Boas-vindas a mais um curso da Alura. Meu nome é Rodrigo e eu serei seu instrutor nesse curso de Estatística com Python parte 4: Correlação e Regressão.
Esta é a parte 4 porque ele é de uma série de quatro cursos. No começo, falamos de estatísticas descritivas no primeiro, depois falamos de distribuições de probabilidade, estimação, depois falamos de testes de hipótese e agora, como eu disse, vamos falar de correlação e regressão. Tudo que vimos nesses outros cursos vão alimentar esse aqui, então é importante você ter isso de bagagem para utilizarmos nesse nosso treinamento.
Nós veremos testes de hipótese aqui, distribuições de probabilidade, estimação pontual, estimação intervalar, legal? Então, eu espero que esse curso seja muito útil para os seus estudos, para seu trabalho.
No próximo vídeo já começamos colocando a mão na massa e preparando o nosso ambiente para começar a trabalhar com regressão linear, beleza? Vejo você no próximo vídeo. Abraço!
Observação: Atualmente, não é mais necessário retroceder para a versão 1.2 do Scipy. Agora, basta substituir o comando
from scipy.misc import factorialporfrom scipy.special import factorialpara resolver o problema de incompatibilidade entre as versões das ferramentas.
Pessoal, antes de começarmos a rodar regressões, temos que conhecer o ambiente, abrir o dataset e, nesse caso aqui, temos que configurar uma coisinha nas bibliotecas que a gente vai utilizar, então vamos lá.
Usaremos, como temos usado nos outros treinamentos, o Colaboratory acessível neste link. Já deixei no projeto inicial o link para fazer download de dois notebooks e um dataset, para abrirmos aqui.
Gentilmente ele já abriu aqui todo o procedimento aqui de arquivo. A gente vem aqui na guia "Upload > Escolher arquivo" e lá, nos arquivos que eu deixei para você, tem esses dois aqui: “Curso de Estatística Parte 4” e “Verifica Versão”. Abre esse “Verifica Versão”, é bom a gente fazer isso junto para você ver a versão que você está usando.
Então, primeiro eu vou importar essas cinco bibliotecas.
import pandas
import numpy
import seaborn
import scipy
import statsmodels
O Scipy não vamos exatamente usar, mas como ele é uma dependência do Statsmodels, ele está tendo um probleminha nessa versão que eu estou usando aqui, então eu vou mostrar para você como corrigir para você poder utilizar sem problema. Vamos rodar isso aqui, demora um pouquinho porque acabamos de abrir, rodou.
Aqui embaixo tem uma rotina simples, aqui pra gente verificar a versão de cada uma dessas aqui de cima, tá bom?
print('Versão do pandas -> %s' % pandas.__version__)
print('Versão do numpy -> %s' % numpy.__version__)
print('Versão do seaborn -> %s' % seaborn.__version__)
print('Versão do scipy -> %s' % scipy.__version__)
print('Versão do statsmodels -> %s' % statsmodels.__version__)
Então está aqui, as versões são as seguintes: O Pandas está na 0.24.2, nesse momento que eu estou gravando o vídeo, você já está no futuro aí, verifica a versão que você está utilizando. O Numpy na 1.16.3, o Seaborn na 0.9.0, o Scipy, que teremos que modificar, está na versão 1.3.0, a minha aqui, e o Statsmodels 0.9.0.
Aqui, eu já deixei aqui certinho, a gente vai utilizar dentro do statsmodels uma funcionalidade pra gente poder estimar regressões. E, a gente vai fazer esse importe aqui:
import statsmodels.api
É nesse cara aqui que a gente começa a ter o problema. Ele vai reclamar e vai dizer que uma das dependências dele está com problema, que é justamente essa aqui: “from scipy.misc import factorial”. Eu vim aqui embaixo, selecionei só essa aqui pra gente rodar e verificar que realmente ela está problemática, ele reclama, faz a mesma reclamação.
from scipy.misc import factorial
A solução que eu encontrei foi fazer o downgrade da versão do scipy. Estamos com a 1.3, voltando para 1.2 conseguiremos executar os procedimentos da nossa aula, sem problema. Como fazer isso? Está aqui embaixo também, a gente escreve:
!pip install scipy==1.2 --upgrade
“Shift + Enter” roda essa célula, ele vai fazer o procedimento, não demora muito. Concluiu, ele já vem com o botão aqui embaixo para você restartar o runtime, então você clica o botão "Restart runtime", ele vai perguntar aqui, você clica em "Yes".
