Desenvolvedora JavaScript com background multidisciplinar, sempre aprendendo para ensinar e vice-versa. Acredito no potencial do conhecimento como agente de mudança pessoal e social. Atuo como instrutora na Escola de Programação da Alura e, fora da tela preta, me dedico ao Kung Fu e a nerdices em geral.
Inscreva-se em nossa Newsletter
Fique por dentro de conteúdos, insights e oportunidades do universo tech. Receba novidades e lançamentos direto no seu e-mail.
Quando decidimos aprender uma nova linguagem, normalmente iniciamos o percurso da nossa aprendizagem pelos blocos fundamentais: entender o funcionamento básico de variáveis, como funciona a tipagem, a declaração de funções e como trabalhar com estruturas de dados básicas (por exemplo, arrays).
Tudo isso já parece ser bastante coisa, não é? Mas não para por aí.
Após este primeiro momento, é hora de investir nas particularidades da linguagem: paradigmas, principais bibliotecas e APIs, detalhes de implementação e de que forma os programas escritos nessa linguagem são executados.
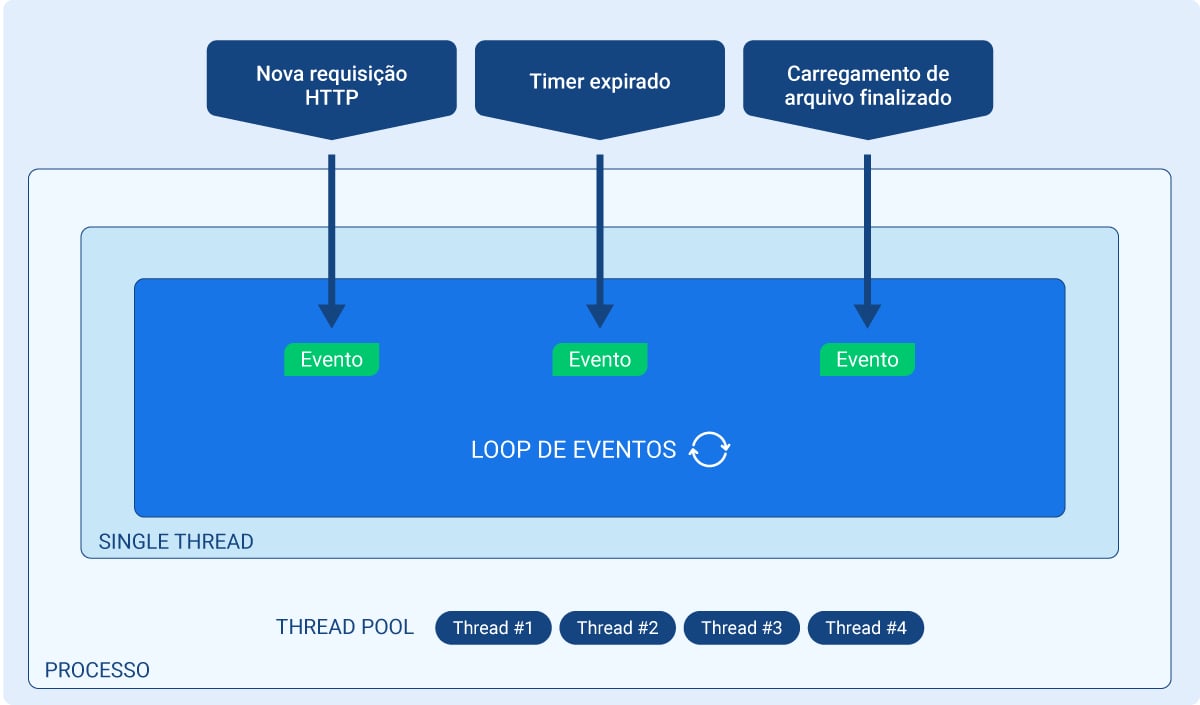
No caso do JavaScript, desde o início temos contato com as duas principais ferramentas usadas para executar programas, o navegador e o Node.JS.
O que é o Node.js? Explicamos um pouco sobre o que é e para que serve neste Alura+.
Assim, neste artigo, vamos mergulhar em um ponto importante para entendermos mais a fundo o funcionamento do Node.js: sua arquitetura baseada em eventos e as ferramentas que trabalham em conjunto com o Node.js para garantir a execução do código.
Por que é importante entender o loop de eventos?
Uma vez que sabemos como o loop funciona e como as partes de um programa são processadas, é possível entender melhor alguns bugs relativamente comuns no Node.js, como funções que são executadas e/ou retornam fora da ordem esperada.
Eventos e arquitetura baseada em eventos
Antes de falarmos sobre o tal loop de eventos em si, precisamos definir o que é um evento no contexto do JavaScript.
