda e serei seu instrutor nesta jornada.
Audiodescrição: João se descreve como um homem branco, com cabelos escuros e grandes amarrados em um coque, com as laterais raspadas. Possui sobrancelhas grossas e usa barba e bigode rentes ao rosto. Veste uma camiseta lisa na cor preta e está sentado em uma cadeira gamer nas cores preto e branco. Ao fundo, uma parede lisa com uma gravura d'O Senhor dos Aneis sob iluminação azul.
Você provavelmente já ouviu falar dos termos Inteligência Artificial e Machine Learning (Aprendizado de Máquinas). Neste curso, focaremos exatamente nisso. Através de um projeto prático, aprenderemos os conceitos iniciais de classificação com Machine Learning.
Abordaremos esses questionamentos para que, no final, você possa construir um projeto de Machine Learning com classificação, desde o carregamento dos dados e a análise exploratória, até a exportação de um modelo capaz de classificar dados.
Neste curso, não vamos explorar conceitos muito avançados, pois ele é voltado para pessoas que estão iniciando na área. Para aproveitá-lo melhor, é necessário ter conhecimento em linguagem de programação Python.
Vamos nessa?
Temos o seguinte problema de negócio: um banco está fazendo uma campanha de marketing e quer prever quais clientes vão aderir a um investimento que está sendo oferecido a eles. Com isso, o banco pode ser mais eficiente e contatar os clientes que realmente terão interesse.
Apesar de ninguém conseguir prever o futuro, hoje em dia, nós conseguimos utilizar Machine Learning (Aprendizado de Máquina) para fazer esse tipo de previsão baseando-se em dados. Para realizar essa previsão, nós precisamos de dados históricos de clientes de campanhas de marketing anteriores, com a informação dos clientes que aderiram ou não ao investimento. Além disso, necessitamos das características desses clientes para que seja possível extrair algum padrão e chegar na resposta de aderência do investimento.
Essa tarefa é conhecida como classificação em Machine Learning. Nós podemos utilizar algoritmos que vão compreender o padrão dos dados e classificar os clientes entre os que vão aderir ao investimento e os que não vão. Em todo projeto de Machine Learning precisamos de dados, em nosso caso não será diferente. Portanto, utilizaremos uma base de dados de marketing do banco e vamos usar o Python no Google Colab para fazer essas previsões.
O primeiro passo é fazer o upload do arquivo para o Colab e fazer a leitura dos dados.
No Google Colab, vamos em "Arquivos", no menu lateral, e selecionamos a opção "Fazer o upload para o armazenamento da sessão". Em seguida, selecionamos o arquivo em formato CSV que foi disponibilizado para você na atividade "Preparando o Ambiente".
Se você não fez o download dos dados, volte a esta atividade e baixe o arquivo necessário.
O upload do arquivo será feito para a aba de "Arquivos" do Colab. Antes de fechar essa aba, vamos clicar nos três pontos ao lado do nome do arquivo e selecionar a opção "Copiar caminho". Assim, ele vai copiar para a área de transferência do computador o caminho dessa pasta de arquivos.
Agora, podemos fechar o menu e fazer a leitura desse arquivo, utilizando a biblioteca Pandas. Então, na primeira célula, vamos importar esta biblioteca para conseguirmos ler os dados. Vamos apelidá-la de pd:
import pandas as pd
Executamos esse comando teclando "Ctrl + Enter".
Na célula seguinte, vamos armazenar esses dados em uma variável chamada dados. Eles serão lidos pela função read_csv(), da biblioteca Pandas, para a qual passaremos o caminho do arquivo que copiamos anteriormente entre aspas simples:
dados = pd.read_csv('/content/marketing_investimento.csv')
Vamos executar essa célula para fazer a leitura dos dados.