Está inicializando, quando na área superior direita ele exibir "Run" e "Disk", está pronto. Então, retornaremos para o início do notebook, vamos refazer todas as células anteriores, vamos lá, “Shift + Enter”. “Shift + Enter” nas versões, a versão aqui agora 1.2.0 do Scipy, é isso que a gente queria.
Aqui, para conferir se deu tudo certo import statsmodels.api. Já não reclama mais, aquela dependência que estava problemática, também, já não reclama mais, aqui é aquela coisinha que a gente fez. Eu deixei no nosso notebook, que eu já vou mostrar agora, está aqui nosso notebook que também está aí, você abre do mesmo jeito que eu abri.
Primeira coisa que temos que fazer, deixei para fazer junto com vocês. No menu lateral esquerdo, vir aqui na guia Files, clica em "Upload", aqui tem os dados.csv, clica duas vezes nesse arquivo, clica em OK nessa janela, ele vai puxar os dados. É o mesmo conjunto de dados que utilizamos no primeiro, no segundo, no terceiro curso em que estudamos estatística, no quarto é a mesma coisa.
Eu vou utilizar esses dados para fazer uma brincadeira quando estivermos trabalhando com covariância e correlação.
Para regressão, achei melhor não usar esse tipo de dado porque usar dado real, a gente pode encontrar alguns problemas e aí perde o foco do que a gente está querendo fazer, que é entender o procedimento de regressão.
Então está aqui no arquivo Curso_de_Estatística_Parte_4.ipynb, mesma coisa que a gente tem nos outros cursos, a descrição do dataset, das variáveis, uma elaboração que eu fiz no dataset.
E aqui, eu já deixei aqui, a Solução do problema com dependência do statsmodels, a gente vem, faz o downgrade para 1.2 e roda. Se você já tiver com isso resolvido e rodar, ele vai dizer que está tudo bem, que já está atualizado, não precisa fazer de novo. Agora, caso você esteja fazendo em outro computador ou então reinicie o Colaboratory, deslogue, coisas desse tipo, pode ser que volte a versão 1.3. Então você faz isso aqui novamente para você rodar essa aula aqui.
Então vamos lá, rapidamente, só para abrirmos esse dataset, aí depois a gente já começa rodando regressões, correlações, coisas desse tipo. Eu vou importar o Pandas, import pandas as pd, aquele padrão que a gente vem utilizando.
Vou também, já fazer o import numpy as np, também o mesmo padrão e, já aqui mesmo, eu já vou importar o Seaborn, então import seaborn, que é uma biblioteca de gráficos estatísticos, as sns.
import pandas as pd
import numpy as np
import seaborn as sns
Não vamos entrar muito a fundo no Seaborn, é só para fazermos algumas visualizações e entendermos, mas eu já vou deixar tudo desenhando, pronto, para você.
Como fizemos nos outros cursos, vamos ler o dataset que está aqui dentro desse arquivo csv e vamos colocá-lo dentro de um dataframe, como?
Vou chamar de dados esse data frame e vou fazer o quê? Chamar o pandas, “pd.read_csv”. Nesse caso aqui, o dataset é bem limpinho já, você só precisa fazer isso, “dados.csv”, ele já resolve aqui pra gente.
dados = pd.read_csv('dados.csv')
Ele já leu, amos fazer uma pequena visualização aqui das cinco primeiras linhas com o head(), o nosso dataset está aí.
| | UF | Sexo | Idade | Cor | Anos de Estudo | Renda | Altura | | -------- | -------- | -------- || | | | | | 0 |11 | 0 | 23 |8 |12 | 800 | 1.603808| | 1 | 11 | 1 | 23 | 2| 12|1150 | 1.739790| | 2 | 11 | 1 | 35| 8|15 | 880| 1.760444| | 3 | 11 | 0 | 46 |2 | 6| 3500| 1.783158| | 4 | 11 | 1 | 47 |8 | 9| 150| 1.690631|
O nosso dataset já está aqui, UF, sexo, idade, cor, anos de estudo, renda e altura. O mesmo que a gente vem utilizando nos outros treinamentos.
