A Garbage Collector (ou coletor de lixo) é um mecanismo que gerencia a memória e, automaticamente, libera o espaço que não está sendo utilizado.
Se você já programou em Java, deve se lembrar de que essa linguagem é totalmente orientada a objetos.
Ou seja, para tudo que quisermos representar, devemos criar classes e objetos.
Autor(a)
Iasmin Araújo
Curso graduação em Ciência da Computação na UFMG. Sou instrutora da Escola de Programação e aqui no fórum estarei principalmente nos tópicos de Java.
Inscreva-se em nossa Newsletter
Fique por dentro de conteúdos, insights e oportunidades do universo tech. Receba novidades e lançamentos direto no seu e-mail.
O objeto tem um “ciclo de vida”: ele é instanciado, utilizado no programa e depois fica inutilizado, estando “morto”.
Neste momento, dizemos que os dados que esse objeto guardava viraram lixo de memória. Mas o que acontece com esse lixo?
Neste artigo, iremos conhecer o Garbage Collector, que é o processo responsável por coletar esse lixo formado pelos objetos e as diferentes formas de realizar esse processo.
O que é Garbage Collector?
A Garbage Collector (ou coletor de lixo) é um mecanismo que gerencia a memória e, automaticamente, libera o espaço que não está sendo utilizado.
a pilha ou stack, onde ficam empilhados os métodos e todas as variáveis locais deles. Dentre as variáveis locais, há as primitivas, que são aquelas com tipos básicos, como int, char e float, e as referências, que são variáveis que guardam os endereços dos objetos, que estão na heap.
a heap, que é uma região de memória onde os objetos ficam “amontoados”, ou seja, sem nenhuma organização específica. Eles são criados e vão para o espaço de memória que está disponível naquele momento.
Em algum momento da execução do programa, um objeto não será mais apontado por nenhuma referência, se tornando um lixo de memória.
Precisamos, então, limpar a memória, fazendo a garbage collection, ou coleta de lixo. Mas como fazer isso?
Como funciona o Garbage Collector?
A notícia boa é que nós não precisamos fazer nada! O Garbage Collector tem exatamente essa função: trabalhar na heap e identificar objetos que não são mais usados e liberar a memória que eles ocupavam.
Características do Garbage Collector:
Completamente autônomo: o gerenciamento de memória é automático
Não precisa acioná-lo
Como funciona a coleta de lixo:
Identificação dos objetos que não são mais referenciados pelo programa (ou seja, que não são mais usados)
Liberação da memória
Compactação: em alguns casos, ele compacta a memória para não fragmentá-la
Quais os benefícios do Garbage Collector?
Os benefícios do Garbage Collector são:
Evitar vazamento de memória
Melhorar a eficiência e velocidade do programa
Simplificar o desenvolvimento e reduzir chances de erros.
Os algoritmos de coleta de lixo em Java
Agora que você já sabe o que é e como funciona o Garbage Collector, vamos nos aprofundar em seus algoritmos.
Mark and Sweep
Um dos algoritmos de coleta de lixo mais antigos é o Mark and Sweep, utilizado nas versões 1.0 a 1.2 do Java.
Em tradução literal, essa expressão significa marcar e varrer, e é exatamente isso que ocorre nesse tipo de coleta de lixo.
O garbage collector percorre a memória duas vezes. Na primeira, ele marca todos os objetos que estão sendo utilizados na aplicação.
E na segunda, ele varre os objetos que não foram marcados, liberando a memória para ser utilizada novamente.
Esse algoritmo é bastante simples de compreender e de implementar.
No entanto, nos momentos em que o GC (garbage collector) percorre a memória, ele gera um stop-the-world, parando a execução da aplicação.
Esse é um dos motivos pelos quais o Java era entendido como uma linguagem lenta em suas versões antigas.
Ao longo do tempo, analisando a performance das aplicações, percebeu-se que grande parte dos objetos criados têm vida curta, e apenas uma pequena parcela “sobrevive” por muito tempo.