Podemos pensar em evento primeiro no sentido mais literal: um acontecimento, algo que ocorre em determinado momento. No navegador, os eventos estão muitas vezes relacionados a ações do usuário, como por exemplo um clique em um botão, preenchimento de um input ou qualquer outro tipo de interação; são eventos disparados por elementos HTML, por objetos globais do navegador como window e etc. Você pode conferir uma lista destes eventos para entender melhor.
Falando especificamente sobre o Node.js, podemos pensar em eventos em contextos como leitura e escrita de arquivos, manejo de requisições HTTP e funções timer como setTimeout() (falaremos mais sobre timers neste artigo). Estes processos emitem eventos quando o processamento é finalizado; algo como um “aviso” para o programa que o processamento foi concluído e o resultado (retorno) pode ser utilizado.
Estes eventos são passados para o event loop, que vai chamar as funções callback que estão associadas a cada um destes eventos. Um exemplo de função callback nesta estrutura é a função que executa o console.log() no exemplo abaixo:
setTimeout(() => {
console.log('Aguardar pelo menos 1 segundo');
}, 1000)
A arquitetura baseada em eventos trabalha com duas partes principais: os event emitters e os event listeners (emissores de eventos e “ouvidores” de eventos, em tradução livre).
Event emitters eEvent Listeners
No Node.js, objetos podem ter métodos como instâncias de EventEmitter, que emitem eventos em situações determinadas, normalmente quando acontece algo no programa (por exemplo, uma requisição HTTP). Estes eventos, uma vez emitidos, são “escutados” por event listeners, que por sua vez disparam funções callback relacionadas a cada listener.
Para exemplificar, vamos conferir o código abaixo:
No exemplo acima, um servidor (server) é criado a partir do método http.createServer(). Esse servidor é uma instância de um eventListener (algo como “ouvidor” ou “ouvinte” de eventos) e por isso ele possui o método on(). Ao chamarmos esse método, estamos registrando para esse “ouvinte” que ele deve ouvir eventos no programa que correspondam à string request, nosso primeiro argumento. Se o método detectar algum evento com esse nome, deve executar a função que passamos como segundo parâmetro.
Pense que o método on() é uma função que nos ajuda a configurar quais eventos nosso server terá que ficar atento e o que ele deve fazer ao ouvir um destes eventos. Então a partir do momento em que criarmos o servidor e chamamos o método on, ele estará “ouvindo” os eventos nomeados como request e saberá o que fazer ao ouvir um desses eventos; no caso, executar a função callback que foi passada como o segundo argumento.
A partir do conceito de eventos, podemos falar sobre como cada evento de um programa é executado.
Os componentes do Node.js, threads e processos
Antes de nos aprofundarmos na questão do loop de eventos e como ele funciona, existem três pontos importantes para abordarmos: quais são as partes que compõem o Node.js, o que são threads, o que são processos e como o Node.js trabalha com isso.
Para focarmos aqui no tema principal, separamos estes assuntos em outros três artigos. Você pode conferir cada um separadamente, caso precise ter mais informações sobre esses temas:
Quais são os componentes do Node.js? É normal entendermos o Node.js como sendo uma ferramenta “única”, que faz sozinha todas as partes de interpretação do JavaScript e do processamento dos dados. Porém, por baixo dos panos, o Node.js é composto por diversas bibliotecas diferentes! Este artigo expõe cada uma delas e dá um resumo sobre suas responsabilidades;
O que precisamos saber sobre threads e processos? É através das threads e dos processos que as tarefas de um programa - seja qual for a linguagem - são processadas pelo computador. É um tema muito vasto e que envolve arquitetura de computadores, mas nesse artigo damos a introdução necessária para entender como threads e processos estão ligados à forma como o Node.js funciona;
O Node.js é single-threaded? Nesse artigo entramos um pouco mais na questão das threads e como isso influencia na forma como nossos programas são executados pelo Node.js.
Agora podemos conversar sobre o tal loop de eventos!
O centro da arquitetura do Node.js: o loop de eventos
Agora que temos os conceitos necessários: threads, eventos e os componentes do Node.js, podemos nos aprofundar em entender como funciona o loop de eventos.
Confira abaixo este programa escrito em JavaScript:
Vamos entender melhor o que esse esquema representa?
