No meu sistema de cadastro de produtos, preciso criar uma funcionalidade que, a partir de um arquivo CSV com dados dos produtos, eu consigo ler esse arquivo e separar todos os produtos contido nele. Para representar um produto temos a seguinte classe:
class Produto(object):
def __init__(self, nome, valor):
self.__nome = nome
self.__valor = valor
@property
def nome(self):
return self.__nome
@nome.setter
def nome(self, nome):
self.__nome = nome
@property def valor(self):
return self.__valor
@valor.setter
def valor(self, valor):
self.__valor = valor
def __repr__(self):
return "nome:%s valor:%s" % (self.__nome, self.__valor)
Inicialmente temos o arquivo dados.csv com o seguinte conteúdo:
nome, valor camiseta, 25.0 jaqueta, 125.0 tenis, 80.0 bermuda, 40.0
Nesse meu sistema, irei ler esse arquivo a partir do diretório "arquivos/produtos/" portanto, criaremos a variável arquivo indicando o caminho e o nome do arquivo que leremos:
arquivo = 'arquivo/produtos/dados.csv'
Implementando a função de leitura do arquivo
Agora precisamos criar uma função que ficará responsável em ler esses produtos por meio da variável arquivo, portanto, criaremos a função ler_produtos() passando o arquivo como parâmetro:
def ler_produtos(arquivo):
arquivo = 'arquivo/produtos/dados.csv'
Primeiro, precisamos abrir o arquivo CSV, ou seja, utilizaremos a função open enviando a variável arquivo e utilizando parâmetro 'rb' que indica leitura:
def ler_produtos(arquivo):
arquivo_aberto = open(arquivo, 'rb')
No Python, para ler um arquivo CSV, podemos utilizar a função reader do módulo csv, porém, precisamos importar o módulo:
import csv
def ler_produtos(arquivo):
arquivo_aberto = open(arquivo, 'rb')
return csv.reader(arquivo_aberto,delimiter=',')
Observe que também adicionamos o parâmetro delimiter que já separa cada informação a partir de um critério, nesse caso, cada informação será separada no momento em que aparecer uma vírgula, e também, estamos retornando a função reader que é justamente o arquivo lido.
Então vamos realizar um teste, faremos a chamada para a função ler_produtos e devolveremos para a variável dados:
import csv
def ler_produtos(arquivo):
arquivo_aberto = open(arquivo, 'rb')
return csv.reader(arquivo_aberto,delimiter=',')
arquivo = 'arquivo/produtos/dados.csv'
dados = ler_produtos(arquivo)
Rodando o nosso código temos o seguinte resultado:
IOError: [Errno 2] No such file or directory: 'arquivo/produtos/dados.csv'

Verificando a existência do arquivo
Opa! Ele não conseguiu achar o meu arquivo! Por que será que isso aconteceu? Vejamos dentro do diretório onde está o meu projeto:
> ls dados.csv model.py verificando_diretorio.py
De fato não existe esse diretório, então o que devemos fazer? Antes mesmo de tentarmos pegar o arquivo, temos que verificar se ele pelo menos existe! Em outras palavras, precisamos primeiro verificar se o caminho que queremos encontrar existe, caso não exista, precisamos criá-lo!
Portanto, o nosso primeiro passo é separar a variável arquivo em duas, ou seja, a arquivo e caminho:
caminho = 'arquivo/produtos'
arquivo = caminho + '/dados.csv'
Em seguida, vamos criar a função verificar_arquivo, que será responsável em verificar se o diretório existe e o arquivo também, caso não exista, ela deverá criá-los! Então vamos criá-la:
import csv
def verificar_arquivo():
caminho = 'arquivo/produtos' arquivo = caminho + '/dados.csv'
def ler_produtos(arquivo):
arquivo_aberto = open(arquivo, 'rb')
return csv.reader(arquivo_aberto,delimiter=',')
dados = ler_produtos(arquivo)
Verificando a existência do diretório
Qual é o nosso próximo passo? É justamente verificar se o diretório não existe. Para isso, no Python, podemos utilizar o módulo os com funções capazes de realizar chamadas de sistema.
