O que é Pytorch?
Pytorch é uma biblioteca Python para computação científica. Inclusive é uma das mais utilizadas para pesquisa científica quando se trata de deep learning. O slogan deles é “Da pesquisa para produção”.
A Pytorch é capaz de realizar cálculos utilizando tensores. Tensores podem ser entendidos como vetores n-dimensionais. A vantagem dos tensores da Pytorch é que eles podem ser utilizados tanto em CPUs quanto em GPUs e isso acelera os processos computacionais relacionados ao deep learning.

Resolvendo um primeiro problema de machine learning
Para entender como a Pytorch é aplicada vamos resolver um problema de classificação em machine learning. A forma mais rápida de começar a utilizar esta biblioteca é através do Google Colab. Assim como outras bibliotecas de data science e machine learning a Pytorch vem instalada no Colab e basta realizar a sua importação no notebook.
O problema que vamos resolver envolve a classificação de sementes de trigo. A partir de informações como a área e o perímetro, o objetivo é estimar a espécie de uma semente. A versão original da base de dados pode ser baixada neste link e a versão modificada para este tutorial está neste link.
Subindo o arquivo sementes.csv para o Colab e visualizando suas primeiras linhas temos:
import pandas as pd
dados = pd.read_csv('sementes.csv')
dados.head()
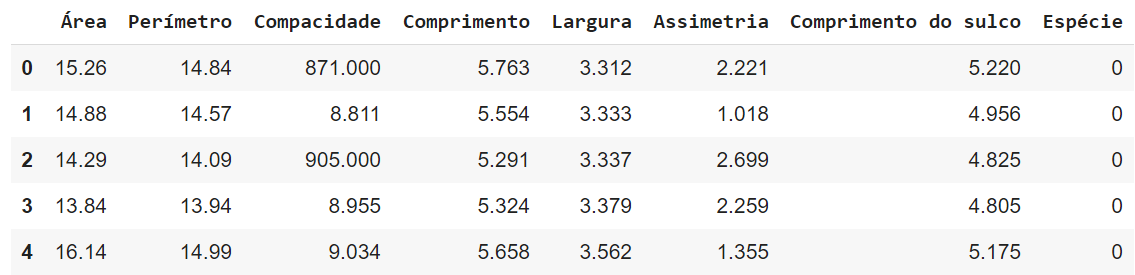
Essa tabela possui sete colunas com informações sobre a semente e uma coluna que identifica a espécie da semente. A semente pode ser da espécie 0, 1 ou 2.
O objetivo do nosso algoritmo de machine learning é aprender com essa tabela de dados. Assim, quando passarmos novos valores de Área, Perímetro, Compacidade e etc o algoritmo será capaz de retornar um valor de Espécie da semente. É comum chamarmos as colunas que contém as informações de entrada de X. Já a coluna que é nosso alvo de identificação chamamos de y. Podemos separar os dados em X e y através dos comandos:
X = dados.drop(['Espécie'],axis=1).values
y = dados['Espécie'].values
Em problemas supervisionados de machine learning nós precisamos construir um modelo que consiga generalizar um problema. Após o treinamento, um modelo adequado deve conseguir fazer boas estimativas tanto em dados que ele viu durante o treinamento quanto em dados que não viu durante o treino. Por este motivo, vamos separar a base de dados em duas partes. Uma parte para treino e outra para teste. O teste nós vamos guardar para depois, para verificar se o modelo retorna bons resultados.
Para dividir os dados em treino e teste vamos usar a biblioteca scikit-learn. Apesar deste ser um tutorial de Pytorch a forma como esse processo é feito com a scikit-learn é mais intuitivo.
from sklearn.model_selection import train_test_split
X_treino,X_teste,y_treino,y_teste = train_test_split(X,y,test_size=0.2)
Assim, temos 20% dos dados separados para o teste. Os outros 80% ficam para o treino. Essa porcentagem foi escolhida de forma arbitrária. Não existe uma regra muito bem definida para a escolha, mas normalmente é deixada uma porcentagem maior para o treino e menor para o teste. Agora finalmente podemos importar a biblioteca torch. Além disso, vamos transformar os arrays do numpy Xtreino,X_teste,y_treino,y_teste em tensores.
import torch
X_treino = torch.FloatTensor(X_treino)
X_teste = torch.FloatTensor(X_teste)
y_treino = torch.LongTensor(y_treino)
y_teste = torch.LongTensor(y_teste)
Com isto, podemos criar um modelo de rede neural. Por isso, vamos importar o módulo de redes neurais nn e o functional para que possamos chamar as funções de ativação.
import torch.nn as nn
import torch.nn.functional as F
A nossa rede neural possui sete entradas e três saídas. Essas são respectivamente as colunas de X e o número de classes possíveis que temos em y. Além disso, foram adicionadas duas camadas escondidas, uma com 14 neurônios e outra com 49 neurônios. O número de neurônios das camadas escondidas foi escolhido de forma arbitrária. Para criar a estrutura da rede definimos uma classe que dei o nome de Modelo. Dentro da classe modelo definimos o init que vai iniciar a estrutura da rede.
class Modelo(nn.Module):
def __init__(self,entrada=7,camada_escondida1=14,camada_escondida2=49,saida=3):
super().__init__()
self.fc1 = nn.Linear(entrada,camada_escondida1)
self.fc2 = nn.Linear(camada_escondida1, camada_escondida2)
self.out = nn.Linear(camada_escondida2, saida)
A seguir eu coloquei uma imagem de exemplo de uma rede neural com 7 entradas, 3 saídas e duas camadas escondidas cada uma com 14 neurônios. Nessa imagem, cada um dos círculos são os neurônios de uma camada. As linhas são definidas por pesos, valores que ligam cada neurônio através de uma multiplicação. As camadas escondidas são as camadas de neurônios intermediárias entre a primeira camada (entrada) e a última camada (saída).