Agora que já fizemos a leitura, podemos visualizar esse dataframe apenas chamando a variável dados na célula seguinte.
dados
idade estado_civil escolaridade inadimplencia saldo fez_emprestimo tempo_ult_contato numero_contatos aderencia_investimento 0 45 casado (a) superior nao 242 nao 587 1 sim 1 42 casado (a) medio nao 1289 nao 250 4 sim 2 23 solteiro (a) superior nao 363 nao 16 18 nao 3 58 divorciado (a) superior nao 1382 nao 700 1 sim 4 50 casado (a) medio nao 3357 nao 239 4 sim ... ... ... ... ... ... ... ... ... ... 1263 52 solteiro (a) superior nao 83 nao 1223 6 sim 1264 35 solteiro (a) superior nao 5958 nao 215 1 sim 1265 30 solteiro (a) superior nao -477 sim 1532 2 sim 1266 42 casado (a) superior nao 2187 nao 525 3 sim 1267 29 solteiro (a) superior nao 19 nao 110 2 sim
Nessa tabela, conseguimos visualizar os dados, que incluem a informação da idade dos clientes, o estado civil, escolaridade, inadimplência, saldo e assim por diante.
Temos várias características a respeito desses clientes e a última coluna da nossa base de dados é chamada de aderencia_investimento. Essa coluna contém a resposta para sabermos se aquele cliente aderiu à campanha ou não. Nela temos o valor de "sim", caso a pessoa tenha aderido e feito o investimento com base na campanha de marketing, e "não" caso ela não tenha feito.
Na nossa base de dados, é importante que essa coluna já esteja presente e já saibamos qual é a resposta para ensinarmos o algoritmo que vamos utilizar. Com base nas características que existem na base de dados, podemos inferir como se chega naquela resposta. A partir disso, com base nessa regra que irá criar, conseguirá fazer as previsões posteriores.
A coluna aderencia_investimento é chamada de variável alvo, pois é a variável que nós queremos fazer a previsão.
Entretanto, temos um problema em nossa base, pois não conseguimos visualizar todos os dados. Conseguimos ver somente as cinco primeiras e as cinco últimas linhas da base de dados. Nas reticências existem muitos outros dados que não conseguimos visualizar.
Caso tenha algum valor faltante, isso seria um problema no momento do algoritmo compreender esse padrão, porque ele precisa de informações a respeito dos clientes. Se algumas informações estiverem faltando, ele não vai compreender como fazer a classificação daquele cliente.
Então, precisamos detectar se existem valores faltantes na nossa base de dados. Para isso, utilizaremos o método info da biblioteca Pandas, da seguinte maneira:
dados.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1268 entries, 0 to 1267
Data columns (total 9 columns):
# Column Non-Null Count Dtype --- ------ -------------- ----- 0 idade 1268 non-null int64 1 estado_civil 1268 non-null object 2 escolaridade 1268 non-null object 3 inadimplencia 1268 non-null object 4 saldo 1268 non-null int64 5 fez_emprestimo 1268 non-null object 6 tempo_ult_contato 1268 non-null int64 7 numero_contatos 1268 non-null int64 8 aderencia_investimento 1268 non-null object dtypes: int64(4), object(5)
memory usage: 89.3+ KB
Como retono, nos são mostradas quantas linhas tem na base de dados, a quantidade de colunas e a informação de cada uma das colunas. Além de mostrar o tipo daquela coluna, se é do tipo inteiro ou tipo object, também nos é mostrada a quantidade de dados não nulos de cada coluna.
Na base de dados temos 1.268 linhas e aqui está informando que em cada uma das colunas existem 1.268 dados não nulos, isso indica que não existe nenhum valor nulo na nossa base de dados.
Sendo assim, não precisaremos fazer tratamentos para lidar com dados nulos. Mas, caso você esteja trabalhando com uma base de dados que tenha dados nulos, é preciso primeiro fazer um tratamento, já que não podemos utilizar os dados nulos em algoritmos de Machine Learning. Isso porque eles precisam de informação para fazer a classificação, que no nosso caso é de clientes que estão aderindo ao investimento.
