

Kleber de Paiva Siqueira Costa
Sou o Kleber Costa, atualmente sou SRE no Itaú Unibanco e estou trabalhando em ambientes de missão crítica desde 2004. Iniciei minha jornada como Dev e acabei passando por diversos setores e cargos no decorrer da minha carreira, como: Operações de Infraestrutura, Segurança Ofensiva, DevOps e atualmente SRE. Conte comigo em sua jornada! Abraços.

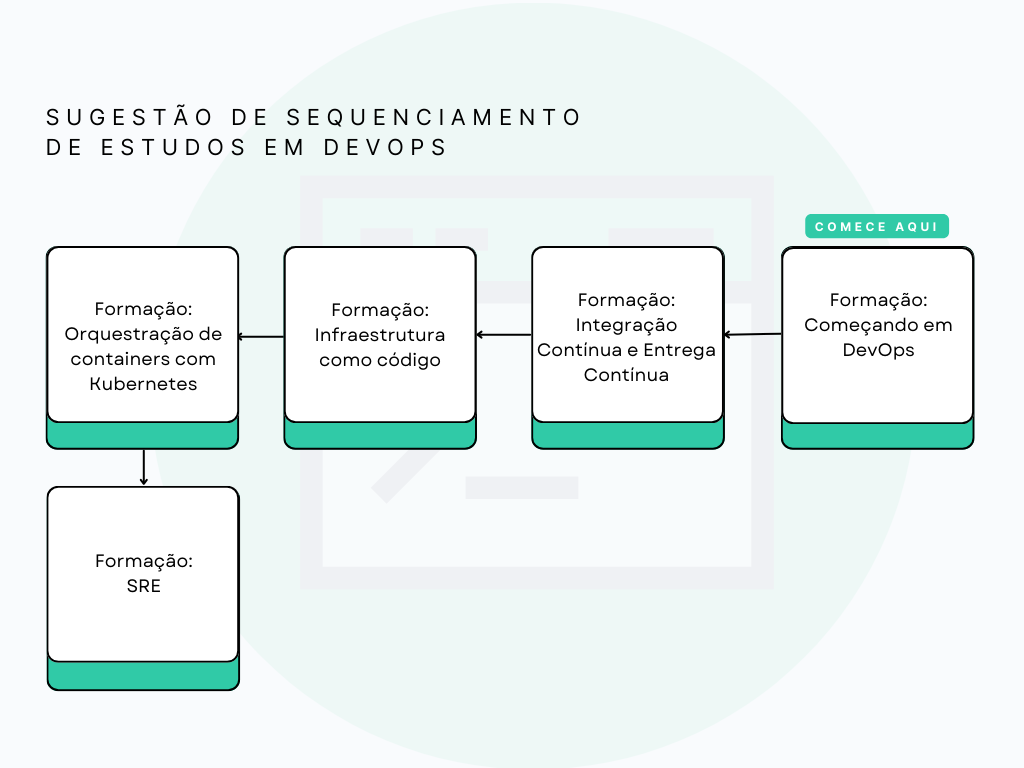 ---**
---**