Call stack
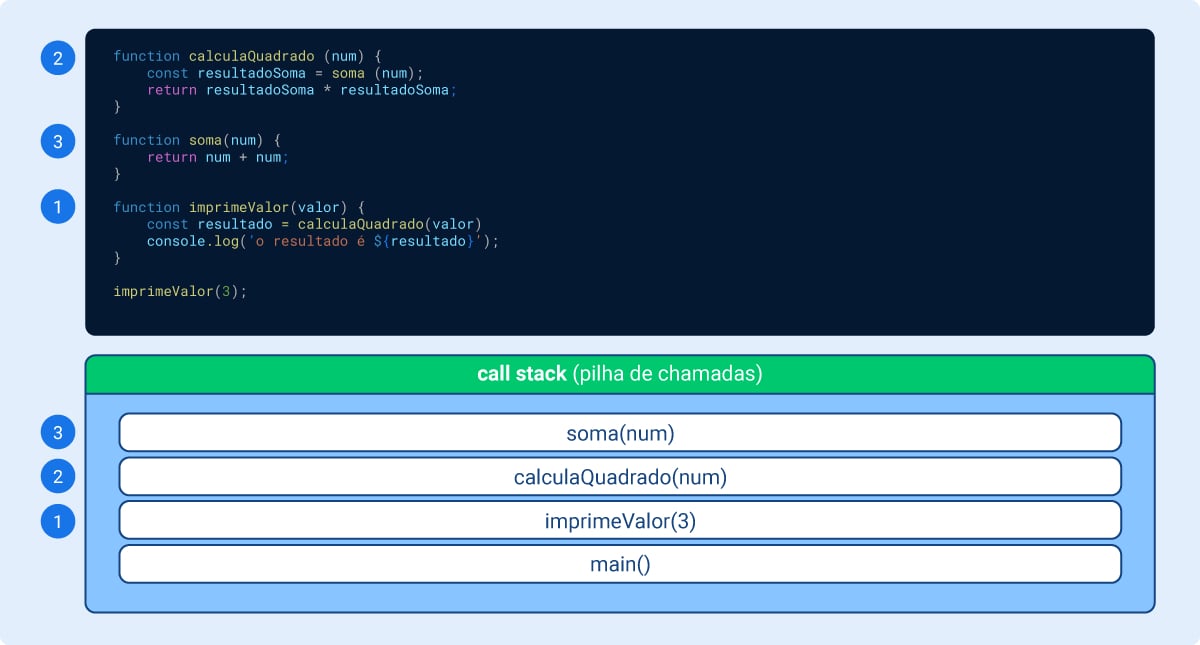
Na parte direita da figura temos uma estrutura chamada “pilha de chamadas”. Comparando a pilha de chamadas com o código, percebemos que ela reflete a ordem em que as funções do programa são chamadas (ou executadas). O que temos aqui é justamente uma estrutura de dados do tipo “pilha” ou stack, e a característica principal desta estrutura é o conceito de LIFO, ou last in, first out; ou seja, o último item colocado na pilha é o primeiro a sair.
A call stack, no caso do Node.js, é parte do motor V8; pode-se dizer que é a estrutura que o V8 usa para monitorar as chamadas de funções feitas por um programa. Sempre que chamamos uma função ela é enviada para a call stack.
Call stack existe em qualquer linguagem de programação, seguindo basicamente o mesmo conceito de “pilha de chamadas” - basta lembrar do famoso stack overflow ou “transbordamento de pilha”, erro que acontece quando as chamadas de função vão se “empilhando” na call stack até que ultrapassa a memória disponível e que dá nome ao famoso fórum de perguntas e respostas de programação.
O Node.js trabalha apenas com uma thread de execução, o que significa que temos apenas uma call stack, que serve para registrar em que ponto o programa se encontra em dado momento e a ordem de execução do código. Então, quando o programa chama uma função ela entra na pilha, e quando a função retorna ela sai do topo da pilha, e assim sucessivamente até que a pilha se esvazie.
Abaixo, a sequência de chamadas de função e a forma como elas são adicionadas à pilha e retiradas após o retorno/finalização da função.
Vamos modificar nosso modelo para acrescentar os outros elementos envolvidos no processamento deste programa.