Essa ficou conhecida como hipótese das gerações e foi daí que começaram a surgir os primeiros algoritmos de general copying, em português “cópia geracional”.
Na cópia geracional, separamos a memória em pelo menos duas gerações: uma jovem e uma velha. Essa divisão é desigual: a geração jovem ocupa menos espaço que a geração velha.
A ideia geral é utilizar minor collects(coletas menores) e major collects (coletas maiores).
A minor collect é quando o GC percorre apenas a geração jovem e copia os objetos que sobrevivem à coleta para a geração mais velha. Já a major collect - ou Full GC - é quando o GC percorre a memória toda, como no Mark and Sweep. As minor collects devem ser bem mais frequentes que as major collects.
Iremos conhecer detalhes de implementação dos algoritmos com cópia geracional a seguir.
Serial Garbage Collector
O primeiro algoritmo de garbage collection que utiliza a cópia geracional é o Serial Garbage Collector.
Ele surgiu na versão 3 (ou 1.3) do Java, sendo utilizado como padrão nas versões 3 e 4.
No Serial GC, a heap é dividida em 3 gerações: young, old e permanent.
Ele utiliza a ideia geral da cópia geracional, e aqui todas as coletas, sejam elas major ou minor, são feitas em sequência, em uma única thread.
Quando o GC está executando, todas as threads da aplicação devem parar de executar.
Nesse algoritmo, embora já tenhamos evoluído com relação ao Mark and Sweep, ainda há o problema de precisar “parar o mundo” muitas vezes, o que afeta a performance das aplicações.
Além disso, para computadores com muitos processadores - que é o caso da maior parte dos computadores atualmente -, há certo desperdício de recursos: as coletas poderiam ocorrer em paralelo, por exemplo.
Parallel Garbage Collector
O Parallel Garbage Collector vem para resolver o desperdício de recursos do Serial GC, citado anteriormente.
Ele surgiu na versão 4 do Java e foi utilizado como padrão nas versões 5 a 8.
O algoritmo é bem parecido com o Serial, mas com a diferença de que etapas da coleta de lixo são feitas paralelamente: major e minor collects são executadas em diferentes threads, diminuindo o tempo de stop-the world em máquinas com vários processadores.
Repare que, ainda assim, existe um tempo em que precisamos parar a execução da aplicação para fazer a coleta de lixo. Não estamos na performance ideal ainda.
Além disso, temos um outro problema: como as coletas são feitas de forma paralela, a memória pode ficar fragmentada, com “buracos” no meio de regiões com objetos. Isso porque uma coleta passa por uma região e libera um pequeno espaço de memória.
Enquanto isso, ocorre outra coleta, que faz a mesma coisa. Assim, com essa junção de pequenos espaços, a memória se fragmenta, e fica impossível alocar objetos grandes nesses espaços.
Quanto mais threads forem utilizadas para a coleta, maior a chance de fragmentação.
Concurrent Mark Sweep
O Concurrent Mark and Sweep também é um GC com cópia geracional, e ele surge para trazer uma solução ainda melhor para o stop-the-world.
Agora, tanto as etapas de coleta de lixo quanto a execução do programa são realizadas paralelamente.
No caso das coletas menores, elas são realizadas de forma semelhante ao que ocorre no Parallel GC. Já para as coletas maiores, a CMS tem várias fases:
Initial Mark Pause (Pausa de Marcação Inicial): no início, é necessário parar a execução da aplicação para que o GC marque os objetos que são diretamente acessíveis pelas raízes, que são aqueles que têm referências diretas na aplicação.
Concurrent Mark (Marcação Concorrente): agora, de forma concorrente, o GC faz a marcação dos objetos que são atingíveis pelas raízes, ou seja, objetos que podemos alcançar de forma indireta através das referências do programa em execução.
Concurrent Preclean (Pré-limpeza): outra fase realizada concorrentemente. Ela é responsável por preparar a memória para a fase de remarcação, identificando objetos que podem ter suas referências atualizadas. Essa fase pode ser abortada, caso haja a necessidade de realizar outras tarefas mais importantes, como uma coleta menor.
