Olá! Tudo bem?
Boas-vindas ao nosso curso de Machine Learning! Aqui vamos discutir sobre a validação dos nossos estimadores. Isso foi feito anteriormente, no curso Introdução à Classificação, que é pré-requisito para este. Nele, usamos a técnica de holdout, com a qual separamos dados de treino e dados de teste, que é suficiente para uma primeira tentativa de validação. Mas, como veremos durante o curso, apresenta alguns problemas.
Em contraponto, existem diversas alternativas baseadas na técnica de validação cruzada que vamos utilizar nesse curso com o estimador que trabalhamos anteriormente para entender melhor como ele funcionará no mundo real.
Estudaremos a motivação para a validação cruzada, a importância da aleatoriedade e simularemos situações de azar, quando não se usa validação cruzada ou estratificação ou ambos. Além disso, falaremos sobre dados que possuem características que os permitem ser independentes entre si.
Neste curso, vamos buscar saber não apenas como nosso algoritmo se comporta com carros que ele já conhece, mas também como ele se comportará com modelos de carros nunca vistos. E, a partir deles, como fazer a validação cruzada com grupos. Além disso, como colocar essa validação cruzada em um processo.
Tudo isso será abordado neste curso!
Começaremos o curso importando o projeto do Python notebook do Google Colab, como fizemos no curso anterior. Caso você não o tenha cursado, o importante é conhecer o conteúdo apresentado. Vocês encontram o arquivo nas próximas atividades.
Clicando em "UPLOAD > Choose File", escolheremos "Machine_Learning_Validação.pynb". Você pode usar um Jupyter local para trabalhar em seu notebook, ou o Cloud, como usamos no vídeo. Optamos pelo Google por sua praticidade e rapidez.
Vamos dar uma revisada no projeto! Primeiro, carregamos um arquivo .csv.
import pandas as pd
uri = "https://gist.githubusercontent.com/guilhermesilveira/e99a526b2e7ccc6c3b70f53db43a87d2/raw/1605fc74aa778066bf2e6695e24d53cf65f2f447/machine-learning-carros-simulacao.csv"
dados = pd.read_csv(uri).drop(columns=["Unnamed: 0"], axis=1)
dados.head()Com a uri copiada, podemos colá-la e acessá-la em nosso navegador. Notem que ela possui cinco colunas, sendo que a primeira não tem nome, é apenas um índice. Portanto, vamos descartá-la.
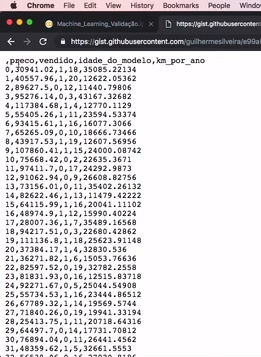
As próximas duas colunas indicam o suposto preço de venda de um carro, e se ele foi ou não (0 ou 1) vendido. Então, cada linha representa um veículo, em um site hipotético de vendas de automóveis, começando por um contador — que não utilizaremos —, seguido por:
preco: preço desejado de venda;vendido: se foi vendido ou não (0 ou 1);idade_do_modelo: indica de quantos anos atrás é esse carro;km_por_ano, com a média de quilometragem que esse carro andou por ano.Em seguida, o código carrega o arquivo com read_csv e eliminamos a coluna sem nome Unnamed: 0.
dados = pd.read_csv(uri).drop(columns=["Unnamed: 0"], axis=1)Ao executarmos o código, a biblioteca do Pandas será carregada, inicializando nosso ambiente do Python no Cloud do Google, entre outros, e nos trará o resultado da tabela com apenas as colunas que temos interesse.
| preco | vendido | idade_do_modelo | km_por_ano | |
|---|---|---|---|---|
| 0 | 30941.02 | 1 | 18 | 35085.22134 |
| 1 | 40557.96 | 1 | 20 | 12622.05362 |
| 2 | 89628.50 | 0 | 12 | 11440.79806 |
| 3 | 95276.14 | 0 | 3 | 43167.32682 |
| 4 | 117384.68 | 1 | 4 | 12770.11290 |
vendido é uma categoria, a classificação que vamos utilizar são das classe 0 e 1. preco, idade_do_modeloe km_por_ano são as variáveis que temos de features para analisar. Primeiro, separaremos tudo entre os dados x e y, da seguinte forma:
x = dados[["preco", "idade_do_modelo", "km_por_ano"]]
y = dados["vendido"]Sendo x o que queremos analisar, e y a nossa classificação. Também vamos separar "treino" e "teste", usando o SKLearn. Vamos separar 75% para treino e 25% pra teste.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
x = dados[["preco", "idade_do_modelo","km_por_ano"]]
y = dados["vendido"]
SEED = 158020
np.random.seed(SEED)
treino_x, teste_x, treino_y, teste_y = train_test_split(x, y, test_size = 0.25,
stratify = y)
print("Treinaremos com %d elementos e testaremos com %d elementos" % (len(treino_x), len(teste_x)))Ao rodarmos o código exibido acima, são separados 7500 elementos para treino e 2500 para teste.