Nesse nosso primeiro caso, utilizaremos a função path.exists que verifica se existe um arquivo ou diretório com o parâmetro informado:
import csv import os
def verificar_arquivo():
caminho = 'arquivo/produtos'
arquivo = caminho + '/dados.csv'
if not os.path.exists(caminho):
Observe que estamos varificando se o diretório não existe, caso isso for verdade, o que devemos fazer? Precisamos criar o diretório! Mas como criamos um diretório no Python? Simples! No modulo os, temos também a função makedirs que cria diretórios:
def verificar_arquivo():
caminho = 'arquivo/produtos'
arquivo = caminho + '/dados.csv'
if not os.path.exists(caminho):
os.makedirs(caminho)
O nosso próximo passo é verificar a existência do arquivo dentro desse diretório. Podemos utilizar novamente a função path.exists do módulo os. Da mesma forma como fizemos com o diretório, caso não exista o arquivo, precisamos criá-lo.
Criando o arquivo
Para criar um arquivo, utilizaremos a função open passando o segundo parâmetro com o valor "w" que indica a criação para escrita:
def verificar_arquivo():
caminho = 'arquivo/produtos'
arquivo = caminho + '/dados.csv'
if not os.path.exists(caminho):
os.makedirs(caminho)
if not os.path.exists(arquivo):
open(arquivo, 'w')
Por fim, retornamos a variável arquivo para lermos na função ler_produtos:
def verificar_arquivo():
caminho = 'arquivo/produtos'
arquivo = caminho + '/dados.csv'
if not os.path.exists(caminho):
os.makedirs(caminho)
if not os.path.exists(arquivo):
open(arquivo, 'w')
return arquivo
Agora, basta apenas chamarmos a função verificar_arquivo devolvendo o seu resultado para a variável arquivo, e então, chamamos a função ler_produtos enviando a variável arquivo como parâmetro:
arquivo = verificar_arquivo() dados = ler_produtos(arquivo)
Exibindo as informações
Agora vamos imprimir os dados para verificar os valores, porém, ao invés de fazer um for de forma procedural, utilizaremos o recurso de compreensão de lista:
print [dado for dado in dados]
Executando o código temos o seguinte resultado:
[['nome', ' valor'],
['camiseta', ' 25.0'],
['jaqueta', ' 125.0'],
['tenis', ' 80.0'],
['bermuda', ' 40.0']]
Note que o primeiro valor ainda é o cabeçalho, isto é, linhas 'nome' e 'valor'. Para eliminarmos esse cabeçalho basta chamarmos a função next antes de iterar a variável dados:
next(dados) print [dado for dado in dados]
Por fim, basta apenas armazenarmos os valores em objetos do tipo Produto:
produtos = [Produto(dado[0], dado[1]) for dado in dados] print produtos
Rodando o código novamente, temos o seguinte resultado:
[nome:camiseta valor: 25.0,
nome:jaqueta valor: 125.0,
nome:tenis valor: 80.0,
nome:bermuda valor: 40.0]
Situações inesperadas
Observe que todos os dados foram lidos sem nenhum problema! Entretanto, se o caminho "arquivo/produtos" ao invés de ser um diretório, fosse um arquivo? O que será que aconteceria com o nosso código?