Task queue
Vamos conferir este novo trecho de código:
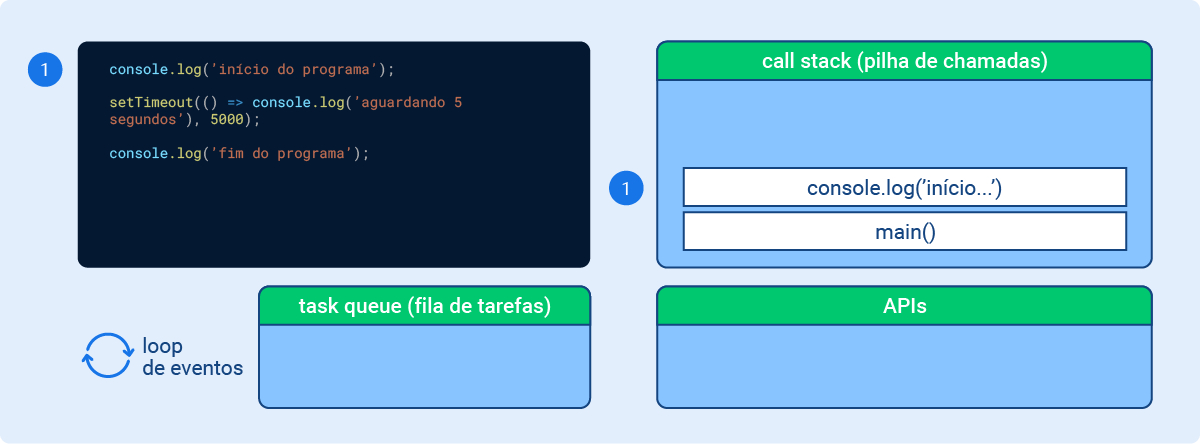
console.log('início do programa');
setTimeout(() =>console.log('aguardando 5 segundos'), 5000);
console.log('fim do programa');
Executando o código, temos:
Momento 1:main() inicia a stack, console.log(início do programa) entra na stack, executa e sai (é síncrono);
Imagem 2 - Node.js por baixo dos panos: Momento 1
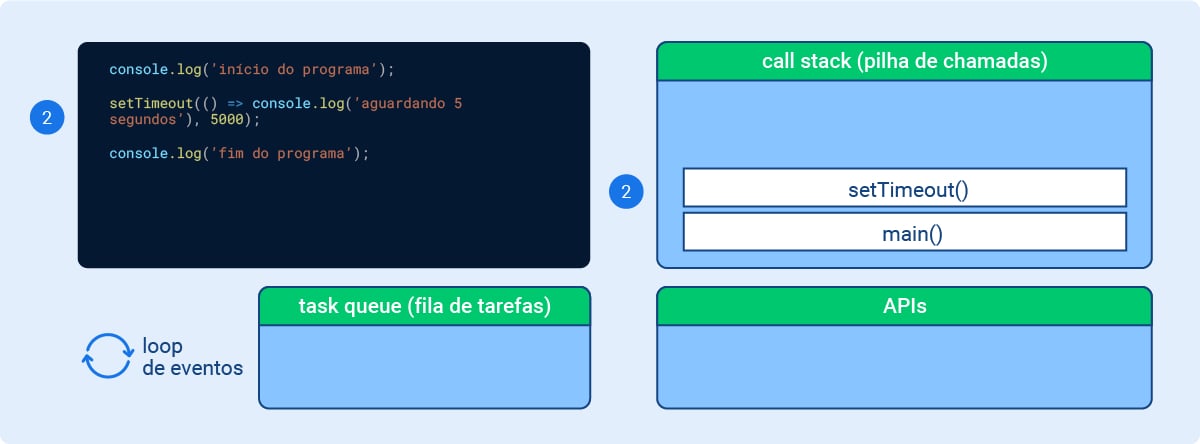
Momento 2: Descobriremos agora o que acontece quando é executado uma função do tipo timer como setTimeout(). Esse tipo de função recebe como parâmetro uma função callback que será chamada de volta (called back) para ser executada a partir de um determinado evento - no caso, a finalização da contagem de 5 segundos (5000 milissegundos).
Vamos conferir como fica este processo em nosso diagrama, a seguir:
Imagem 3 - Node.js por baixo dos panos: Momento 2
console.log('aguardando 5 segundos'), 5000); Está associado a função setTimeout()">
Momento 3: o callback do setTimeout é colocado na fila de timers (vamos ver mais sobre timers em seguida), que vai gerenciar a pausa. A chamada do setTimeout() em si já está finalizada, e ela sai da stack.
