Trabalhando com funções de agregação


Quando desejamos realizar cálculos matemáticos para resolver problemas no nosso cotidiano, recorremos a operações básicas. Um exemplo claro é a adição, utilizada para somar valores, e a subtração, aplicada para obter diferenças.
Na linguagem SQL, não é diferente. Nela, é possível utilizar uma série de funções nativas da linguagem para trabalhar com os diversos tipos de informações que serão armazenados em um banco de dados. Com essas funções, podemos agrupar valores, realizar contas, criar medidas e identificar o maior e o menor valor de um conjunto.
As funções de agregação possibilitam grandes ganhos por possibilitar resumir e analisar grandes conjuntos de dados de maneira eficiente. No entanto, lidar com grandes volumes de dados traz desafios significativos, exigindo uma abordagem mais avançada do que apenas operações básicas. Como podemos, então, utilizar as funções de agregação de maneira eficiente, especialmente ao lidar com cálculos complexos e conjuntos de dados extensos?

A questão central é garantir que nossa prática seja eficaz e resulte em bons resultados consolidados. Neste artigo, vamos demonstrar como utilizar cada função e como os SGBDs SQL Server, MySQL, PostgreSQL e Oracle, trabalham com as funções de agregação. Aproveite a jornada e boa leitura!
Funções de agregação
As funções de agregação na linguagem SQL são fundamentais para a análise e o processamento de grandes volumes de dados. Estas funções permitem realizar cálculos sobre um conjunto de valores e retornar um único valor.
Por isso, são amplamente utilizadas em consultas de banco de dados, especialmente em análises estatísticas, relatórios financeiros e na geração de insights a partir de dados:
Ao todo, existem cinco funções de agregação amplamente utilizadas em todos os bancos de dados e executam agrupamentos diferentes nos conjuntos de dados. Cada uma desempenha agrupamentos específicos nos conjuntos de dados, sendo uma parte crucial do SQL.
Essas funções concedem aos usuários a capacidade de realizar análises complexas e relatórios de forma eficiente e eficaz. Essas funções são listadas abaixo. Perceba a sua característica e o que retornam, respectivamente:
- COUNT: Esta função é usada para contar o número de linhas em uma coluna específica ou no conjunto de resultados. É útil para saber quantos registros atendem a um certo critério.
- SUM: Como o nome sugere, a função
SUMé usada para somar valores de uma coluna. É extremamente útil em situações financeiras, como calcular o total de vendas ou despesas. - AVG (Média): Esta função calcula a média dos valores em uma coluna. É amplamente utilizada em análises estatísticas, como encontrar a média de preços, idades ou qualquer outro valor numérico.
- MAX e MIN: Estas funções são usadas para encontrar o valor máximo e mínimo em uma coluna, respectivamente. São importantes para análises onde você precisa identificar os extremos, como o produto mais caro ou mais barato, por exemplo.
- GROUP BY: Embora tecnicamente não seja uma função de agregação, é frequentemente usada em conjunto com elas. O
GROUP BYagrupa os registros com valores idênticos em certas colunas, permitindo realizar agregações em cada grupo.
A importância dessas funções reside em sua capacidade de simplificar e resumir grandes quantidades de dados, tornando-os mais gerenciáveis e compreensíveis.
Em um cenário empresarial, por exemplo, elas permitem que os gestores obtenham rapidamente informações críticas sobre o desempenho do negócio.
Em pesquisa e análise de dados, facilitam a identificação de tendências, padrões e anomalias, podendo gerar maior aderência e vantagens nos negócios.
Como utilizar as funções de agregação?