Agora que já conhecemos os nossos dados, identificamos a variável alvo e vimos que não existe nenhum valor nulo na nossa base de dados, podemos prosseguir com a análise para entender melhor os nossos dados. Isso porque, apesar de termos identificado que não tem nenhum dado nulo, não conseguimos visualizar todas as informações das colunas. Portanto, vamos primeiro explorar os nossos dados para depois prosseguir com a construção do algoritmo capaz de classificá-los!
Nós já fizemos a leitura da nossa base de dados e não encontramos nenhum valor nulo. Isso é um bom indicativo de que não precisamos fazer nenhum tratamento nesse sentido. No entanto, ainda sabemos pouco sobre os dados.
Conseguimos visualizar apenas as cinco primeiras e as cinco últimas linhas de nossa base. A partir disso, não é possível entender como todas as colunas e valores estão funcionando. Por exemplo, na coluna "estado_civil", identificamos as categorias "casado(a)", "solteiro(a)" e "divorciado(a)". No entanto, não conseguimos determinar se essas são as únicas categorias existentes.
Além disso, podemos ter inconsistências nos dados. Por exemplo, se houver algum valor nessa coluna escrito "casado(a)" de maneira diferente, com todas as letras maiúsculas, nosso algoritmo de Machine Learning poderá identificar que essa categoria é diferente da categoria "casado(a)", mesmo que signifiquem a mesma coisa.
Por isso, precisamos examinar nossos dados. É importante fazer isso para entender se existem inconsistências e garantir que passamos informações de qualidade para o algoritmo aprender da melhor forma possível.
Nas colunas numéricas, por exemplo, "idade", não é possível compreender o intervalo que essa coluna abrange. Não conhecemos o valor mínimo ou máximo nem se existem valores inconsistentes. Por exemplo, uma idade maior que 200 anos ou uma idade negativa seriam valores impossíveis no mundo real e, portanto, atrapalhariam a compreensão do problema pelo algoritmo.
Além disso, a coluna "aderencia_investimento" é do tipo textual, ou seja, é uma coluna categórica. Essa é a característica principal para definirmos que nosso problema é do tipo de classificação. Se a coluna que estivéssemos fazendo a previsão fosse numérica, estaríamos fazendo uma regressão. Portanto, a característica categórica da coluna "aderencia_investimento" indica que nosso processo é do tipo de classificação.
Agora, vamos avançar para a etapa de examinar nossos dados, conhecida como análise exploratória de dados. Esta etapa é muito importante, pois nos ajuda a identificar inconsistências em nossos dados e corrigi-las antes de passá-los para o algoritmo.
Para realizarmos a análise exploratória, vamos utilizar a biblioteca gráfica Plotly para visualizar nossos dados de forma mais intuitiva.
Em uma célula vazia, importaremos o módulo express, da biblioteca Plotly, dando a ele o apelido de px:
import plotly.express as px
Vamos executar.
O primeiro gráfico que construiremos é para as variáveis categóricas, portanto, vamos explorar primeiro as colunas com formato textual. Utilizamos o histograma, que realiza uma contagem desses valores, nos permitindo ver quais são as categorias de cada uma dessas colunas.
Começaremos com a coluna "aderencia_investimento", que é a variável alvo. Usaremos px.histograma(), passando os dados e de qual coluna queremos fazer o histograma. Além disso, passaremos o parâmetro text_auto=True para colocar a informação numérica da contagem de cada uma das barras na própria barra:
px.histogram(dados, x = 'aderencia_investimento', text_auto = True)
Vamos executar.
