


Olá, pessoal! Eu sou Guilherme Silveira. Neste primeiro curso de Kafka, vamos aprender muitas coisas. Vamos entender o que é mensageria, como funciona e as características especiais de Kafka.
Audiodescrição: Guilherme é uma pessoa de pele clara, cabelos castanhos, curtos e ondulados. Olhos castanhos. Está vestindo uma camiseta branca.
Vamos analisar os diferenciais de Kafka em relação a outros sistemas de mensageria e entender porque o sistema de streams (fluxos) consegue, de uma maneira inteligente e interessante, paralelizar e distribuir o nosso processamento em diversos serviços e sistemas, e, ao mesmo tempo, serializá-lo quando for necessário e interessante para nós.
Vamos aprender como funcionam as partições, os tópicos, e o broker em execução. Além de criar diversos consumidores, grupos de consumidores, paralelizar e executá-los em paralelo.
Também executar produtores que geram diversas mensagens que são consumidas e que geram feedback, para entender como um sistema tradicional pode ser dividido em vários serviços de uma forma que utilize uma comunicação através de mensagens em que adquirimos certas independências entre os sistemas.
O sistema não é completamente independente, pois existe um esquema que tenta colar o que está acontecendo e a semântica das mensagens, que também é importante. Vamos entender como tudo isso se conecta dentro do Kafka e colocar em prática.
Então, vamos produzir o código, levantar servidor, derrubar servidor, acompanhar o que acontece quando está ativo, quando está inativo, quando está caído, seja o serviço, seja o produtor, seja o broker da Kafka. Enfim, vamos explorar tudo isso durante o curso.
Vamos começar?!
Imagine um sistema de e-commerce. Nesse sistema, teremos uma pessoa usuária acessando o sistema online. Portanto, dentro do perfil de usuários, temos o navegador, que vamos referir como usuário. No OmniGraffle, vamos criar um retângulo e escrever:
navegador (usuário)
O cliente, através do navegador, acessa a web e, por meio dela, um servidor HTTP. Em outro retângulo, escreveremos:
servidor http
O acesso a esse servidor é feito e funciona. Para representar esse acesso, vamos desenhar uma seta do retângulo de "navegador (usuário)" para "servidor http" (esquerda para direita).
O servidor HTTP precisa realizar diversas tarefas, porque está envolvido em um processo de compra. A pessoa usuária está efetuando uma compra. Portanto, nós precisamos verificar se é uma fraude. Antes de verificar se é uma fraude, temos que enviar um e-mail informando que a compra está sendo processada. Caso seja identificada uma fraude, notificamos sistemas de segurança.
Sendo assim, complementamos o texto do retângulo de "servidor http":
servidor http
email, fraude? Notifico sistemas de segurança.
Se não for fraude, precisamos efetuar a compra e o pagamento. Se o pagamento for bem-sucedido, precisamos liberar o produto:
servidor http
email, fraude? Notifico sistemas de segurança. Compra/pagamento. Liberar.
Por exemplo, se é um produto online, como um e-book, precisamos gerar o e-book com a versão personalizada para aquela pessoa usuária, que contenha o nome da pessoa, o CPF, etc. E, finalmente, enviamos o produto para o e-mail.
Portanto, perceba que vai ficando cada vez mais complexo, com um passo após o outro. Vamos separar isso com setas e quadrados para facilitar a visualização. O servidor envia um e-mail. Nós poderíamos verificar a fraude após o e-mail e colocar todo esse código dentro de um único sistema. Funcionaria.
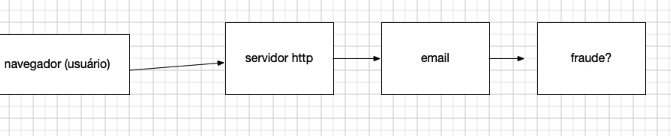
Primeiro, o servidor HTTP envia um e-mail, verifica se é fraude e segue um caminho conforme a resposta. Tudo dentro de um grande programa, uma linha após a outra. Um problema direto para os sistemas é que, por exemplo, esperar o e-mail significa esperar a resposta de um sistema externo: o servidor SMTP, que envia e-mails.