Vamos analisar o seguinte exemplo: em um banco de dados, existe a tabela de produtos que armazena as informações de ID (código), Descrição, Embalagem, Preço e Sabor:
| ID | Descrição | Embalagem | Preço | Sabor |
|---|---|---|---|---|
| 1 | Frescor do Verão - Uva | Garrafa | 8.50 | Uva |
| 2 | Linha Refrescante - Laranja | PET | 10.00 | Laranja |
| 3 | Festival de Sabores - Maracujá | Garrafa | 9.50 | Maracujá |
| 4 | Frescor do Verão - Laranja | Lata | 5.00 | Laranja |
| 5 | Festival de Sabores - Maracujá | Lata | 6.00 | Maracujá |
| 6 | Linha Refrescante - Manga | PET | 9.00 | Maracujá |
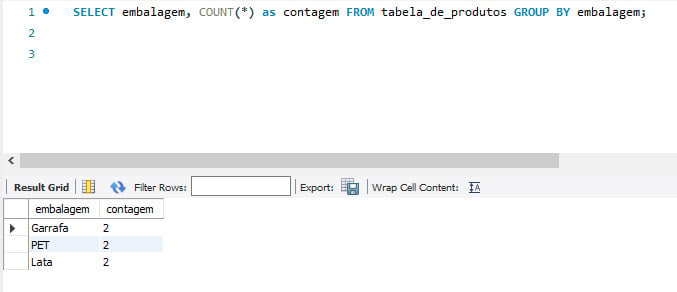
Como o nosso objetivo, neste primeiro momento, é verificar a quantidade de registros existentes na nossa tabela de produtos, categorizando pela embalagem, será possível identificar qual tipo de embalagem possui o maior número de produtos cadastrados dentro do banco de dados. A melhor decisão é:
- COUNT
SELECT embalagem, COUNT(*) as contagem FROM tabela_de_produtos GROUP BY embalagem;
Neste comando,será exibida a contagem das linhas da tabela de produtos por embalagem:
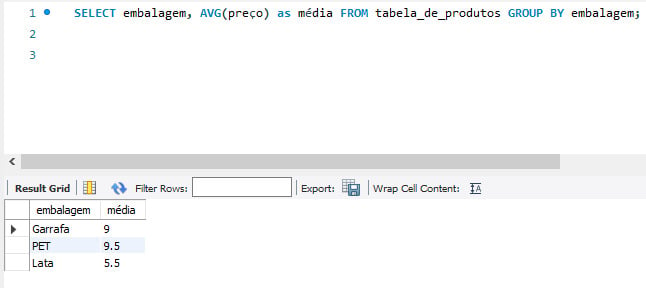
Com os itens verificados, bem como os critérios, é importante saber a média de preço por embalagem para que possamos ser mais assertivos na tomada de decisões, como por exemplo, aumentar o estoque de um produto x, ao invés de algum outro, pelo fato deste ser mais solicitado pelos consumidores. Neste caso, o melhor comando é:
- AVG
SELECT embalagem, AVG(preço) as média FROM tabela_de_produtos GROUP BY embalagem;
Este comando retorna o valor da média aritmética do campo preço por embalagem:
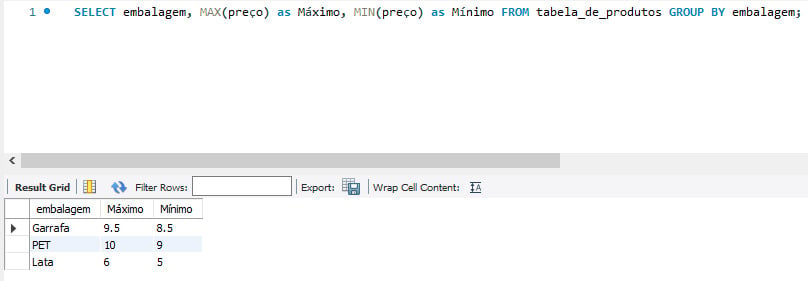
Com a análise realizada temos a possibilidade de comparar o nosso desempenho interno, como também estabelecer preços mais competitivos. Considerando que identificar padrões nos preços (máximos e mínimos por tipo de embalagem) pode auxiliar no acompanhamento de tendências de mercado e na adaptação de estratégias de marketing, o melhor comando é:
- MAX e MIN
SELECT embalagem, MAX(preço) as Máximo, MIN(preço) as Mínimo FROM tabela_de_produtos GROUP BY embalagem;
O comando mostra o valor máximo e o valor mínimo do campo preço por embalagem:
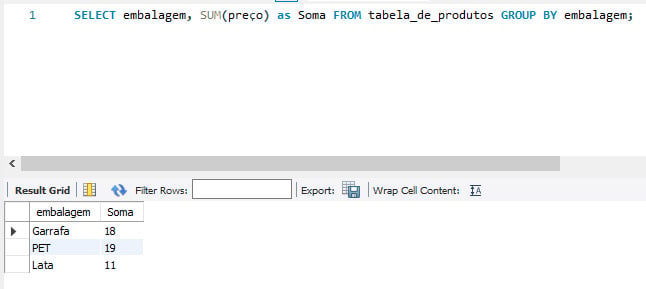
Nesta altura de nossa análise, é importante ter uma visão consolidada da soma total dos valores do campo preço para cada tipo de embalagem na tabela de produtos. Então, para auxiliar na análise de receitas, calcular a soma dos preços na análise total das receitas geradas por cada tipo de embalagem, o melhor comando é:
- SUM
SELECT embalagem, SUM(preço) as Soma FROM tabela_de_produtos GROUP BY embalagem;
O comando SUM retorna a soma dos valores do campo preço por embalagem:
Como cada SGBD trabalha com as funções de agregação
Sistemas de Gerenciamento de Banco de Dados (SGBDs) são softwares projetados para armazenar, gerenciar e facilitar o acesso a grandes volumes de dados.
Eles são essenciais em muitas aplicações modernas, desde websites até sistemas corporativos, oferecendo uma maneira eficiente e segura de organizar, consultar e manipular dados.
Mesmo sendo uma função nativa da linguagem SQL, os SGBDs internamente podem trabalhar de formas diferentes com as funções de agregação. Então, utilizando mais uma vez a nossa tabela de produtos, vamos montar novas consultas com as funções de agregação:
SQL Server, Oracle, MySQL e PostgreSQL
1 - Normalmente nesses SGBDs precisamos informar a cláusula group by que é utilizada para agrupar registros semelhantes de uma tabela em um ou mais campos:
SELECT embalagem , AVG(preco) as Média FROM tabela_de_produtos GROUP BY embalagem;
Dessa forma, vamos retornar o preço médio agrupado por embalagem.