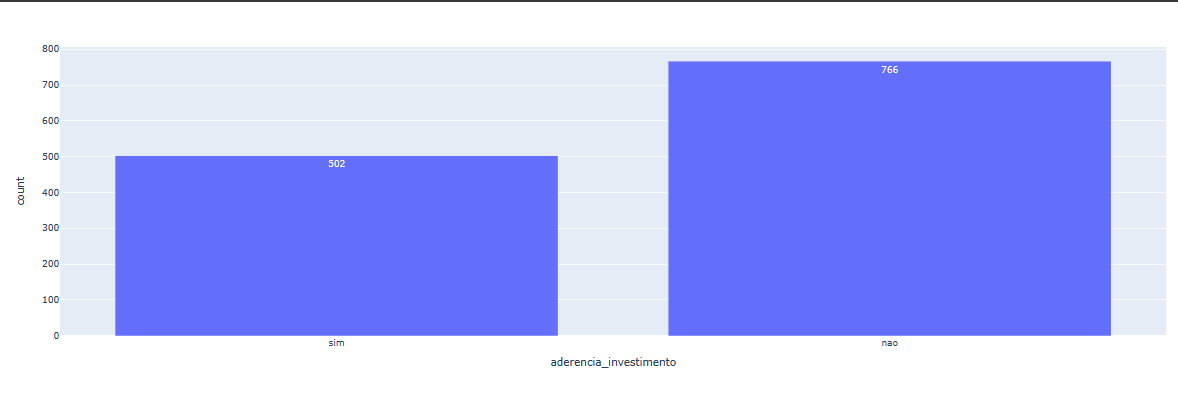
Nesse histograma, identificamos duas características na coluna: "sim" e "não", com 766 valores para "não" e 502 para "sim". Com isso, já conseguimos entender que não há inconsistências na coluna "aderencia_investimento".
Vamos prosseguir com a exploração das outras colunas. Agora, faremos de "estado_civil". Para isso, podemos copiar o código do histograma que fizemos, colá-lo na próxima célula e fazer as devidas alterações, alterando a coluna para 'estado_civil' e mantendo text_auto.
Além disso, faremos a construção das barras com base em "aderencia_investimento" para conseguirmos visualizar se existe uma diferença no padrão dos dados de cada estado civil com base na aderência. Assim, entenderemos, também, se determinado civil influencia em maior aderência ao investimento. Para isso, usaremos o parâmetro color = 'aderencia_investimento'.
Por fim, para agrupar as barras com base no estado civil, usaremos barmode = 'group'.
px.histogram(dados, x = 'estado_civil', text_auto = True, color = 'aderencia_investimento', barmode = 'group')
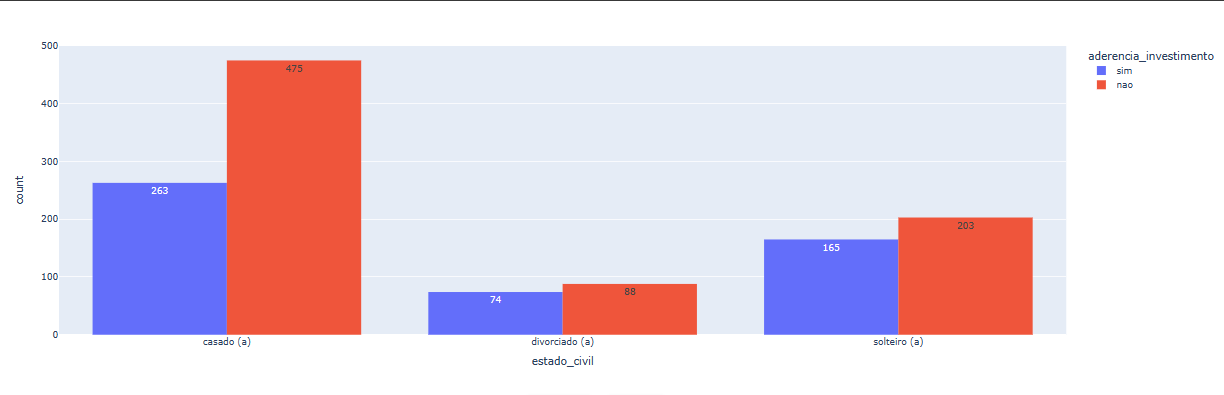
Note que ele agrupou as barras com base no estado civil e fez uma separação de cores com base na aderência, mostrando a contagem de cada um deles e permitindo entender como o estado civil influencia na aderência ao investimento.