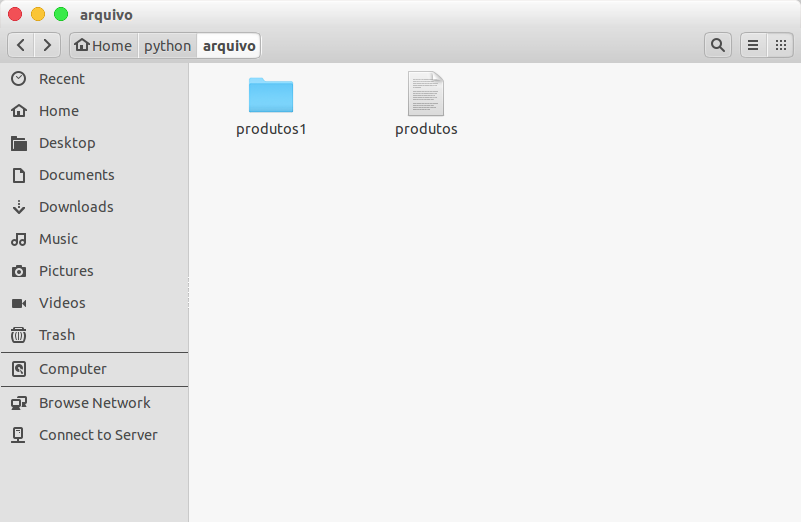
Vamos fazer uma simulação! Primeiro eu vou alterar o nome do diretório para "arquivo/produtos" para "arquivo/produtos1" e então, vou criar um arquivo chamado "produtos" dentro do diretório "arquivo":
Testando o nosso código, temos o seguinte resultado:
Traceback (most recent call last): File "/home/alex-felipe/python/dir.py", line 22, in <module> arquivo = verificar_arquivo()
File "/home/alex-felipe/python/dir.py", line 14, in verificar_arquivo open(arquivo, 'w') IOError: \[Errno 20\] Not a directory: 'arquivo/produtos/dados.csv'
Veja que ele tentou abrir o arquivo com a função open porém percebeu que o "arquivo/produtos" trata-se de um arquivo! Em outras palavras, permitimos que o nosso algoritmo seguisse adiante... Então o que devemos fazer?
Antes mesmo do nosso algoritmo tentar abrir o arquivo, precisamos garantir que o caminho é válido! Portanto, logo no momento que verificamos se não existe o caminho:
if not os.path.exists(caminho): os.makedirs(caminho)
Podemos adicionar uma elfi que será acionado caso exista um arquivo ou diretório de acordo com o caminho especificado, e então, vai verificar se o caminho não é um diretório:
if not os.path.exists(caminho): os.makedirs(caminho) elif not os.path.isdir(caminho):
Caso for verdade, ou seja, o caminho especificado não for um diretório, simplesmente lançamos um erro de IOError avisando que o caminho que estamos utilizando não é um diretório:
if not os.path.exists(caminho): os.makedirs(caminho) elif not os.path.isdir(caminho): raise IOError(caminho + " nao eh um diretorio!")
Agora, quando existir um arquivo ou diretório no caminho especificado e não for um diretório, automaticamente paramos o nosso algoritmo! Vejamos o resultado no teste:
Traceback (most recent call last): File "/home/alex-felipe/python/dir.py", line 22, in <module> arquivo = verificar_arquivo() File "/home/alex-felipe/python/dir.py", line 11, in verificar_arquivo raise IOError(caminho + " nao eh um diretorio!") IOError: arquivo/produtos nao eh um diretorio!
Veja que agora, mesmo em casos exceptionais como este, o nosso algoritmo consegue lidar e tomar as decisões necessárias.
Conclusão
Nesse post, vimos os problemas que podemos ter durante a leitura de arquivos dentro de diretórios, isto é, antes de tentarmos realizar a leitura de um arquivo precisamos sempre verificar se o caminho, nesse caso diretório, e o arquivo realmente existem, caso não, precisamos criá-los, caso sim, apenas lemos!
Gostou da dica? Então compartilhe conosco o que achou nos comentários :)
E que tal aprender a desenvolver com o Python hoje mesmo? Na Alura, temos a cursos de Python, onde você vai aprender desde o zero até uma aplicação web usando o Python.