Remark Pause (Pausa de Remarcação): nessa fase, paramos novamente a execução da aplicação para remarcar objetos que se tornaram inacessíveis desde a primeira marcação.
Concurrent Sweep (Varredura Concorrente): essa fase volta a executar de forma concorrente com a aplicação, e libera os objetos que foram marcados como lixo nas fases anteriores.
Concurrent Reset (Reset Concorrente): quando o GC reinicia para a próxima coleta maior. Essa fase também é concorrente.
Podemos observar que grande parte das tarefas da coleta de lixo são feitas concorrentemente à aplicação, fazendo com que se ganhe bastante tempo. No entanto, ainda há problemas.
Pode ser que, enquanto ocorre uma coleta menor concorrente, a geração antiga fique cheia ou fragmentada.
Com isso, o GC precisa ter pausas imprevisíveis para realizar uma coleta maior.
Essas pausas imprevisíveis podem ser bastante longas, atrapalhando consideravelmente o desempenho da aplicação.
Dessa forma, compreendeu-se que, por mais que explorasse bastante a concorrência, esse GC não era o ideal.
O CMS surgiu na versão 5 do Java como uma opção experimental, e, por esse motivo, não chegou a se tornar um coletor padrão, sendo descontinuado e substituído pelo algoritmo a seguir.
Garbage First (G1)
Para equilibrar o problema das pausas imprevisíveis que ocorriam com a concorrência no CMS, surgiu o algoritmo do G1 (ou Garbage First). Ele também é um coletor de cópia geracional, tendo sido criado na versão 7 do Java.
Porém, aqui a memória é dividida em várias regiões, todas elas com o mesmo tamanho.
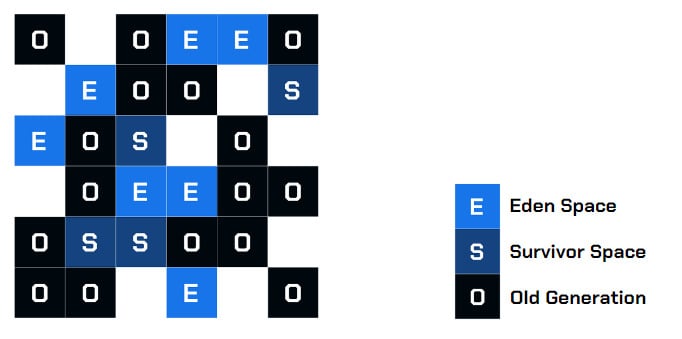
Cada região pode ser alocada para alguma das gerações existentes. Há as gerações jovens, que são representadas pelas regiões do Éden e Survivor, e a geração com regiões Old (ou antiga). Repare que no G1, a região Permanent foi abolida. Com isso, a memória dividida fica bem parecida com a figura abaixo.
O G1 tem duas fases, cada uma com seus processos:
Fase 1 - Young-only phase (Apenas jovem): são feitas várias coletas menores tradicionais (da mesma forma que as do Parallel GC). Ao decorrer dessas coletas, objetos são promovidos à geração old. Em algum momento, a ocupação da geração antiga atinge um certo limite, que é o limite de ocupação inicial da heap. Assim, será preciso recuperar o espaço de alguma forma, evitando a fragmentação ou ocupação total da memória.
Há uma fase específica para realizar a recuperação de espaço. Porém, para chegar nela, o G1 tem passos intermediários: concurrent start, remark e cleanup.
Start Concurrent (Início Concorrente): o início concorrente se refere a uma coleta menor tradicional com um processo adicional. Além dos processos normais, ela também inicia um processo de marcação dos objetos de forma concorrente.
A marcação concorrente determina todos os objetos alcançáveis (vivos) nas regiões da geração old que serão mantidos para a próxima fase. A marcação é finalizada com duas pausas especiais, que param a execução da aplicação: Remark e Cleanup.