Pode ser que esse servidor esteja fora do ar ou lento. Portanto, vamos demorar para iniciar o processo de detecção de fraude, porque estamos esperando o e-mail. É muito comum que em sistemas web queiramos dar uma resposta para a pessoa usuária o mais rápido possível. Por isso, é muito comum que esse tipo de tarefa seja feita em paralelo.
Então, disparamos o e-mail e o sistema de verificação de fraude ao mesmo tempo. Quer dizer que podemos ter no mesmo computador duas threads (linhas de execução). Ou pode ser que estejamos nos comunicando com dois computadores diferentes e indicando que um deles envie um e-mail, uma requisição HTTP, via REST, ou algo do tipo.
Enquanto isso, já fornecemos uma resposta para nossa pessoa cliente dizendo "sua compra está sendo processada". E, então, vamos processando tudo isso em paralelo, na mesma máquina ou em máquinas distintas. São várias as opções.
Essa comunicação pode ser feita via HTTP, via REST, ou outro tipo de mensageria. O tradicional seria utilizar primeiro a mesma máquina com várias threads e depois máquinas distintas, se comunicando via HTTP.
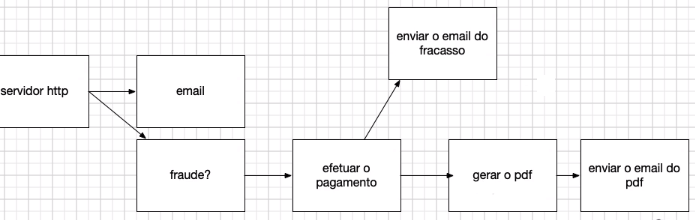
Vamos prosseguir agora com esse sistema, levando em conta os apontamentos realizados agora. Independentemente de ser fraude ou não, precisamos fazer algo. Por exemplo, se não for fraude, temos que realizar o pagamento.
Depois de efetuar o pagamento, precisamos preparar o envio. Vamos pensar em um bem digital, como um PDF, um e-book. Nesse caso, teríamos que gerar o PDF. E, por fim, teríamos que enviar o e-mail do PDF.
Esta parte parece sequencial, porque não vamos gerar o PDF antes de efetuar o pagamento. Ou, pelo menos, não vamos enviar o e-mail antes de confirmar o pagamento. Agora temos várias setas: uma seta da detecção de fraude para a próxima etapa; do sistema de efetuar pagamento para gerar o PDF. E assim sucessivamente.
Isso é no caso de sucesso, onde efetuamos o pagamento. E no caso de falha? Também gostaríamos de enviar um e-mail.
Além disso, gostaríamos de ter suporte para produtos físicos. Portanto, se é um produto físico, temos estoque. E quando a pessoa solicita a compra, já precisamos reservar esse produto. Portanto, logo de início, precisamos reservar o estoque.
Temos três serviços diferentes, cada um rodando em uma máquina diferente. Três requisições HTTPs. Uma requisição HTTP, outra requisição, outra, e assim por diante.
A compra foi confirmada, efetuamos o pagamento. Se ela for digital, o que precisamos fazer? Precisamos confirmar o estoque. Reservamos, agora precisamos confirmar o estoque. E se houve uma falha, possivelmente cancelaremos o estoque. Só se for um produto físico.
Está ficando cada vez mais complexo. Podemos dizer que temos:
Mas todas essas comunicações, essas setas, somos nós quem programamos. Nós fazemos todas elas. Nós sabemos quem está na outra ponta e enviamos uma mensagem HTTP — podemos definir outro termo, de acordo com como essa requisição é feita — notificando o que gostaríamos que fosse feito, ou algo do gênero.
Vamos complicar mais ainda, como no mundo real. Para tudo isso, precisamos de log. Portanto, toda vez que dispararmos um e-mail, precisamos registrar em algum lugar que um e-mail foi disparado, isto é, precisamos de um sistema de log ou algum registro. Então, tudo que acontece deve ir para o sistema de log.
Se quisermos fazer uma auditoria, saber a ordem em que aconteceram as coisas ou algo do gênero, as informações devem ir para o sistema de log. Nem terminamos o sistema e já há tantas setas ligando todos os retângulos ao retângulo de "log" que não é possível entender nada. O motivo é que vários sistemas conhecem vários sistemas, gerando um emaranhado de passos.