Treinaremos com 7500 elementos e testaremos com 2500 elementosNa sequência, encontraremos o classificador, mas antes de rodá-lo, decidiremos o que é uma taxa de acerto aceitável, diferenciando uma boa de uma ruim. Uma maneira seria olharmos carro a carro, analisando preco, idade_do_modelo e km_por_ano de cada um e consultarmos um expert humano para saber se o veículo em questão seria ou não vendido. E, com isso, conferir a taxa de acerto de um expert humano. Ou, melhor que um expert humano, seriam vários experts humanos e, a partir deles, tiraríamos uma média, de modo que atingiríamos uma taxa de acerto maior. É desejável que nosso algorítimo seja tão bom quanto ou melhor do que isso.
Para os dados fictícios que geramos para o exercício deste curso, não temos um expert humano. Então a base que assumiremos é a seguinte: ao analisarmos nossos dados, percebe-se que 70% dos carros foram vendidos e 30% dos carros não foram vendidos. Poderíamos, então, supor que esses números vão perdurar, porque são eles que temos como base por nossa experiência. Este algorítimo é um base-line chamado Dummy Classifier, que é estratificado (stratified) por padrão na versão usada pelo instrutor, porém com a atualização da biblioteca, precisamos colocar o valor de strategy='stratified'.
from sklearn.dummy import DummyClassifier
dummy_stratified = DummyClassifier(strategy='stratified')
dummy_stratified.fit(treino_x, treino_y)
acuracia = dummy_stratified.score(teste_x, teste_y) * 100
print("A acurácia do dummy stratified foi de %.2f%%" % acuracia)Ao executá-lo, obteremos a taxa de acerto de 51% (50.96%).
A acurácia do dummy stratified foi de 50.96%Um expert humano, provavelmente, teria porcentagem de acerto maior. Todavia, não temos recurso financeiro para este tipo de avaliação.
Portanto, abaixo, rodaremos a árvore de decisão (DecisionTreeClassifier) — abordada em cursos anteriores —, com profundidade máxima (max_depth) igual a 2.
from sklearn.tree import DecisionTreeClassifier
SEED = 158020
np.random.seed(SEED)
modelo = DecisionTreeClassifier(max_depth=2)
modelo.fit(treino_x, treino_y)
previsoes = modelo.predict(teste_x)
acuracia = accuracy_score(teste_y, previsoes) * 100
print ("A acurácia foi %.2f%%" % acuracia)Reparem que esses códigos são os que trabalhamos no curso anterior. Ao rodarmos o de DecisionTreeClassifier, a taxa de acerto sobe para, aproximadamente, 72%:
A acurácia foi 71.92%Mas, suponhamos que experts humanos são capazes de acertar 73%. Para nos igualarmos a eles, precisaremos mudar o algorítimo.
Entretanto, reparem que o código tem um SEED de 158020, que é um número qualquer escolhido aleatoriamente, para que pudéssemos rodar várias vezes, obtendo o mesmo resultado. Então, o que mudaria se alterássemos esse valor?
Vamos aplicar alguns testes, copiando e colando o mesmo código e removendo os imports no início do código.
x = dados[["preco", "idade_do_modelo","km_por_ano"]]
y = dados["vendido"]
SEED = 158020
np.random.seed(SEED)
treino_x, teste_x, treino_y, teste_y = train_test_split(x, y, test_size = 0.25,
stratify = y)
print("Treinaremos com %d elementos e testaremos com %d elementos" % (len(treino_x), len(teste_x)))
modelo = DecisionTreeClassifier(max_depth=2)
modelo.fit(treino_x, treino_y)
previsoes = modelo.predict(teste_x)
acuracia = accuracy_score(teste_y, previsoes) * 100
print("A acurácia do dummy stratified foi %.2f%%" % acuracia)Vamos rodar o teste inteiro e conferir o que acontece. Com SEED igual a 158020, obteremos:
Treinaremos com 7500 elementos e testaremos com 2500 elementos
A acurácia foi de 71.92%A acurácia foi de 71.92%, como esperado. Mas e se alterarmos o valor SEED para 5?