Próximo vídeo, já vamos rodar uma regressão de ponta a ponta. Mas, vamos rodar rápido, vamos fazer só para ver como funciona o procedimento e depois, com calma, vamos falar de covariância, correlação, regressão, resíduo, como estimar, coisas desse tipo. Os testes estatísticos que já vimos no curso anterior, vamos ver também como funciona isso dentro do modelo de regressão.
Até o próximo vídeo.
Já preparamos o nosso ambiente, agora vamos começar a colocar a mão na massa e começar o nosso curso de correlação e regressão.
Como fizemos o curso anterior, onde vimos testes, eu já dei logo um susto, mostrei logo um teste no primeiro vídeo. Vou fazer a mesma coisa aqui porque você começa a pegar os macetes, começa a entender onde chegaremos no final do treinamento. Isso aqui vai ser uma coisa rápida, mas depois eu vou fazer o passo a passo com você com calma, só para ver onde vamos chegar.
Deixei aqui um dataset já confeccionado por mim mesmo para facilitar o nosso aprendizado. Eu não usar dados reais, por exemplo o nosso dataset de 2015, porque dados reais geralmente têm algum probleminha que temos que resolver, tem outlier, tem que ajustar forma funcional, transformações, coisas que vão nos fazer perder o foco do que estamos querendo aprender aqui, que é a técnica de regressão. Então vamos usar esse dado aqui, porque ele já está ajustado e arrumado só para entendermos como isso funciona.
Eu coloquei aqui dentro do dataset "Curso_de_Estatística_Parte_4.ipynb" duas variáveis, uma Y que eu estou chamando de Y, que seria uma variável dependente, e X seria minha variável explicativa. Veremos um modelo de regressão linear simples, ou seja, ele tem uma variável Y e uma variável X, onde Y é o que estou chamando de "Gasto das Famílias", e X é a "Renda das Famílias". Eu estou dizendo que o gasto das famílias é uma função da renda, é isso que eu vou tentar estimar com esse meu modelo aqui.
dataset = {
'Y': [3011, 1305, 1879, 2654, 2849, 1068, 2892, 2543, 3074, 849, 2184, 2943, 1357, 2755, 2163, 3099, 1600, 353, 1778, 740, 2129, 3302, 2412, 2683, 2515, 2395, 2292, 1000, 600, 1864, 3027, 1978, 2791, 1982, 900, 1964, 1247, 3067, 700, 1500, 3110, 2644, 1378, 2601, 501, 1292, 2125, 1431, 2260, 1770],
'X': [9714, 3728, 6062, 8845, 8378, 3338, 8507, 7947, 9915, 1632, 6825, 8918, 4100, 9184, 6180, 9997, 4500, 1069, 5925, 2466, 6083, 9712, 7780, 8383, 7185, 7483, 7640, 2100, 2000, 6012, 8902, 5345, 8210, 5662, 2700, 6546, 2900, 9894, 1500, 5000, 8885, 8813, 3446, 7881, 1164, 3401, 6641, 3329, 6648, 4800]
} Rodando isso aqui, que já está pronto para você também rodar, você não precisa digitar esses números todos, eu vou passar esse cara para um data frame, fica mais fácil de eu trabalhar, eu vou chamar de dataset mesmo. Chamo pandas, pd.DataFrame, e aí eu passo o dataset. Só para a visualizarmos ele aqui, vamos fazer um .head() para não ficar muito grande, vamos ver só os cinco primeiros registros.
dataset = pd.DataFrame(dataset)
dataset.head()| Y | X | |
|---|---|---|
| 0 | 3011 | 9714 |
| 1 | 1305 | 3728 |
| 2 | 1879 | 6062 |
| 3 | 2654 | 8845 |
| 4 | 2849 | 8378 |
Está aqui já, com Y e X, essa variável que vamos usar. Vamos fazer um shape dele aqui, dataset.shape, para vermos as dimensões.
(50, 2)
Já sabemos que ele tem duas variáveis e tem 50 observações, 50 registros, esse é o dado que eu tenho pra mostrar para vocês. A primeira coisa em um processamento de regressão é, geralmente, visualizar as estatísticas descritivas. Estamos começando a trabalhar com dado, não temos familiaridade com esse dado ainda, então precisamos entender como esse dado está se comportando.