Nesse momento também temos a execução da última instrução do programa, console.log(‘fim do programa’), que já é exibido no terminal. Esta chamada vai para a call stack, é executada e já retirada da pilha em seguida, conforme abaixo:
Imagem 4 - Node.js por baixo dos panos: Momento 3
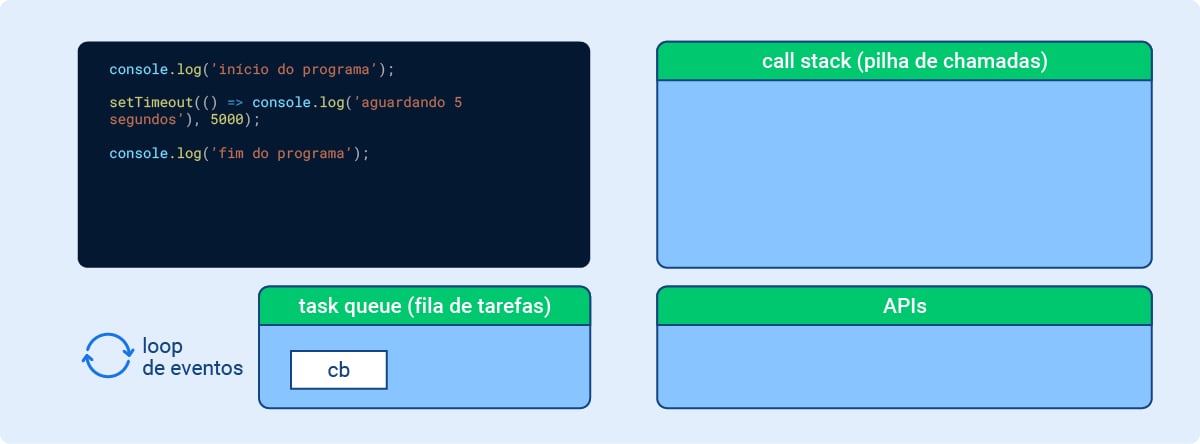
Momento 4: Finalmente chegamos ao loop de eventos! O timer de 5 segundos está finalizado e a API “empurra” o callback (que vamos chamar aqui de cb, como usado na documentação do Node.js) para a task queue, ou fila de tarefas. Confira na sequência abaixo:
Imagem 5 - Node.js por baixo dos panos: Momento 4
console.log('aguardando 5 segundos'), 5000); console.log('fim do programa'); A segunda é uma sequência de funções chamadas de “call stack (pilha de chamadas)” que está vazia; A terceira é um campo chamado “task queue (fila de tarefas)” que possui a opção “cb”. À esquerda desse campo, há um ícone de duas setas formando um círculo junto à descrição “loop de eventos”; Por último um campo chamado “APIs” que está vazio.">
Ao contrário da pilha, que segue o conceito LIFO (last in, first out), as filas são estruturas de dados que seguem o conceito FIFO (first in, first out), ou seja, o primeiro item a entrar é o primeiro a sair.
Stack (pilha) e queue (fila) são estruturas de dados muito comuns em programação. Se quiser saber um pouco mais sobre elas, com exemplos, pode consultar nosso artigo sobre estruturas de dados.
Distinção importante: Assincronicidade e funções callback não estão necessariamente relacionadas; há uma diferença entre as callbacks que estamos explicando aqui e callbacks que executam de forma síncrona no código. Uma função callback é uma função “chamada de volta” (called back) por outra função ou método e são amplamente usadas pelo JavaScript nos mais diversos contextos, de forma síncrona e assíncrona. Por exemplo, callbacks chamadas dentro de métodos síncronos de array como Array.forEach().
Uma vez que o callback foi enviado para a task queue, entra em cena o loop de eventos.
Loop de eventos
Momento 5: Entra em cena o loop de eventos. A única tarefa restante é olhar a stack e a queue. Se a stack estiver vazia, o primeiro callback que estiver na queue (lembrando do princípio LIFO) é empurrado para a stack, o que efetivamente faz com que o callback seja executado (no caso, console.log(‘aguardando 5 segundos’)).
Imagem 6 - Node.js por baixo dos panos: Momento 5
console.log('aguardando 5 segundos'), 5000); console.log('fim do programa');. A segunda é uma sequência de funções chamadas de “call stack (pilha de chamadas)”: que só possui a função console.log(‘aguardando…’) destacada de azul; A terceira é um campo chamado “task queue (fila de tarefas)” que está vazio. À esquerda desse campo, há um ícone de duas setas formando um círculo junto à descrição “loop de eventos”; Por último um campo chamado “APIs” que está vazio.">
Momento 6: O programa encerra (process.exit()) quando não há eventos na fila para serem chamados pelo loop de eventos e quando não há processamentos pendentes na pilha de chamadas.
Vamos conferir mais um exemplo deste processo em movimento:
IMPORTANTE: Mesmo que o setTimeout estivesse configurado para executar após 0, o processo seria o mesmo, pois o callback seria empurrado para a fila de timers da mesma forma, ficando na queue até que a stack estivesse vazia - no caso, após todos os outros console.log()e processos da main() fossem executados.
Entendendo o loop de eventos
Agora que já vimos um breve exemplo de funcionamento, vamos pontuar alguns pontos importantes sobre o funcionamento do loop de eventos.