É possível perceber que as pessoas casadas tendem a não aderir ao investimento. Já nas categorias de divorciado e solteiro, há um certo equilíbrio, pois os valores de adesão e não adesão estão próximos. Isso é interessante para avaliarmos se existe alguma diferença entre cada característica que possa influenciar na tomada de decisão.
Agora que já compreendemos um pouco sobre a coluna "estado_civil", vamos copiar o código anterior e aplicá-lo às outras colunas.
Para esta próxima análise será necessário alterar somente a variável x para 'escolaridade':
px.histogram(dados, x = 'escolaridade', text_auto = True, color = 'aderencia_investimento', barmode = 'group')
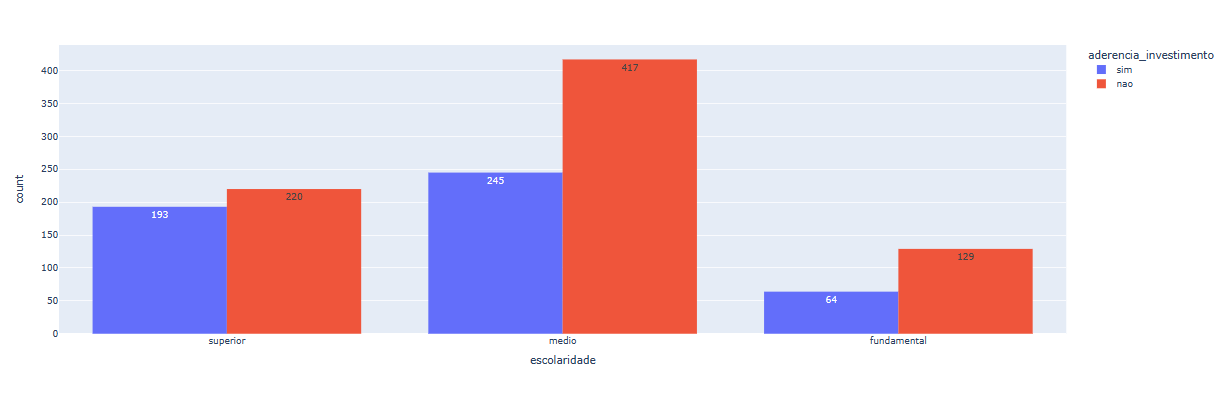
Aqui, somos capazes de visualizar os diferentes níveis de escolaridade em nossa base de dados: superior, médio e fundamental. Se observarmos a escolaridade superior, podemos ver que não há diferença substancial que defina se a pessoa aderirá ou não ao investimento. No entanto, em relação ao ensino médio e fundamental, existe uma variação muito maior entre as quantidades de cada categoria.
Portanto, é um indicativo de que essas informações são importantes para chegar ao resultado esperado de aderência ao investimento. Embora a análise de uma variável isolada não seja suficiente para definirmos uma conclusão, o agrupamento de todas as variáveis tornará a análise mais significativa e nos ajudará a chegar ao resultado esperado.
Vamos copiar novamente este código e seguir para as duas últimas colunas. Dessa vez, em vez de 'escolaridade', usaremos 'inadimplencia'.
