


Não interrompa seu teste A/B com significância estatística!

Você colocou o teste no ar e 10000 pessoas viram cada uma das versões. Na versão com botão verde 50 compraram de 5000 visitantes. N versão de botão roxo, 35 compraram de 5000 visitantes. Será mesmo que simplesmente mudar a cor do botão de comprar do seu ecommerce pode aumentar em 20% a sua taxa de conversão?
A calculadora do seu sistema de teste A/B afirma que sim. Mas é isso mesmo mesmo? O que quer dizer o "botão verde ganha do botão roxo com 95% de probabilidade"?
O sistema está falando que há apenas 5% de chance de, na verdade, A e B não terem diferença significativa estatisticamente. Em apenas 5% de testes aleatórios com A e B poderia aparecer tal situação de indicar erroneamente que o botão verde ganha do roxo. Os estatísticos chamam essa probabilidade de p-value e, quando ela é bem pequena, normalmente menor que 5%, dizemos que o teste tem significância estatística.

Bem, será que temos azar e caímos nesses 5% do p-value? Isso é, na verdade é apenas o acaso que está indicando que o botão roxo é melhor que o botão verde? Imagine que rodemos um teste e, depois de alguns dias, esse seja o resultado, atingindo o 95% desejado exatamente no dia 4 de dezembro:
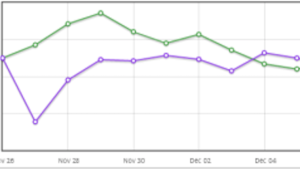
Deixamos até rodar o teste um pouco mais, para ver se continuava assim. E continuou! No dia 5 de dezembro o botão roxo continuava ganhando e mais: disse que com 96% de certeza. Incrível não? E aí, já podemos parar?
Continuando mais, olhe só o resultado:
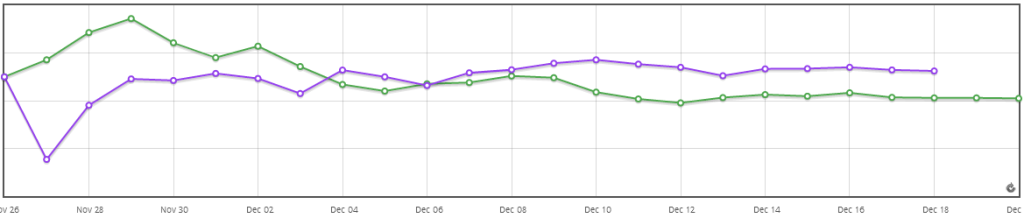
Agora o botão verde está na frente, e com 95% de certeza! Wow! Quase tomamos a decisão errada alguns dias atrás. Opa, será? E se deixarmos rodando mais e mais... será que muda de novo?
O problema com o método ingênuo de usar o p-value como um critério de parada é que o teste que te fornece a esse p-value assume que você criou o experimento com uma amostra e com um efeito em mente. Se você monitora continuamente o teste e o p-value resultante, aumenta a probabilidade de você enxergar um efeito que não existe!
É como se você estivesse rodando inúmeros testes de hipótese seguidos! Não sou estatístico, mas não sou eu quem está fazendo o alerta. O parágrafo acima eu traduzi diretamente do blog do pessoal do Airbnb. E não são só eles que falam isso, mas também os estatísticos, como o Evan Miller, nesse conhecido post. São também as próprias ferramentas de teste a/b, como a VWO faz ao listar os top 7 problemas em testes A/B (adivinhe qual é o primeiro), de onde tirei os gráficos acima.
Sim, eu sei, diversas ferramentas sugerem que você poderia terminar o experimento logo que atingisse a significância estatística. E elas fazem isso de maneira errada.