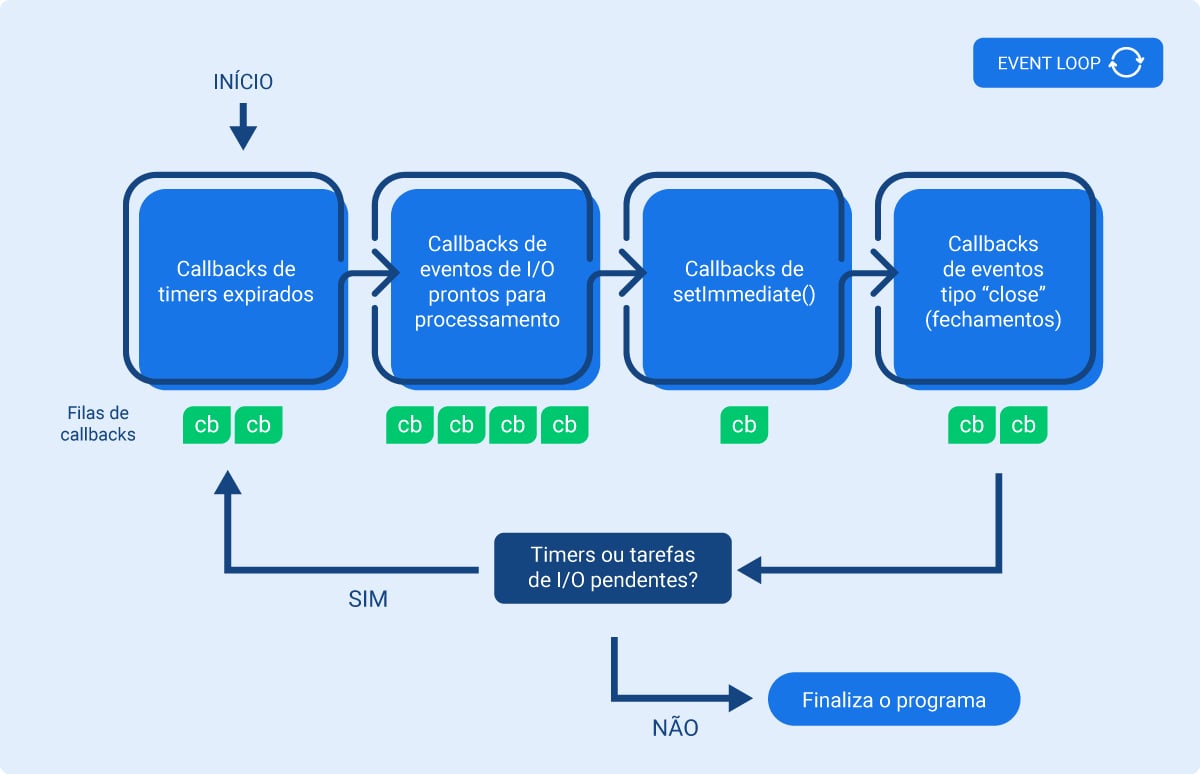
O loop de eventos é iniciado junto com a aplicação e cada loop é composto pelas seguintes fases de execução:
Callbacks dos timers expirados: são os primeiros a serem executados assim que possível - ou seja, quando a call stack se encontra vazia;
I/O polling: eventos de I/O que estão prontos para serem processados, como acesso a arquivos, tarefas de rede, etc) - a maior parte dos callbacks é referente a este tipo de operação e ocorre nesta fase;
setImmediate(): um tipo de timer especial que podemos usar quando queremos que um callback seja processado imediatamente (casos de uso mais avançados);
Eventos de encerramento: métodos para fechar conexões abertas, como conexões com bancos ou sockets (por exemplo o método socket.close()).
Além disso, o loop de eventos ainda conta com duas outras filas, mais relacionadas a casos avançados de uso e que não abordaremos com detalhes aqui:
process.nexttick(): resolução de promessas. Ocorre logo após a fase de encerramento de cada loop, ao invés de esperar passar por todos os outros callbacks que podem estar no loop.
Outras microtasks diversas.
Mas se aprendemos anteriormente que a fila gerenciada pelo loop é uma só, como essas fases funcionam? Internamente o loop de eventos gerencia estas fases através de “sub-filas” de acordo com o tipo de processamento.
Confira este processo acontecendo no diagrama abaixo:
Imagem 7 - Execução do loop de eventos
Como o Node.js sabe se o loop deve continuar no próximo tick ou se o programa deve ser encerrado? Checando se ainda existem timers ou tarefas I/O pendentes.
Se não existem, vai finalizar a aplicação;
Se existem, continua no loop. Por exemplo, se existem conexões abertas que mantêm o programa rodando.
Resumindo o loop de eventos
Vamos agrupar o funcionamento do loop de eventos em alguns tópicos:
O loop de eventos recebe eventos externos e os converte em chamadas de callbacks para serem processados, além de executar sub-tasks que estejam em fila;
O loop acessa callbacks de eventos que estão na task queue (que também é chamada de event queue) e empurra os callbacks para a call stack;
O loop de eventos executa tarefas começando da mais antiga, ou que chegou primeiro à fila - princípio FIFO;
É parte de um panorama maior da arquitetura do node, que envolve o V8 e outras APIs. setTimeout(), por exemplo, não faz parte do V8, e sim das APIs do ecossistema;
O loop de eventos também não faz parte do código do V8, e sim da biblioteca libuv.
