até
 % OFF
% OFF
% OFF
% OFFOlá, eu sou a Ana Hashimoto e serei sua instrutora no curso AWS Data Lake: Processamento de dados utilizando o AWS EMR.
Audiodescrição: Ana se autodeclara como uma mulher branca. Seus cabelos são pretos, lisos e compridos, e seus olhos também são pretos. Está vestindo uma camisa preta sem mangas e com detalhes de miçanga na altura do colo. Ao fundo, uma parede lisa e uma porta fechada. O ambiente está sob uma luz esverdeada.
Este curso é voltado para pessoas que desejam aprender sobre AWS na prática.
Nele, faremos o processamento dos dados utilizando o AWS EMR, o serviço ideal para situações em que o processamento escalável e distribuído é necessário para o processamento de grandes volumes de dados.
Para isso, utilizaremos a base de dados do site Data Boston, que atualmente está na camada bronze no nosso Bucket S3 na AWS.
Posteriormente, criaremos nosso cluster EMR, passando as configurações de hardware e software.
Também faremos a criação do nosso script utilizando o Spark. E, em seguida, criaremos nossa camada gold dentro do nosso Data Lake na AWS.
Então, ao finalizar este curso, você será capaz de criar:
Para aproveitar o conteúdo, recomendamos que você tenha conhecimento em Spark e também em Cloud Computing (Computação em Nuvem).
Então, vamos começar a nossa jornada?!
Neste curso, vamos criar a camada Gold contendo as informações do site Data Boston, atualmente localizadas na camada bronze do nosso bucket S3 na AWS.
Como primeira etapa para a criação da nossa pipeline, nosso desafio é compreender a arquitetura da pipeline AWS e também quais serão os serviços utilizados.
É sempre importante entender e fazer um desenho da nossa arquitetura antes de tudo, para evitar retrabalho, pensando na melhor arquitetura e nos melhores serviços para a construção da nossa pipeline.
A seguinte imagem traz um desenho da arquitetura macro de toda a nossa formação de AWS Data Lake até agora: do curso de ingestão de dados, de processamento de dados com a AWS Glue, e agora, de processamento de dados com a AWS EMR.
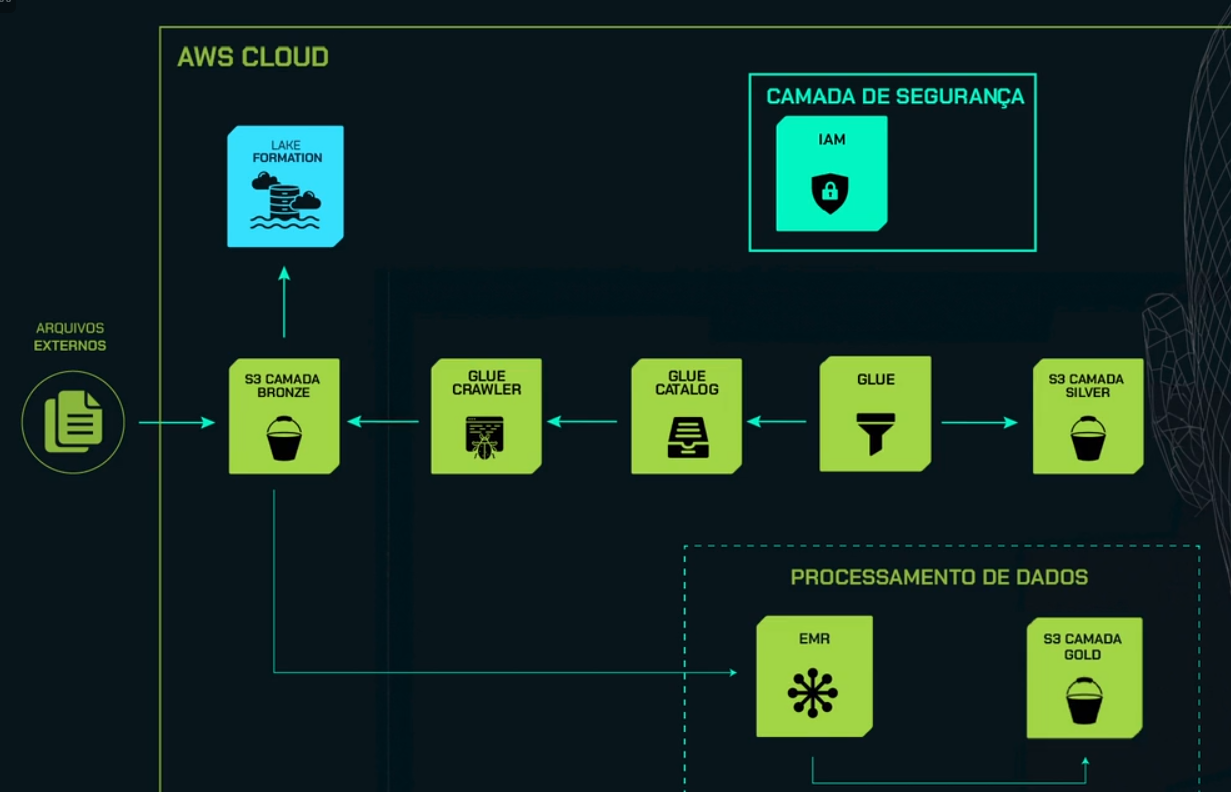
Como primeiro item, temos o círculo à esquerda representando os arquivos estéreos, que são as informações do site Data Boston. Depois, temos um grande quadrado representando todo o ambiente Cloud.
