até
 % OFF
% OFF
% OFF
% OFFOlá! Meu nome é Rodrigo Dias e serei seu instrutor no curso de Spark para Data Science!
Rodrigo Dias é um homem branco de olhos verdes, cabelos castanhos, barba e bigode curtos e grisalhos. Veste uma camiseta preta de tecido liso e está sentado em um ambiente de iluminação natural. Ao fundo, há um armário, uma estreita estante com livros e uma cortina na cor verde.
Este curso é de caráter introdutório e visa apresentar a ferramenta Spark, instrumento importante para que possamos trabalhar com um grande número de dados. Aprenderemos como manipular esses dados através dos recursos dessa ferramenta.
Iniciaremos com a configuração do Spark em uma máquina local e no notebook do Colab - serviço de armazenamento de notebooks em nuvem que permite criar e executar códigos em Python.
Em seguida, aprenderemos a carregar um conjunto de dados relativamente grande em dataframes (espécie de tabela de dados) do próprio Spark, o que permitirá que sejam manipulados e alterados. Veremos, ainda, como utilizar comandos SQL puros para consultar esses dados.
Para lembrar: SQL é a sigla para “Structured Query Language”, ou “Linguagem de Consulta Estruturada”, em português. Trata-se de uma linguagem de programação para lidar com banco de dados baseados em tabelas. Permite que vários desenvolvedores acessem e modifiquem dados de uma empresa simultaneamente, de maneira simples e unificada.
Por fim, conheceremos alguns tipos de arquivos utilizados em projetos Big Data e como criá-los.
Vamos lá?
Vamos começar o nosso curso de Spark!
A aplicação de ciência de dados e a construção de modelos de Machine Learning rápidas e eficientes tornam-se um desafio com o aumento do fluxo de informações. Ferramentas comumente utilizadas, como Pandas, por exemplo, mostram-se menos performáticas. Como solução para situações em que há um alto processamento de fluxo de dados em tempo real, temos o Apache Spark, idealizado para acelerar o processo de tomada de decisão, redução de custo e de tempo de processamento.
O Spark é uma plataforma que permite a distribuição de dados em diversos clusters (conjuntos de computadores) com vários nós, onde cada nó representa um computador. Ele carrega e armazena esses dados em cache de memória e os lê quantas vezes forem necessárias. A computação em memória é muito mais rápida do que aplicativos baseados em disco, por isso o Spark pode ser 100 vezes mais rápido do que algumas dessas aplicações.
Deixamos um notebook estruturado que você pode baixar e utilizar para acompanhar as aulas. Nele, você encontrará explicações e referências às bibliotecas utilizadas no decorrer do curso, além de links que o levarão à documentação do Apache Spark.
Observe, no notebook, que há o PySpark, pacote responsável por dar acesso à linguagem Python e que nos permite construir aplicações por meio dessa linguagem. Em seguida, há uma imagem exibindo os componentes para diferentes tipos de processamentos, todos construídos sobre o Spark Core - responsável por disponibilizar funções básicas desse processamento. Vale ressaltar que esses componentes funcionam integrados na própria ferramenta, o que é um diferencial se comparado à outras aplicações em que eles são distribuídos separados da ferramenta.
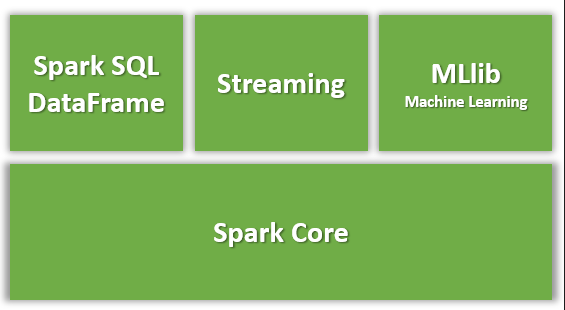
Neste curso, falaremos sobre o componente Spark SQL, que nos permite usar SQL para realizar consultas e processamento sobre os dados no Spark, além de oferecer o dataframe.
A partir dessas informações, você deve estar se perguntando qual a utilidade do Pandas diante do Spark. Em suma, em um cenário de conjunto de dados mais enxutos, o Pandas pode se mostrar mais adequado, enquanto o Spark performa melhor quando tratamos de um grande fluxo de dados em tempo real. Outra diferença importante, é que o Pandas limita-se à memória do seu computador, então o dataframe não pode ser tão grande quanto no Spark.
Agora que você entendeu alguns conceitos introdutórios, aprenderemos, a seguir, a configurar o nosso ambiente e instalá-lo no Windows e no notebook Colab.
Te encontro lá!
Você deve ter percebido que no notebook disponibilizado há o passo a passo a ser seguido, faremos juntos!