Então, em dataset.describe temos um ferramental aqui do Pandas para plotar para nós algumas estatísticas descritivas dos dados, tanto de Y quanto de X.
dataset.describe()| Y | X | |
|---|---|---|
| cont | 50.000000 | 50.000000 |
| mean | 2011.120000 | 6065.500000 |
| std | 817.214648 | 2707.187812 |
| min | 353.000000 | 1069.000000 |
| 25% | 1362.250000 | 3516.500000 |
| 50% | 2127.000000 | 6363.000000 |
| 75% | 2675.750000 | 8381.750000 |
| max | 3302.000000 | 9997.000000 |
Aqui é a média, ou a contagem que a gente de fazer lá em cima, desvio padrão, mínimo e máximo, e temos quartis. O primeiro, a mediana e o terceiro quartil. Para visualizarmos, ver como é que está funcionar, se eu existe algum outlier, algum tratamento que eu precise fazer. Aqui, como o dado é comportado, não vamos passar por essa etapa.
As análises gráficas que eu vou mostrar aqui, eu já vou deixar pronto pra gente não ter que ficar digitando isso tudo no nosso treinamento, porque o nosso foco não é seaborn, é o procedimento de regressão.
Mas está aqui, eu chamo de ax por conta das documentações virem sempre com esse ax, então eu estou deixando para ficar mais fácil de você entender a documentação, se você quiser consultar está no "Curso_de_Estatística_Parte_4.ipynb" a documentação.
ax = sns.boxplot(data=dataset, orient='h', width=0.5)
ax.figure.set_size_inches(12, 6)
ax.set_title('Box plot', fontsize=20)
ax.set_xlabel('Reais (R$)', fontsize=16)
ax Já importamos o seaborn na aula anterior, ele está aqui, seaborn as sns, então aqui eu faço um boxplot com as duas informações, o Y e o X, eu passo para ele o data falando que a orientação dele é horizontal, e estou dando um tamanho para ele de 0.5. Aqui eu estou determinado tamanho da imagem, nessa segunda linha, o tamanho que eu quero mostrar aqui no notebook, e aqui estou citando o título e o label do eixo X. Depois, só no final, eu ploto ele aqui.
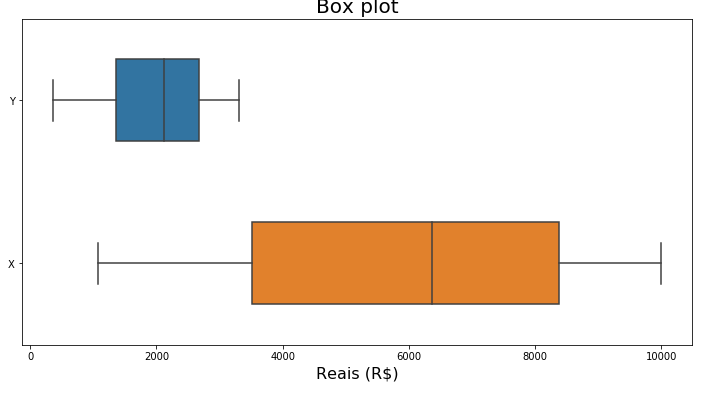
Está ele aqui, o nosso Box plot, só para termos uma noção de como ele está se comportando com o dado, aqui em cima Y, como você pode ver aqui em cima, e o X aqui embaixo. A gente vê que não têm valores discrepantes, não têm aqueles pontinhos fora, nem para um lado, nem para o outro, o comportamento dos dois tão bem diferente, o gasto obviamente é menor do que a renda, deveria ser assim.
E aqui embaixo, eu vou plotar usando lmplot, também um ferramental do seaborn.
ax = sns.lmplot(x="X", y="Y", data=dataset)
ax.fig.set_size_inches(12, 6)
ax.fig.suptitle('Reta de Regressão - Gasto X Renda', fontsize=16, y=1.02)
ax.set_xlabels("Renda das Famílias", fontsize=14)
ax.set_ylabels("Gasto das Famílias", fontsize=14)
axA mesma coisa aqui, eu ploto no parâmetro X, eu vou dar minha variável X, no parâmetro Y, o Y, eu passo para ele o dataset, que tem essas duas variáveis, aqui eu configuro o tamanho da imagem, e aqui eu faço configurações nos labels e no título. Aqui a gente pode ver os dados, são os pontinhos, e essa reta seria uma estimação de uma reta de regressão, que é o que a gente vai aprender como fazer. Isso aqui o próprio seaborn já mostra para a gente, a gente vai justamente procurar estimar essa reta aqui.