x = dados[["preco", "idade_do_modelo","km_por_ano"]]
y = dados["vendido"]
SEED = 5
np.random.seed(SEED)
treino_x, teste_x, treino_y, teste_y = train_test_split(x, y, test_size = 0.25,
stratify = y)
print("Treinaremos com %d elementos e testaremos com %d elementos" % (len(treino_x), len(teste_x)))
modelo = DecisionTreeClassifier(max_depth=2)
modelo.fit(treino_x, treino_y)
previsoes = modelo.predict(teste_x)
acuracia = accuracy_score(teste_y, previsoes) * 100
print("A acurácia do dummy stratified foi %.2f%%" % acuracia)Ao executar o código, obteremos o seguinte retorno:
Treinaremos com 7500 elementos e testaremos com 2500 elementos
A acurácia foi de 76.84%A acurácia sobe para 76.84%, quase 77%! Então, aquela decisão de julgar isso como bom ou ruim em comparação ao que obtínhamos com Dummy Classifier está melhor, entretanto, ainda estamos vulneráveis a tomar uma decisão baseada em uma aleatoriedade. Não faz sentido validar, julgar se é bom ou ruim, de acordo com um número aleatório. Queremos minimizar o efeito dessa aleatoriedade, dessa escolha aleatória do treino, do teste e da DecisionTreeClassifier, na nossa decisão.
No entanto, se rodamos o treino e o teste uma única vez, corremos o risco de os ter separado mal. Precisamos de outra forma de treinar e testar mais de uma vez para que não tenhamos uma estimativa única, uma maneira que permita rodar o treino e o teste diversas vezes e, a partir disso, obter uma estimativa.
Em vez de um ponto, queremos um intervalo. Precisamos encontrar um método, um algorítimo para isto. Adiante, estudaremos como solucionar essa questão!
Anteriormente, percebemos que, se usarmos a técnica de separar uma parte dos dados para treino e outra para testes, seguramos uma parte dos dados. Em inglês, isto é chamado de Holdout.
Por exemplo, se temos 12 elementos para analisar com o algoritmo, podemos separar os 9 primeiros (de 01 a 09) para treino, e os 3 restantes (de 10 a 12) para testes.
| 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | 11 | 12 |
Nesse teste, obteríamos o péssimo resultado de 35%. Como falado, isto pode ter sido fruto de uma aleatoriedade, sorte ou azar, porque cada elemento tem uma característica. Então, se tivéssemos separado outros elementos para treino e outros elementos para testes, como 04, 07 e 09 para teste e o restante (01, 02, 03, 05, 06, 08, 10, 11 e 12) para treino:
| 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | 11 | 12 |
Nesse caso, o resultado seria 78%. Ou ainda, se fizéssemos outra seleção, pegando 02, 04 e 11 para teste, deixando o restante para treino.
| 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | 11 | 12 |
Então, teríamos 70% como resultado. Que horrível! Por quê? Porque, a cada mudança, ficamos suscetíveis a um número aleatório que define o que será escolhido para treino ou teste, ou de repente à ordem original da sequência — se não fizermos um shuffle — e isto é extremamente arriscado, pois ficamos suscetíveis a esse detalhe horrível, para tomar uma decisão super importante.
Outro exemplo do nosso dia a dia, é quando precisamos fazer uma prova. Imagine que no dia precedente à prova, você receba uma notícia pessoal desagradável, ou acabe brigando com alguém do seu convívio, e, por essa razão, você vá mal na prova e tire 3.5 de 10. Mas se um fator externo afetou seu resultado, não necessariamente significa que você não saiba o conteúdo. Porém, pense: durante um semestre, ou um ano, costuma-se fazer apenas uma prova? Não! É costume que façamos, pelo menos, duas provas e, a partir da soma e divisão do valor de ambas, conseguimos a média!
Então, repare que, no momento em que testamos o algoritmo — ou um(a) aluno(a), por exemplo — diversas vezes, começamos a diminuir a influência de alguns fatores externos. No caso da prova, pode ser alguma situação pessoal; ou no caso de um algoritmo que estivermos rodando, pode ser o shuffle, entre outros problemas. Ou seja, ao rodar o teste várias vezes, podemos tirar uma média simples. Por exemplo, em três provas, considerando que as notas obtidas em cada uma foram: 3.50, 7.80 e 7.00, a média simples delas seria 6.10 (resultado da soma das três notas, dividido por 3).