Como primeiro ícone, temos o quadrado verde representando o nosso bucket S3, que, nesse caso, representa a nossa camada bronze. Aqui, fizemos a ingestão das informações do site Data Boston diretamente no nosso bucket S3.
Temos também o ícone em azul representando o Lake Formation, serviço que utilizamos para a criação do nosso Data Lake na AWS.
À direita do S3 camada bronze, temos o ícone do Glue Crawler, que utilizamos para fazer toda a captura das informações que hoje estão no nosso bucket S3 e criação da nossa tabela.
Para isso, criamos a nossa tabela no Glue Catalog, um armazenador de metadados. À direita, temos o ícone do Glue, um serviço muito utilizado para a ETL.
Então, fizemos todo o tratamento e harmonização dos nossos dados brutos, que estão na camada bronze, e criamos a camada silver no nosso bucket S3.
Temos também, na parte superior, a Security Layer (Camada de Segurança). Nesse caso, utilizamos o AWS IAM para não usar o nosso usuário root. Criamos um usuário adicional para criar toda essa pipeline, ou seja, todos esses serviços que apresentamos.
Por fim, temos um quadrado pontilhado na parte inferior direita, que representa a parte de Processamento de Dados, que será o desafio deste curso.
Faremos o processamento de dados utilizando o AWS EMR, e a partir dele, faremos a construção da camada gold no nosso bucket S3.
Lembrando que o AWS EMR é um serviço que não é serverless. Ou seja, diferentemente do Glue, precisamos provisionar a infraestrutura, tanto hardware quanto software.
Neste curso, vamos fazer todas as configurações e também um ETL para a construção da nossa camada gold no nosso bucket S3 na AWS.
No próximo vídeo, vamos começar, de fato, a construção da nossa pipeline para a criação da camada gold. Até lá!
Agora que já compreendemos a arquitetura que será utilizada e temos as informações do site Data Boston na nossa camada bronze, podemos começar a construção da nossa pipeline para processamento dessas informações e criação da camada Gold na AWS.
Para isso, vamos utilizar o AWS EMR, um serviço voltado para processamento de grandes volumes de dados, cuja infraestrutura precisamos provisionar.
O nosso desafio atual é: onde armazenaremos todas essas informações?