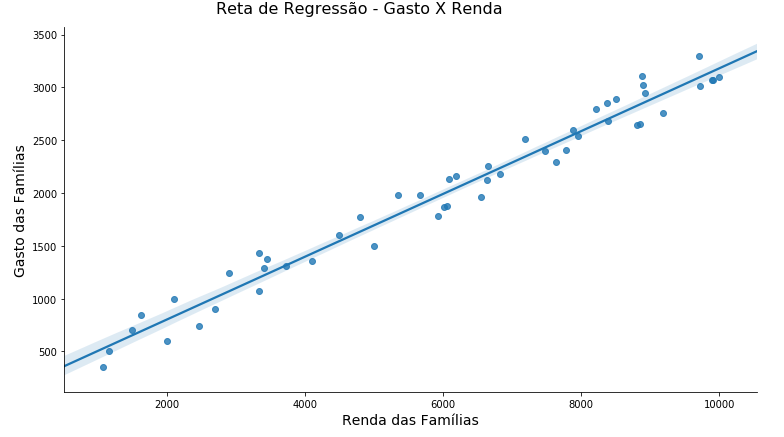
Continuando, o próximo passo em um procedimento desse tipo seria uma análise de correlação para ver se existe uma relação linear entre duas variáveis. A gente está rodando regressão linear, a gente precisa de uma relação linear entre elas. Então, vamos lá: dataset.corr, isso também é tudo ferramental do Pandas, ele já joga pra gente uma matriz de correlação.
dataset.corr()| Y | X | |
|---|---|---|
| Y | 1.000000 | 0.984835 |
| X | 0.984835 | 1.000000 |
A gente vai entender o que é isso aqui, como interpretar, como funciona, mas eu já posso adiantar para você que esse é um número que vai de -1 a 1, sendo que esses sistemas indicam uma forte relação linear entre duas variáveis, ou para um lado, ou para o outro. Aqui a gente pode ver que ele está com 0.98, o ponto 1 aqui é justamente a correlação entre a variável e ela mesmo, ou seja, perfeita. E aqui não, a relação entre essas duas é de 0.98, uma relação bastante forte linear, como a gente pode verificar no próprio gráfico que plotamos.
Continuando, vamos agora estimar o modelo de regressão, e aqui entra aquele cara que a gente importou, import statsmodels.api, eu vou dar um apelido como eu venho dando aqui, sm, de stats models. Aqui é justamente aquele cara que a gente fez aquele downgrade do SciPy, para consertar e poder rodar esse cara. Então, se você teve aquele problema, volta no vídeo anterior e dá uma olhada em como a gente faz isso.
import statsmodels.api as sm Se você não tem um problema, segue em frente, não precisa fazer. Chamamos ele, a gente tem um sm agora, eu vou criar duas variáveis para passar para essa funcionalidade do statsmodel que vai rodar nessa regressão, um eu vou chamar de Y mesmo, e vou passar o nosso dataset.Y, que é a variável Y do dataset. A outra vai ser uma variável X, e a gente já vai entender o porquê dessa construção aqui, quando a gente for aprendendo com mais detalhes. Eu vou chamar sm.add_constant, e eu passo o X. Esse add_constant eu já vou mostrar aqui.
Y = dataset.Y
X = sm.add_constant(dataset.X)Criou as duas variáveis, isso daqui é um warning futuro, uma coisa que vai deixar de existir, depois, se for necessário, a gente faz um vídeo para consertar alguma coisa que venha a ficar errado, um treinamento, mas isso daqui a gente não precisa se preocupar agora.
O que eu vou fazer é, eu vou mostrar o Y para você ter uma ideia do que ele criou, ele criou aquela série com os valores de Y.