Funcionalidades do loop de eventos:
É um loop infinito, que aguarda tarefas, as executa e então entra em espera até o recebimento de novas tarefas;
O loop pega e executa tarefas da task queue APENAS quando a call stack está vazia. Ou seja, quando não há tarefas em andamento (funções sendo executadas pela pilha).
Podemos analisar estas características no diagrama abaixo:
Imagem 8 - Características do loop de eventos
Nunca bloqueia?
Uma das características mais importantes de todo esse modelo do loop de eventos era fazer com que operações que bloqueiam a execução do programa, como operações I/O, se tornassem não-bloqueantes e assíncronas. Porém é sim possível bloquear a execução de um programa em JavaScript, e normalmente isso é causado por problemas na implementação do código e não por bugs internos do Node.js.
Por isso, para evitar que um programa seja implementado de forma a bloquear a thread do loop de eventos, podemos tomar algumas precauções:
Não utilize versões sync de APIs do node como fs, crypto e zlib, a não ser em casos muito específicos. Um caso de uso síncrono de funções de fs é a biblioteca dotenv, que utiliza a versão sync, pois ela precisa garantir que as variáveis de ambiente estão configuradas antes de liberar a execução do programa;
Evite que cálculos com números grandes sejam enviados para a thread do loop;
Evite o processamento de JSONs muito grandes;
Idem para expressões regulares muito complexas.
O motivo para evitarmos cálculos e processamentos muito grandes é justamente o fato do loop de eventos ser single-thread; o que faz com que ele seja muito eficiente para operações assíncronas, mas não consegue evitar que o loop “trave” se tivermos uma operação que exija muito processamento ocupando a pilha de chamadas.
Claro que sempre haverá outras situações similares, que envolvem normalmente muito processamento síncrono. Para esse tipo de caso é possível usar processos-filho (child processes) ou mover os processos para novas threads de forma manual, instruindo o programa a criar threads específicas. Não vamos abordar estas estratégias neste artigo, mas você pode pesquisar threads, child processes e web workers na documentação oficial do Node.js.
E no front-end?
O que discutimos neste artigo sobre V8 e loop de eventos vai funcionar de forma muito similar nos navegadores - por exemplo, no Chrome - que inclusive utiliza o mesmo runtime V8.
Os conceitos e partes da arquitetura também podem ser aplicados: eventos (neste caso, normalmente relacionados a ações dos usuários), processos e o próprio loop de eventos vão se comportar basicamente da mesma forma, porém sem as APIs em C++ e com a adição de outras APIs, como a de manejo do DOM, que o Node.js não precisa ter.
Outros navegadores utilizam outros motores para interpretação do JavaScript, que não são o V8. Por exemplo, o Mozilla Firefox tem seu próprio motor, o SpiderMonkey. Isso significa que a implementação dos métodos e funções do JavaScript definidos pelo ECMA pode ser diferente por “baixo dos panos”.
Conclusão
Conferimos neste artigo que o Node.js é uma plataforma baseada em eventos, capaz de executar programas de forma assíncrona e não-bloqueante, composta de diversas bibliotecas e APIs. O loop de eventos permite que o Node.js execute de forma não-bloqueante operações usualmente bloqueantes, como eventos de I/O (input e output) e delegando processamento ao sistema operacional sempre que possível.
Também abordamos muitos assuntos relacionados a arquitetura de computadores, ao funcionamento de nossos programas e ao que acontece com o código “por baixo dos panos”: threads, processos, eventos, como se dá o processamento de informações, pilhas e filas.
Entender todas as partes do Node.js e como elas trabalham pode ser muito útil quando tivermos que lidar com bugs ou comportamentos não esperados, como por exemplo processamento de informações travando o programa, ou funções aparentemente sendo executadas fora de ordem; além disso, conhecer o funcionamento do loop de eventos nos ajuda a evitar este tipo de problema de antemão, especialmente se tivermos que lidar com quantidades maiores de dados ou com funções que exigem muito processamento, como a biblioteca crypto.
Cada um dos tópicos pode ser expandido e aprofundado na medida em que vamos adicionando conhecimento ao nosso repertório.