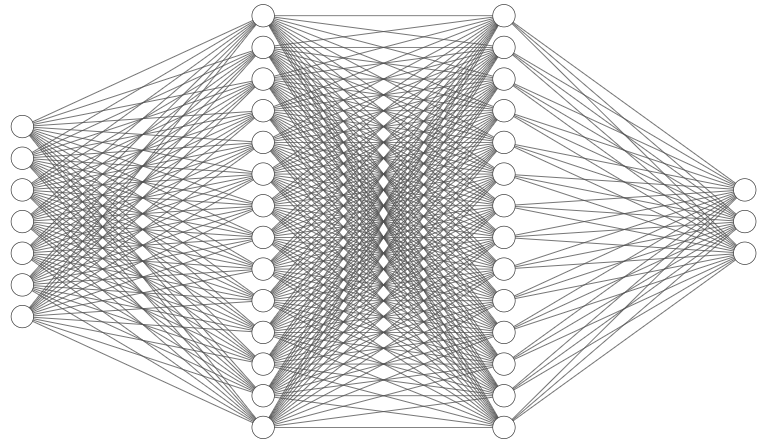
Ainda dentro da classe modelo definimos a função forward que será responsável pela propagação da rede. A propagação é o que leva a entrada até a saída. Cada uma das conexões de uma rede como a da figura de exemplo é ligada através de pesos e a saída de cada camada da rede é feita usando uma função de ativação. Aqui vamos utilizar a função de ativação ReLU que retorna sempre valores positivos. A nossa saída da rede é sempre positiva e por este motivo é conveniente utilizar a ReLU.
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.out(x)
return x
Precisamos instanciar a rede criada através do comando:
modelo_classificacao = Modelo()
Além de definir a rede neural, precisamos verificar se a rede está levando a entrada para um resultado próximo da saída desejada. Nós fazemos isso através de uma função objetivo ou função de custo:
funcao_objetivo = nn.CrossEntropyLoss()
Na primeira tentativa, a rede neural não irá obter uma saída satisfatória. Isso acontece porque os pesos que ligam cada um dos neurônios são definidos de forma aleatória. Por isso, precisamos fazer a correção desses pesos. O otimizador que será utilizado nesse processo é definido por:
otimizador = torch.optim.Adam(modelo_classificacao.parameters(), lr=0.01)
Finalmente vamos treinar a rede neural. O processo de propagação e retropropagação será repetido por 100 épocas. Assim, esperamos corrigir os pesos para obter uma rede que transforma corretamente a entrada em uma previsão da classe da semente.
epocas = 100
custos = []
for i in range(epocas):
y_predito = modelo_classificacao.forward(X_treino)
custo = funcao_objetivo(y_predito, y_treino)
custos.append(custo)
otimizador.zero_grad()
custo.backward()
otimizador.step()
Por fim, podemos tentar prever valores de y passando como entrada o X_teste. Assim temos como comparar o Y e o YHat que é o valor estimado. Aqui estão as dez primeiras linhas da minha tabela de resultado. A última coluna da tabela retorna 1 para estimativas corretas e zero para as incorretas.
preds = []
with torch.no_grad():
for val in X_teste:
y_predito = modelo_classificacao.forward(val)
preds.append(y_predito.argmax().item())
df = pd.DataFrame({'Y': y_teste, 'YHat': preds})
df['Correto'] = [1 if corr == pred else 0 for corr, pred in zip(df['Y'], df['YHat'])]
df
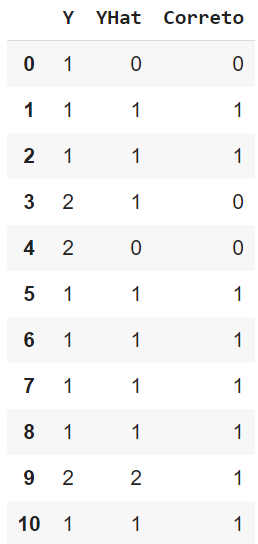
E aí? Os seus resultados foram melhores ou piores? Se ficou com alguma dúvida você pode acessar o código completo neste repositório.
Não deixe de conferir a nossa formação Deep Learning com Pytorch, para mergulhar de cabeça nesta área!
Para saber mais: Canal Peixe Babel
O canal Peixe Babel possui um quadro muito legal, o Programando em 10 minutos. Alguns dos vídeos desse quadro utilizam o Pytorch. Conferindo a playlist você conseguirá ver diferentes possibilidades de aplicação dessa ferramenta.