Veremos, primeiro, como obter e rodar o Spark no Windows e depois no Colab, ferramenta que será usada no curso.
Para usar o Spark, é necessário que tenhamos instalado, no mínimo, a versão 7 do Java. Caso você já tenha o Java instalado, basta digitar o comando java -version no terminal para verificar a versão que você está usando. Caso não o tenha, clique neste link para ser redirecionado à página de download da versão mais recente do Java. Este é o primeiro passo!
O próximo passo é instalar o Python, que deve ser a versão 2.6 ou superior. Caso você o tenha, digite o comando python --version no terminal para verificar a versão que você está utilizando. Caso não o tenha, este link te redireciona para a página de download da versão mais recente do Python.
Agora precisamos "instalar" o Spark. Ele não requer necessariamente uma instalação, o que faremos é baixar o pacote disponível neste link. Para a criação deste projeto, utilizamos a versão 3.1.2 do Spark e o pacote do tipo Pre-built for Apache Hadoop 2.7.
O arquivo virá zipado com a extensão .tgz, então basta extraí-lo para uma pasta de sua escolha.
Certifique-se de que o caminho onde os arquivos do Spark foram armazenados não contenha espaços.
Nesta etapa, vamos instalar o Find Spark. Para isso, basta digitar o comando pip install findspark no terminal.
Por fim, temos um passo extra, necessário para quem for utilizar o shell do Spark: instalar o winutils.
Os arquivos do Spark não incluem o utilitário winutils.exe que é utilizado pelo Spark no Windows. Se não informar onde o Spark deve procurar este utilitário, veremos alguns erros no console e não conseguiremos executar scripts Python com o utilitário spark-submit.
Para evitar esses erros, faça o download da versão do winutils compatível com a versão do pacote do Spark que você baixou anteriormente.
Optamos pela versão 2.7 do pacote. Caso você também tenha optado por ela, este link irá redirecioná-lo para a versão do winutils compatível com ela.
Note que há vários arquivos, mas você fará download somente do arquivo winutils.exe.
Em seguida, dentro da pasta para a qual você extraiu os arquivos do Spark, crie uma nova pasta chamada "hadoop" e, dentro desta, uma pasta chamada "bin" para a qual você deve copiar o arquivo winutils.exe.
Agora tentaremos rodar o Spark, mas, para isso, precisaremos do PySpark - interface que permite o acesso e utilização do Spark por meio da linguagem Python. Note que nós não o instalamos, mas ele é embutido no arquivo do Spark que baixamos anteriormente. Para utilizá-lo, precisaremos de alguns passos. Veremos quais são eles.
Crie um notebook e, em uma célula, digite o comando de importação do pacote OS, que permite que possamos definir uma variável de ambiente para o notebook. Para importá-lo, digite o comando import os e na linha seguinte os.environ["SPARK_HOME"] = " ". No espaço em branco, entre as aspas, colocaremos o endereço da pasta onde armazenamos o Spark.
Atenção: o código contém o endereço da pasta da máquina do instrutor. Caso prefira, você pode nomear a sua pasta da mesma maneira.
import os
os.environ["SPARK_HOME"] = "C:\spark\spark-3.1.2-bin-hadoop2.7"Em seguida, em uma nova célula, digite o comando responsável por informar à máquina o caminho para encontrar o PySpark:
import findspark
findspark.init()Adicione uma nova célula e passe o comando from pyspark.sql import SparkSession. Este comando é responsável por importar o PySpark e o módulo SparkSession.
Pronto! Agora, sim, podemos iniciar uma sessão do Spark!
Em uma nova célula, criaremos a variável spark onde chamaremos o SparkSession e o atributo .builder.master(). Passaremos 'local[*]' como parâmetro de builder.master() informando que queremos rodar localmente e, para finalizar, chamaremos o atributo .getOrCreate(),que irá, de fato, criar a sessão. O código ficará assim:
spark = SparkSession.builder.master(‘local[*]’).getOrCreate()Em seguida, digite o comando spark e perceba que, em alguns segundos, recebemos as informações de que o nosso Spark está rodando localmente com a versão 3.1.2, utilizando todas as CPUs, além do nome da nossa aplicação. Note que aparecerá um link "clicável" do Spark UI, interface de usuário que nos permite acompanhar os projetos em andamento. Falaremos dela mais adiante.
Esta foi a configuração no Windows. A seguir, faremos a configuração no Colab. Até lá!
O curso Spark: apresentando a ferramenta possui 186 minutos de vídeos, em um total de 66 atividades. Gostou? Conheça nossos outros cursos de Engenharia de Dados em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:

O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