Como solução, vamos criar uma nova tabela no nosso Data Lake, utilizando o Lake Formation, e nele vamos especificar qual será o nosso schema.
O schema é o conjunto de informações da nossa tabela, contendo nomes de campo, tipo do dado e também o tamanho desse dado.
Vamos criar uma nova tabela no nosso Lake Formation passando todas essas informações, que será a nossa camada Gold.
Vamos entrar no console da AWS, no navegador. Na barra de pesquisa, no topo esquerdo, vamos digitar "lake formation" e clicar no primeiro ícone dos resultados: AWS Lake Formation.
Na nova tela, teremos numa lista o database que criamos anteriormente. Vamos clicar na opção "Tables", no menu à esquerda, dentro da aba Data Catalog. Aqui temos as tabelas criadas anteriormente: a Silver e a Bronze.
Vamos criar uma nova tabela, chamada Gold, que armazenará todas as informações da nossa camada especializada chamada Gold.
Para isso, vamos clicar no botão "Create Table" no topo direito da tela. Na próxima página, teremos um formulário para configurar os detalhes dessa nova tabela.
No primeiro item, escolhemos se vamos criar uma nova tabela na nossa conta (opção "Table") ou se vamos utilizar um link para uma tabela compartilhada (opção "Resource link"). Nesse caso, vamos escolher a opção Table para criar uma tabela na nossa conta.
No próximo campo, vamos definir um nome para essa tabela. Chamaremos essa tabela de "gold".
Lembrando que é sempre importante definir um nome que remeta ao objetivo pelo qual estamos criando essa tabela.
No próximo campo, "Database", temos que selecionar qual será o banco de dados que armazenará essa tabela. Vamos clicar na lista suspensa e selecionar o database "alura-datalakeaws", o banco de dados que criamos anteriormente.
Não vamos preencher o campo de Descrição nesse momento.
No item "Table format", temos duas opções para a escolha do formato dessa tabela. Podemos tanto escolher o formato padrão (default), o AWS Glue Table, quanto usar o Apache Iceberg Table. Nesse caso, vamos marcar a opção padrão: Standard AWS Glue Table.
No item "Data store", vamos passar o caminho para o diretório em que essas informações estão armazenadas. Vamos selecionar a primeira opção, "Specified path in my account", porque elas estão na nossa conta. No campo de texto "Include path", passamos o caminho para o nosso bucket S3.
Já criamos duas pastas no nosso bucket S3, a camada bronze e a camada silver, porém, não criamos a camada gold ainda. Então, vamos entrar no S3 para fazer isso.
Vamos duplicar a aba do Lake Formation, clicando nela no topo do navegador com o botão direito e selecionando a opção "Duplicar". Na aba duplicada, vamos digitar "S3" na barra de pesquisa da AWS e clicar no primeiro ícone de resultado.
A próxima página vai mostrar todos os buckets que temos atualmente na nossa conta. Vamos clicar no "alura-datalakeaws", o bucket desse curso. Temos apenas a camada bronze e silver nele, como podemos verificar na seção "Objects".
Vamos clicar no botão "Create Folder" no centro da seção, para criar uma nova pasta. Na próxima tela, vamos definir um nome para ela. Nesse caso, será "gold".
Vamos permanecer com as configurações padrão na seção "Server-side encryption", pois não vamos especificar uma encryption.
Por fim, clicamos no botão "Create Folder" na parte inferior direita da tela. Assim, temos agora as três camadas criadas: bronze, silver e gold.
Vamos retornar para a aba do Lake Formation, e agora, sim, selecionar o caminho da pasta em que vamos armazenar essas informações.
Clicamos no botão "Browse" ao lado do campo de texto "Include path" para buscar nossos buckets e selecionar o bucket desse curso, o "alura-datalakeaws".
Em seguida, dentro desse bucket, vamos marcar a pasta "gold" e depois clicar no botão "Select", na parte inferior direita da tela. Assim, selecionamos a camada Gold para armazenar nossas informações.