A imagem a seguir é de um experimento do Airbnb é extremamente ilustrativa:
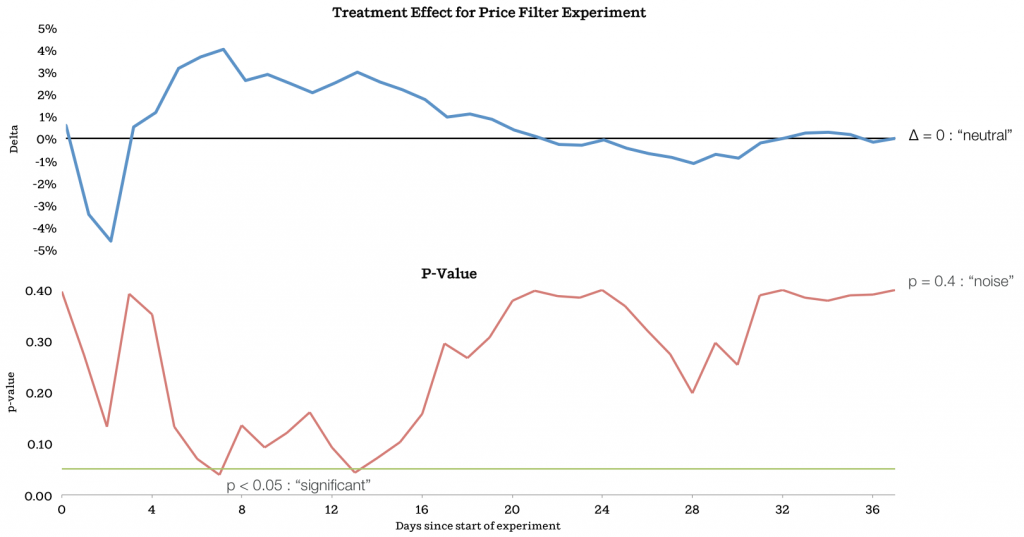
Se eles tivessem parado o experimento quando o p-value tivesse batido o nível de significância desejado, teriam comido bola! No final, o teste não tem significância, como é a maioria dos casos dos nossos testes.
A conclusão é simples: defina o tamanho da sua amostra antes de começar o seu teste A/B e pare somente quando atingir esse número. E não, não é legal afirmar que a cor do botão de 'comprar' aumenta a conversão de 35 em 5000 para 50 em 5000! Você precisaria de mais de 35 mil visitantes para poder ter uma amostra de tamanho ideal e detectar 20% ou mais de variação na conversão.
Como eu sei disso? Como definir o tamanho da amostra? Peça novamente ajuda aos estatísticos e inpute os seus dados em ferramentas como essa:
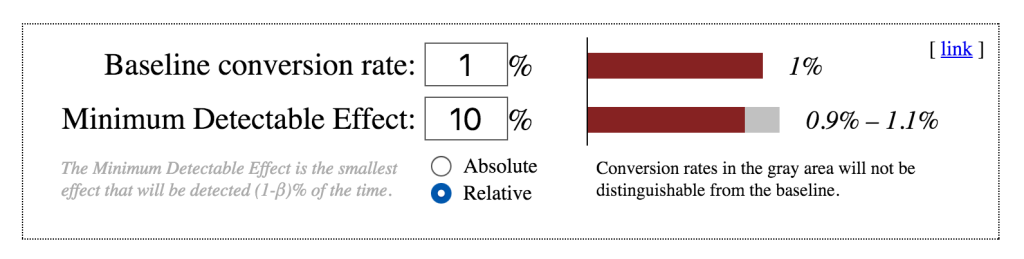
Se o seu ecommerce tem 1% de taxa de conversão e você quer saber se uma hipótese mexe esse número para mais de 1,1% ou menos de 0,9% com um p-value de 5%, vai precisar de incríveis 157 mil visitantes. Há muitos outros detalhes importantes além do p-value e, caso você não compreenda tudo, fique tranquilo: mesmo alguns cientistas não usam essas informações corretamente.
A maioria dos nossos testes e ideias malucas são isso mesmo: testes. É normal uma grande quantidade dos testes A/B não ter efeito algum no comportamento do usuário. Não desista e nem queira forçar o contrário: vai acabar encontrando significância onde não há. É difícil conseguir. Basta ver como a sua taxa de conversão varia abruptamente entre dias da semana ou mesmo entre meses, mesmo sem fazer mudança alguma!
Quem conhece profundamente estatística, o que não é o meu caso, pode se aventurar em tomar decisões mais rapidamente, como o próprio post do Airbnb sugere em heurísticas. Infelizmente o erro que fazemos é muito, muito mais básico. Como regra para nós mortais, defina o tamanho da amostra!
Há ainda diversos detalhes sobre testes A/B que são ainda mais complicados. Diferente de um teste de hipótese de indústria farmaceutica, você não está realizando testes em locais fechados e controlados com um público bem definido. A internet é um ambiente hostil. Se o seu teste, por exemplo, terminar em menos de uma semana, talvez você não tenha testado com o público seu que visita de fim de semana, e ele se comporta de maneira diferente que os outros. Ou talvez o ciclo de compra do seu usuário seja maior que 2 ou 3 dias, e você esteja enxergando uma informação quebrada, por mais que a amostragem tenha sido atingida.