px.histogram(dados, x = 'inadimplencia', text_auto = True, color = 'aderencia_investimento', barmode = 'group')
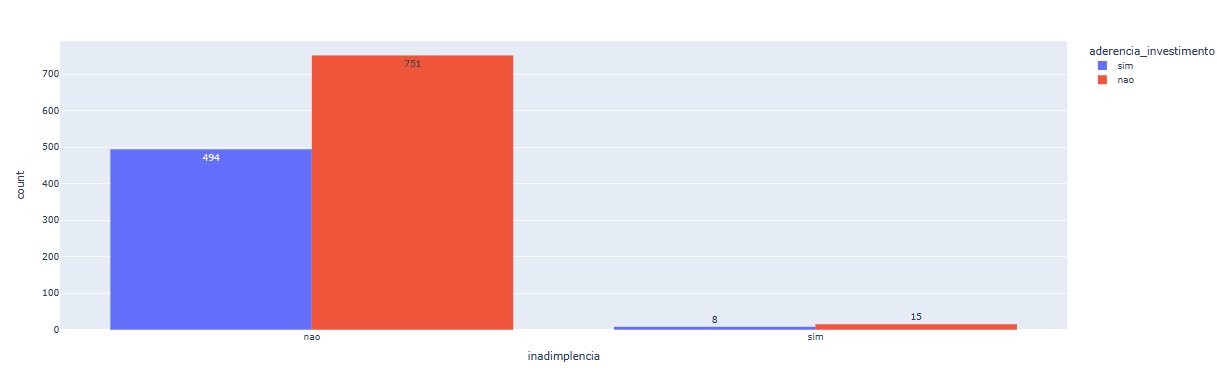
Para inadimplência, existem duas categorias: "não" e "sim". Podemos identificar que existem poucos valores "sim" e muitos valores "não". Também há uma grande diferença proporcional nos valores de "não". Para o valor "sim", a proporção dos dados é bem próxima, mas com poucos valores de "sim".
Agora, vamos partir para a última coluna, referente a se a pessoa fez empréstimo ou não. Para isso, basta aproveitarmos o código alterando o valor de x para 'fez_emprestimo':
px.histogram(dados, x = 'fez_emprestimo', text_auto = True, color = 'aderencia_investimento', barmode = 'group')
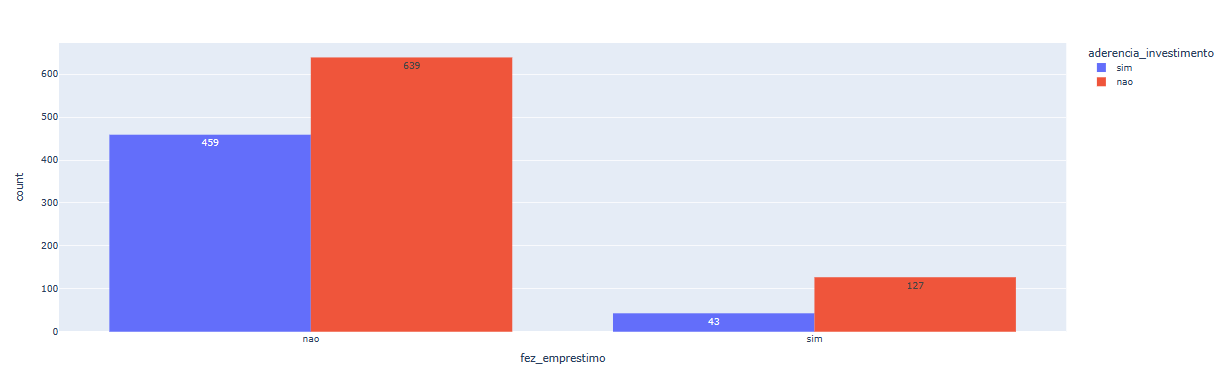
Perceba que para esta coluna existem muito mais valores para "não" do que para "sim".
Conseguimos compreender um pouco melhor nossos dados. Embora seja um processo repetitivo, é fundamental para visualizarmos se existem valores discrepantes, ou não estejam de acordo com o que está descrito em cada característica, para entendermos o padrão desses dados.
No próximo vídeo, exploraremos as variáveis restantes, que são numéricas.
O curso Classificação: aprendendo a classificar dados com Machine Learning possui 133 minutos de vídeos, em um total de 42 atividades. Gostou? Conheça nossos outros cursos de Machine Learning em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Catálogo de tecnologia para quem é da área de Marketing
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Acesso ao catálogo da Casa do Código e leitura dentro da plataforma
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