Remark (remarcação): nesta etapa, temos uma pausa para finalizar a marcação em si, realizar o processamento global de referências e o descarregamento de classes, recuperar regiões completamente vazias e limpar estruturas de dados internas. Entre as fases Remark e Cleanup, o G1 calcula informações para depois poder recuperar espaço livre em regiões selecionadas da geração antiga de forma concorrente, o que será finalizado na pausa Cleanup.
Cleanup: essa é a pausa final, que determina se realmente irá haver uma fase de recuperação de espaço. Caso vá haver, a fase apenas jovem é concluída.
Fase 2 - Space-reclamation phase (Fase de recuperação de espaço): nesta fase, são feitas várias coletas mistas que, além de regiões de geração jovem, também trabalham em regiões de geração antiga. Nessas coletas, é feito o processo de evacuação, em que objetos vivos são transferidos de uma região para outra, garantindo que as regiões sejam preenchidas com objetos ativos. A fase de recuperação de espaço termina quando o G1 determina que liberar mais regiões de geração antiga não resultaria em espaço livre que valesse o esforço.
Terminada a recuperação de espaço, o G1 reinicia, voltando para a fase “Apenas Jovem”.
Dessa forma, o G1 soluciona o problema das pausas imprevisíveis do CMS. Aqui, as pausas ocorrem raramente, somente quando a geração Old está devidamente cheia e precisa de mais espaço. Assim, ganhamos bastante eficiência, sem causar danos nas aplicações.
O G1 representou uma evolução tão grande para o Java que, a partir da versão 9, ele passou a ser o GC padrão, e segue nesse posto até a versão 22 (mais recente neste momento).
Ainda assim, ele tem alguns momentos de pausa, e outros algoritmos vêm sendo propostos para diminuir ainda mais tais momentos.
Z Garbage Collector (ZGC)
O ZGC é um garbage collector projetado para grandes heaps, que variem de alguns gigas a terabytes, e é recomendado para aplicações que exijam baixa latência (tempo de resposta ao usuário).
Ele surgiu na versão 11 do Java, e segue como um coletor experimental até as versões atuais.
Como o G1, o ZGC também divide a memória em regiões de tamanho igual. O seu diferencial está no foco em manter os tempos de pausa previsíveis e mínimos.
Todo o trabalho caro das coletas de lixo é feito de forma concorrente à aplicação, com a meta de que as threads em execução não parem por mais de 10 ms.
Repare que o ZGC foca em uma necessidade específica: heaps consideravelmente grandes e aplicações que exijam baixa latência.
Em outros casos, quando não há esse tipo de necessidade, o G1 já atende muito bem às expectativas, com pausas mínimas.
Shenandoah
O Shenandoah também é um GC mais recente, focado em diminuir ainda mais os tempos de pausa da aplicação. Ele surgiu também como um coletor experimental, na versão 12 do Java.
Para reduzir ainda mais os tempos parados, o Shenandoah tenta fazer grande parte dos processos concorrentemente, de forma ainda mais intensa do que o ZGC.
Ele também divide a memória em regiões iguais. Porém, essas regiões não têm gerações.
As fases de coleta, então, são realizadas concorrentemente à execução e, além disso, a cada coleta os objetos precisam ser marcados ou não como vivos.
Assim, as fases de coleta utilizam vários algoritmos específicos para garantir que não haja nenhum problema em meio a esses processos. Isso pode gerar uma certa sobrecarga à CPU.
Por isso, deve-se ponderar nos momentos de escolher esse garbage collector. Embora ele seja bastante eficiente e tenha pausas muito curtas, pode ser que o G1 também atenda às expectativas tranquilamente, sem sobrecarregar o sistema.
Conclusão
Compreender os algoritmos de coleta de lixo nos traz duas lições importantes. A primeira é que podemos entender como a engenharia de software atua para construir algoritmos cada vez mais eficientes, que resolvam problemas.
A segunda lição é que conseguimos ver o quão complexo é lidar com os objetos por baixo dos panos, controlando o tempo e a memória ao mesmo tempo.
Entendendo as ideias de cada algoritmo, estamos preparados para controlar a memória das nossas aplicações, focando na memória e no desempenho cada vez mais otimizados.