Espero que faça bom proveito do conteúdo e bons estudos ;)





 console.log('aguardando 5 segundos'), 5000); Está associado a função setTimeout()">
console.log('aguardando 5 segundos'), 5000); Está associado a função setTimeout()">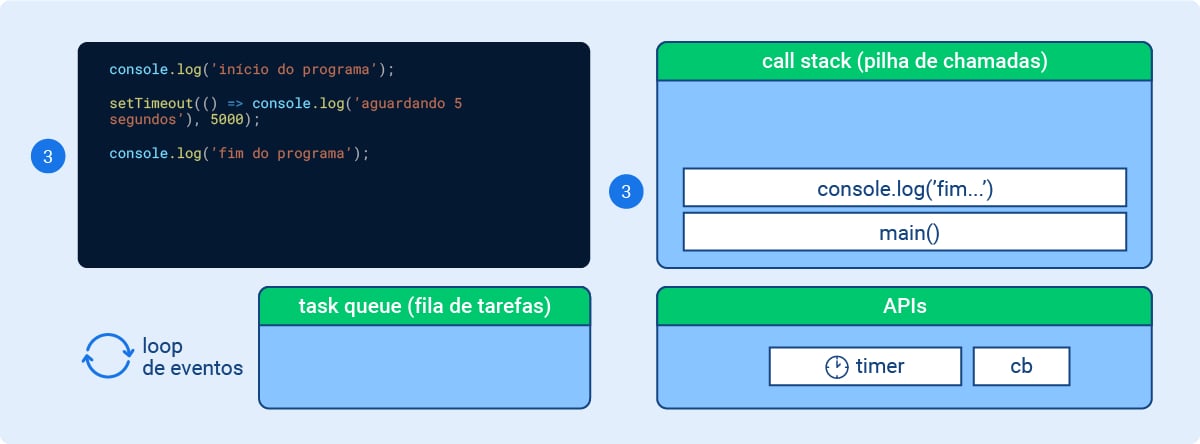
 console.log('aguardando 5 segundos'), 5000); console.log('fim do programa'); A segunda é uma sequência de funções chamadas de “call stack (pilha de chamadas)” que está vazia; A terceira é um campo chamado “task queue (fila de tarefas)” que possui a opção “cb”. À esquerda desse campo, há um ícone de duas setas formando um círculo junto à descrição “loop de eventos”; Por último um campo chamado “APIs” que está vazio.">
console.log('aguardando 5 segundos'), 5000); console.log('fim do programa'); A segunda é uma sequência de funções chamadas de “call stack (pilha de chamadas)” que está vazia; A terceira é um campo chamado “task queue (fila de tarefas)” que possui a opção “cb”. À esquerda desse campo, há um ícone de duas setas formando um círculo junto à descrição “loop de eventos”; Por último um campo chamado “APIs” que está vazio.">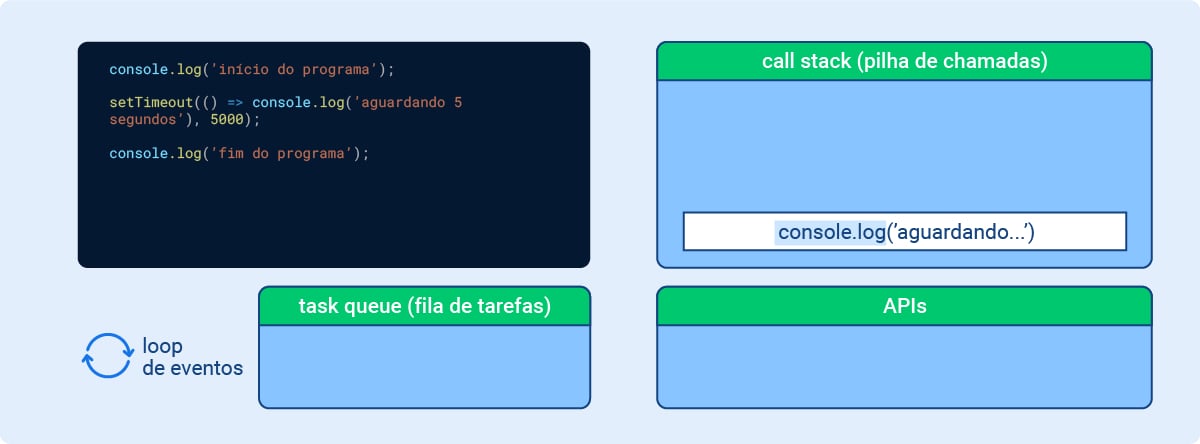 console.log('aguardando 5 segundos'), 5000); console.log('fim do programa');. A segunda é uma sequência de funções chamadas de “call stack (pilha de chamadas)”: que só possui a função console.log(‘aguardando…’) destacada de azul; A terceira é um campo chamado “task queue (fila de tarefas)” que está vazio. À esquerda desse campo, há um ícone de duas setas formando um círculo junto à descrição “loop de eventos”; Por último um campo chamado “APIs” que está vazio.">
console.log('aguardando 5 segundos'), 5000); console.log('fim do programa');. A segunda é uma sequência de funções chamadas de “call stack (pilha de chamadas)”: que só possui a função console.log(‘aguardando…’) destacada de azul; A terceira é um campo chamado “task queue (fila de tarefas)” que está vazio. À esquerda desse campo, há um ícone de duas setas formando um círculo junto à descrição “loop de eventos”; Por último um campo chamado “APIs” que está vazio.">