Y.head()0 3011
1 1305
2 1879
3 2654
4 2849
Name: Y, dtype: int64
E o X cria pra gente um dataframe com a constante, e é por isso que eu fiz esse add_constant, ele cria uma variável chamada de const constante, e ela é um monte de números 1, é uma constante 1. A gente vai entender o porquê disso quando a gente for explicando melhor com calma, não se preocupe.
X.head()| const | X | |
|---|---|---|
| 0 | 1.0 | 9714 |
| 1 | 1.0 | 3728 |
| 2 | 1.0 | 6062 |
| 3 | 1.0 | 8845 |
| 4 | 1.0 | 8378 |
É um procedimento necessário que o statsmodel precisa, mas a gente vai com calma entender o porquê disso aqui. E aqui a minha variável X. Como eu faço para estimar o modelo agora? Eu vou chamar de resultado o que é um objeto aqui com o resultado dessa minha estimação, resultado_regressao, sem acento, e vou fazer o seguinte: sm.OLS, uma estimação de mínimos quadrados ordinários, e vou passar para ele o Y, que a gente acabou de criar, e o X; existem alguns parâmetros aqui, mas a gente não vai precisar usar eles agora. .fit, e aqui a gente já consegue rodar o modelo de revisão.
resultado_regressao = sm.OLS(Y, X).fit() Ele rodou, não aparece nada, ele criou e rodou essa regressão com essas variáveis, e colocou dentro desse objeto aqui, resultado_regressao. O que a gente vai fazer agora é verificar esse resultado, fazendo regressao.summary, e aqui ele te dá o resultado de uma regressão.
Eu vou plotar aqui com um print, porque fica mais legível e talvez alguém que não queira, ou não esteja usando o Collab, também vai precisar fazer desse jeito, se não você não vai visualizar. Ficou um pouco mais legível, é o mesmo resultado, e aqui temos todos os parâmetros que foram estimados. Lembre, estimação a gente já viu, isso aqui é justamente uma estimação. Aqui, o intervalo de confiança dessa estimação, a gente também já viu.
print(resultado_regressao.summary())Esses carinhas aqui, esse t e esse P>|t|, o p valor é esse aqui. Esse t é a estatística de teste, ou seja, isso aqui é um teste de hipótese, isso aqui em cima também é um teste de hipótese, no F aqui. A gente vai falar deles com calma, um de cada vez. Aqui o R-quadrado da regressão, você já deve ter ouvido falar R-quadrado, vamos falar devagar também, o quadrado ajustado.
Enfim, eu vou focar nesses mais importantes, que são mais pedidos, precisamos dedicar mais o estudo a eles porque estão sempre nos perseguindo quando a gente está estimando um modelo de regressão, e precisamos entender o que está acontecendo aqui. Você já tem bagagem para isso, a gente já viu o teste de posse, a gente já viu estimação, então você vai entender isso daqui muito fácil. Mas eu vou mostrar o passo a passo correto para você.
O passo final seria, além de você depois fazer análise do resíduo e outras coisas, mas é obter previsões aqui mesmo, dentro dessa amostra, pra gente tentar ver se essas previsões estão de acordo. Então, eu faço o que? dataset, e eu vou criar uma variável dentro do meu dataset, e eu vou chamar ela de y_previsto, e aí sim eu passo o resultado da regressão, que é aquele objeto que tem o resultado do meu ajuste, e passo .predict.
dataset['Y_previsto'] = resultado_regressao.predict()
datasetE aqui a gente pode visualizar o dataset, ele vai ter uma variável nova, que é a previsão dentro da minha amostra. Eu posso usar essa ferramenta para fazer previsões fora da amostra, o que é muito interessante, que é justamente o que a gente quer, fazer uma modelagem e fazer previsões para ele.
Aqui são para a gente verificar como é que está sendo o ajuste do nosso modelo, esse aqui é o nosso Y, esse aqui o nosso Y previsto com o nosso modelo. Alguns saem muito do ponto, outros saem menos. Depois a gente vai estudar os erros, falar de resíduos, falar de um monte de outras coisas.
O próximo passo, a gente chegou a esse ponto e a gente vai iniciar falando de correlação, mas isso a gente vê no próximo vídeo. Até lá!
O curso Estatística com Python: Correlação e Regressão possui 182 minutos de vídeos, em um total de 57 atividades. Gostou? Conheça nossos outros cursos de Estatística em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