Além do log, existem outros concerns (preocupações) que transpassam nossa aplicação inteira, que são os cross-cutting concerns (preocupações transversais). Por exemplo, os dados com analytics (análise). Precisamos saber como estamos em termos de fraude.
Vamos supor que estamos com 10%. Este valor é a nossa média histórica. Se hoje está 20%, então algo aconteceu com o nosso sistema de fraude ou com as pessoas que cometem fraude. Então, há algo estranho com o sistema, ou realmente as pessoas que cometem fraude estão fazendo um ataque, tentando fraudar o meu sistema.
Precisamos de um analytics para acompanhar as métricas, para saber se tem algo fora do ar, se tem algo que não está dando conta, se tem algo que começou a dar mais erro do que o comum. Precisamos ter controle não só das fraudes, mas também do pagamento.
A taxa de pagamento está como a taxa histórica de sucesso? A taxa de e-mails que são enviados com sucesso, que não dão bounce, que não batem e voltam, estão com taxa normal ou batendo e voltando mais? Ou seja, os servidores de e-mails estão considerando que nossos e-mails são spams. Tudo isso envolve Analytics.
Os arquivos PDF estão sendo gerados no ritmo esperado ou não? Estamos gerando muito mais? Deu algum bug e entrou num loop infinito. Ou não, estamos gerando vendas a menos, ou o sistema está lento e está acumulando arquivos PDF a serem gerados. Tudo envolve análise.
A implementação não é simples. Se o sistema de detecção de fraude falha, onde anotamos para notificar o Analytics daqui a um tempo? Para isso, existem sistemas de polling, de watchers, de observers. São várias estruturas complexas que nos ajudam a lidar com a dificuldade do processo interno.
O que antes era sequencial, passou a ser paralelo com o fim de potencializarmos o desempenho de nossa aplicação. Sendo assim, podemos executar 10 máquinas de detecção de fraude e somente uma de e-mail. Caso a efetuação de pagamentos também demandar muitos recursos, podemos contar com 5 máquinas.
Assim, conseguimos dimensionar cada um desses serviços com máquinas distintas, com a vantagem de ter tudo distribuído e “paralelizado”. Perceba a complexidade que é trabalhar com esse tipo de sistema. Existem sistemas e formas de trabalhar mais inteligentes ou, pelo menos, diferentes, que podem trazer certas vantagens nessas abordagens.
Vamos copiar todo o sistema que construímos e colar embaixo. A ideia é repensar todas as conexões (setas). Por exemplo, quando a pessoa usuária (poderia ser um aplicativo) acessa o servidor HTTP, o servidor recebe um pedido de compra. Então, ele simplesmente envia uma mensagem que se chama "novo pedido de compra".
Então, precisamos representar o broker (corretor), que é quem recebe mensagens. Assim, simplesmente enviamos uma mensagem para o broker e especificamos que ela é de nova compra, por exemplo. Não sabemos quem vai recebê-la e não importa, porque o e-mail disparado, quando há um novo pedido de compra, está captando a mensagem, cujo assunto é a nova compra.
O tema de "fraude", também está captando, assim como o "reservar o estoque", o "analytics" e o "log". O servidor HTTP sabe algo sobre isso? A resposta é não. Ele simplesmente envia uma mensagem avisando que há um novo pedido de compra e mostra as informações. Todos os temas estão captando o tópico "broker" e cada um realizará sua tarefa de forma assíncrona, na mesma máquina ou em máquinas distribuídas.
Então, para simplificar, nem precisamos adicionar as setas. Basta dizer que o serviço que está rodando em uma máquina, capta o tema "nova compra". O sistema de detecção de fraude, o sistema de reserva de estoque, o analytics e o log estão captando a nova compra.
Quando o e-mail é enviado, 'o serviço de e-mail, envia uma mensagem para o broker avisando que sua parte foi finalizada: enviar um e-mail. Tanto o log, quanto o analytics estão captando o e-mail enviado. Se não há fraude, vamos querer validar o pagamento.
O "fraude" envia a mensagem: "compra sem fraude". Captam esse tópico o "log" e o "analytics". Da maneira que estamos projetando os sistemas, indicamos que não importa quem captará a atualização de status, uma situação que ocorreu no sistema. Ocorreu um pedido de nova compra, um e-mail enviado e a compra foi validada sem fraude.