E podemos fazer a mesma coisa em nosso algoritmo de treino e teste. Em vez de rodar uma única vez o treino e o teste, vamos rodar dois testes, ou seja, treinaremos e testaremos duas vezes e tiraremos a média.
Isso é, pegamos os 12 elementos e definimos que eles serão divididos em dois — podemos dividir entre a primeira metade e a segunda —, treinamos com os 6 primeiros e testamos com os outros 6. O resultado será de 55%. Em ordem contrária, o resultado é de 78%, logo, a média é 66.5% (resultado da soma das duas porcentagens dividido por 2).
Repare que, desta maneira, nós começamos a diminuir a influência de aleatoriedades nas posições, ou talvez de uma pré determinação das posições dos elementos, sobre o resultado. Em vez de apenas separarmos treino e teste e fazermos o holdout, separaremos em N pedaços (aqui, em 2), para treinar, testar e validar o algoritmo de maneira cruzada. O nome deste processo é Cross Validation, e há diversas maneiras de colocá-lo em prática.
No último exemplo, foram separados dois pedaços e feitos dois testes. Poderíamos ter separado em 4 pedaços e, se fosse o caso, teríamos 4 conjuntos de 3. Então treinaríamos com 3/4 e testaríamos com um 1/4. O resultado seria de 35%. Ao treinar com o 1/4 restante, obteríamos o resultado de 88%. Ao separar 1/4 de novo, obteríamos 76%. Continuando com a separação de outra parcela, obteríamos 74%. Considerando estes valores, a média seria de 68.25%. Então, reparem que, em vez de quebrar em dois pedaços e executar duas vezes o treino-teste, agora quebramos em 4 pedaços e executamos o treino-teste 4 vezes também.
Aqui, por praticidade, foram escolhidos 12 elementos para que fossem divisíveis por 2 e por 4, mas não precisava ser exatamente o mesmo número, poderia ser 3, 3, 3 e 2, se tivéssemos só 11 elementos, por exemplo. O principal aqui é a ideia de que quebrarmos os dados em N pedaços e, então, rodarmos K processos de treino e teste, validando nosso algoritmo de maneira cruzada. Esse processo é chamado de K-fold, referente ao número (K) de vezes que quebraremos os dados para rodar a validação cruzada.
Reparem que, se dividirmos em 8 pedaços, e tivermos N elementos e rodarmos todos eles, teremos 8 números diferentes. Por exemplo, se obtivermos 65%, 76%, 74%, 70%, 66%, 62%, 68% e 69%, a média será de 68.75%. Porém, a média é um ponto.
Nos cursos básicos de estatística, como temos na Alura, percebemos como ela é uma medida difícil de utilizarmos secamente, pontualmente. O mais desejável é usar um intervalo no qual confiamos ter um número razoável para o algoritmo funcionar no mundo real.
Então, quando temos um conjunto de números como esse, que contém 8, podemos usar a média e o desvio padrão, se acreditarmos que essa distribuição é normal. Ambos desviam padrões, e nós temos um intervalo entre 60% e 77%, nesse caso específico.
Nós faremos a construção dessa média em Python, logo a seguir.
Por fim, pense em um caso extremo, no qual temos 12 elementos e os quebramos ao máximo, em 12 pedaços. Assim, em um dos 12 treinos e testes, treinaremos com 11 deles e testaremos com 1. Ou seja, vamos testar o número de elementos que tivermos N vezes. Este algoritmo será muito lento, porque esse processo de validar, deixando um isolado, nos obriga a rodá-lo K vezes (o número de elementos que possuímos).
Entretanto, o processo é o mais fiel ao que esperamos com esse algoritmo no mundo real. Sendo assim, é muito importante decidirmos qual será o número K. Esse caso específico, em que o número K é exatamente o número de elementos que temos, é chamado de Leave One Out -"deixar um de fora", em português -, justamente por deixar um elemento de fora, isolado.
O curso Machine Learning: validação de modelos possui 80 minutos de vídeos, em um total de 34 atividades. Gostou? Conheça nossos outros cursos de Machine Learning & Deep Learning em Dados, ou leia nossos artigos de Dados.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Back-end, Dados, Front-end, DevOps, Mobile, Gestão & Negócios, UX & Design, Cibersegurança, Cloud, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Catálogo de tecnologia para quem é da área de Marketing
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
20% de desconto na Pós Tech
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Acesso ao catálogo da Casa do Código e leitura dentro da plataforma
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