2 - Quando informamos apenas a função de agregação, não é necessário utilizar a cláusula group by no comando:
SELECT SUM(preco) as Soma FROM tabela_de_produtos ;
Será retornado a soma total dos preços dos produtos.
3 - Podemos também aplicar a cláusula group by sem usar uma função de agregação na consulta:
SELECT embalagem FROM tabela_de_produtos GROUP BY embalagem;
Retorna os tipos de embalagem existentes na tabela de produtos de forma distinta.
- Porém, não é permitido realizar consultas quando:
1 - A lista de seleção está com um campo diferente do informado na cláusula group by.
SELECT preco FROM tabela_de_produtos GROUP BY embalagem;
2 - Todos os campos listados na seleção, que não estão em uma função de agregação, não são informadas na cláusula group by:
SELECT embalagem, descricao, AVG(preco) FROM tabela_de_produtos GROUP BY embalagem;
3 - Se houver campos em uma função de agregação, como também outros campos listados na seleção e a cláusula group by não for informada:
SELECT embalagem, AVG(preco) FROM tabela_de_produtos ;
Ao não permitir a execução dessas consultas, os SGBDs garantem que todas as colunas listadas na lista de seleção de uma consulta GROUP BY sejam funcionalmente dependentes das colunas de agrupamento. Em termos simples, isso significa que:
Evita Resultados Indesejados: Ao permitir selecionar colunas que não estão na cláusula GROUP BY ou em uma função agregada, pode levar a resultados não determinísticos ou ambíguos. Isso ocorre porque, sem uma agregação, não fica claro qual valor de uma coluna não agrupada deve ser retornado para cada grupo.
Garante Precisão nas Consultas: É possível assegurar que as consultas com GROUP BY são precisas e consistentes. Isso significa que todas as colunas selecionadas devem estar na cláusula GROUP BY ou ser usadas em funções de agregação (como SUM, AVG, etc.), garantindo que os resultados sejam significativos e corretos.
Padrão SQL: Esta prática está em linha com a norma SQL padrão, que desencoraja selecionar colunas que não estão nem na cláusula GROUP BY nem encapsuladas em funções de agregação.
MySQL
Ao executar consultas no MySQL, utilizamos as funções de agregação normalmente, assim como nos outros SGBDs. Porém, no MySQL, podemos definir como será o funcionamento da cláusula GROUP BY, através do parâmetro sql_mode.
Este parâmetro é usado para controlar diferentes aspectos do comportamento do SQL, influenciando tanto a sintaxe quanto os aspectos operacionais das consultas. O valor ONLY_FULL_GROUP_BY dentro de sql_mode é um destes modos operacionais, e seu papel é bastante específico e importante no que diz respeito ao uso de consultas que envolvem a cláusula GROUP BY.
Quando sql_mode não está definido para incluir ONLY_FULL_GROUP_BY, podemos executar as consultas onde:
- Utilizar as funções de agregação sem a cláusula
GROUP BY; - Utilizar a cláusula
GROUP BYsem as funções de agregação em uma consulta; - Executar consultas onde os campos listados na seleção, que não estão em uma função de agregação, não são informados na cláusula
GROUP BY.
Em algumas versões do MySQL, esta configuração não vem habilitada por padrão, permitindo assim, a execução desses tipos de consultas.
Conclusão
As funções de agregação no SQL são ferramentas poderosas para a análise de dados, permitindo aos usuários resumir e extrair informações valiosas de grandes conjuntos de dados. Elas simplificam a complexidade dos dados, fornecendo meios para calcular somas, médias, contagens e outros tipos de medidas resumidas.
Essencialmente, estas funções transformam grandes volumes de dados em insights concisos e úteis, fundamentais para a tomada de decisões informadas em diversos contextos, desde negócios até a ciência de dados.
Ao serem utilizadas de forma correta, as funções de agregação aumentam significativamente a eficiência e a eficácia da análise de dados em bancos de dados.
Neste artigo, vimos um pouco sobre as cinco funções de agregação nativas da linguagem SQL que são utilizadas por todos os SGBDs: COUNT, SUM, MAX, MIN e AVG. Também apresentamos a execução de cada função e como os SGBDs: SQL Server, MySQL, PostgreSQL e Oracle trabalham internamente com as funções de agregação.
Gostou deste artigo e quer conhecer mais sobre cada SGBD e as funções da linguagem SQL? Então conheça as nossas formações:
- Formação Conhecendo SQL
- Formação Microsoft SQL Server 2022
- Formação PostgreSQL
- Formação Consultas com Oracle Database
- Formação SQL com MySQL Server da Oracle
Créditos
- Criação Textual: Danielle Oliveira
- Produção técnica: Daniel Siqueira
- Produção didática: Cláudia Machado
- Designer gráfico: Alysson Manso
- Apoio: Rômulo Henrique