De volta para a página de criação da tabela, descendo-a um pouco, temos a seção "Data format" para selecionar o formato desses dados. Nesse caso, vamos selecionar a opção "Parquet".
Por fim, na seção de definição do "Schema", temos duas opções: podemos tanto fazer o upload do nosso schema utilizando o JSON quanto adicionar manualmente as nossas colunas. Nesse caso, vamos fazer o upload do nosso schema.
Para isso, vamos clicar no botão "Upload schema". Vamos abrir o arquivo JSON que contém as informações desse schema (Schema_tabela_gold.txt) no bloco de notas, selecionar todo o conteúdo em texto, copiar e colar no campo "Paste a JSON array..." da AWS.
Schema_tabela_gold.txt
[
{
"Name": "case_enquiry_id",
"Type": "long",
"Comment": "Identificador único para cada caso de consulta"
},
{
"Name": "open_dt",
"Type": "timestamp",
"Comment": "Data e hora de abertura do caso"
},
{
"Name": "closed_dt",
"Type": "timestamp",
"Comment": "Data e hora de fechamento do caso"
},
{
"Name": "target_dt",
"Type": "timestamp",
"Comment": "Data e hora alvo do SLA"
},
{
"Name": "case_status",
"Type": "string",
"Comment": "Status do caso"
},
{
"Name": "ontime",
"Type": "string",
"Comment": "Indica se o caso foi resolvido dentro do tempo"
},
{
"Name": "closure_reason",
"Type": "string",
"Comment": "Razão para o fechamento do caso"
},
{
"Name": "case_title",
"Type": "string",
"Comment": "Título do caso"
},
{
"Name": "subject",
"Type": "string",
"Comment": "Assunto do caso"
},
{
"Name": "reason",
"Type": "string",
"Comment": "Razão do caso"
},
{
"Name": "neighborhood",
"Type": "string",
"Comment": "Bairro"
},
{
"Name": "location_street_name",
"Type": "string",
"Comment": "Nome da rua da localização"
},
{
"Name": "location_zipcode",
"Type": "integer",
"Comment": "CEP da localização"
},
{
"Name": "latitude",
"Type": "double",
"Comment": "Latitude da localização"
},
{
"Name": "longitude",
"Type": "double",
"Comment": "Longitude da localização"
},
{
"Name": "source",
"Type": "string",
"Comment": "Fonte do caso"
},
{
"Name": "delay_days",
"Type": "double",
"Comment": "Dias de atraso"
}
]
Esse schema será a estrutura da nossa camada gold, que criaremos ao longo desse curso.
Lembrando que fizemos todo um estudo sobre os campos, o tipo dos dados e os comentários. É sempre recomendado que você coloque comentários para esses campos, para que você tenha mais detalhes sobre eles.
Agora vamos clicar no botão "Upload" na parte inferior direita dessa janela modal para finalizar. Feito isso, teremos a estrutura em formato de tabela automaticamente.
Podemos maximizar as colunas, arrastando-as para a direita, para verificar seus nomes, tipos, partição e comentários.
Descendo a página, vamos clicar no botão "Submit" na parte inferior direita da tela para enviar as definições da tabela.
Pronto! Nossa tabela "gold" foi criada com sucesso. Podemos verificar os detalhes que definimos para ela: nome do database, descrição, localização dessa camada e o schema.
Criamos com sucesso a nossa camada gold, que será o local em que armazenaremos as informações. Ao longo do curso, vamos fazer todo o processamento, o nosso ETL, especialização desse dado, e, por fim, armazená-los nessa tabela que criamos agora.
No próximo vídeo, vamos iniciar as configurações do AWS EMR. Até lá!
O curso AWS Data Lake: processando dados com AWS EMR possui 116 minutos de vídeos, em um total de 37 atividades. Gostou? Conheça nossos outros cursos de SQL e Banco de Dados em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:

O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