Além disso, o pagamento foi efetuado com sucesso e o PDF foi gerado. Quem está captando isso para agir não me importa. Esse é o conceito de mensageria. O conceito de mensageria, de troca de mensagens, aparece em diversos sistemas e implementações. O Kafka tem certos recursos, alguns comuns à mensageria e outros especiais, particulares dele.
Um dos recursos de mensageria é a possibilidade de ter rodando a quantidade de servidores e serviços de e-mail que quisermos. É como funcionava com o próprio HTTP. Se o sistema de fraude é um sistema que consome muita CPU e pouca memória, podemos ter várias máquinas com CPUs potentes rodando.
Se o sistema de gerar PDF consome pouco CPU, mas muita memória, podemos ter algumas máquinas com CPU mediano e bastante memória. É possível escalar de acordo com o necessário. Além disso, eliminamos um ponto de falha: se tivéssemos apenas uma máquina rodando e ela caísse, seria problemático. Se temos 10 máquinas rodando e uma cai, ainda temos 9. Desta maneira, vamos eliminando os pontos de falha.
O broker também pode ser replicado. Não é necessário ter um único broker rodando. Podemos ter um cluster de brokers, por exemplo, um cluster com 3 ou 30 brokers rodando 30 instâncias do Kafka. Quando enviamos uma mensagem, ela vai parar possivelmente em mais de um broker. Se um deles desligar, o outro receberá essa mensagem.
Se mandamos uma mensagem qualquer e ela fica armazenada em 3 máquinas, até ser recebida por quem quiser, caso uma delas cair, as outras duas ainda guardarão a mensagem. Assim, ganhamos mais reliability (confiabilidade), garantindo que as informações serão recebidas.
Mais que isso, conseguimos rodar em paralelo, como estamos fazendo. Os dados das mensagens que chegam são distribuídos para várias instâncias do detector de fraudes. Por exemplo, se recebermos 5 mensagens de novas compras, podemos enviar 2 para uma instância, 2 para outra e 1 para a terceira. Isso é possível caso tenhamos 3 instâncias de detecção de fraude.
Podemos, automaticamente, lidar com eventuais problemas do sistema. Por exemplo, se os sistemas de detecção de fraude caírem e só voltarem a funcionar no dia seguinte, não há problema. As mensagens ficam armazenadas e conseguimos executá-las um dia depois, sem maiores dificuldades.
Se por algum motivo as 10 máquinas falharem, conseguimos armazenar essa mensagem por um tempo configurável. Podemos configurar um tempo ou a quantidade de espaço em disco que queremos reservar para armazenar as mensagens sem problemas.
Podemos também definir, por exemplo, que se a compra de uma pessoa usuária foi identificada como fraude, as outras compras dessa mesma pessoa não serão executadas. Isso poderia ser uma configuração do sistema.
Mesmo que o Kafka permita a execução em paralelo, em determinados momentos, podemos definir que as compras para um usuário específico ou a mensagem de geração de PDF, seja processada em sequência.
Isso porque, se uma pessoa usuária comprou mil PDFs, não queremos que todos sejam gerados ao mesmo tempo, fazendo com que outras pessoas usuárias tenham que esperar. É preferível gerar um PDF para cada pessoa usuária. Assim, todas estarão lendo algo e ninguém ficará esperando.
Podemos, portanto, definir regras do tipo: mesmo desejando paralelização, quando pensamos em uma pessoa usuária, queremos que as ações referentes a ela sejam executadas em sequência.
Por exemplo, a reserva de estoque pode ser executada em paralelo, mas para um produto específico, provavelmente queremos que a reserva seja feita em sequência. Para o produto 5, por exemplo, queremos retirar do estoque em sequência. Mas para o produto 5 e para o produto 15, podemos processar em duas máquinas em paralelo, sem problemas.
Poderíamos usar o produto como chave para serializar a execução, ou seja, deixar em sequência. O Kafka é capaz de fazer tudo isso e nós vamos explorar essas capacidades nos cursos de Kafka da Alura.
Olá, pessoal! Neste vídeo, vamos aprender a instalar o Kafka e darei um primeiro exemplo via terminal, para visualizarmos tudo configurado corretamente.
Primeiramente, vamos acessar o site Apache Kafka, vamos acessar a área de "download" e baixar a última versão, 2.3.1, com uma versão mais recente de Scala, que é a 2.12. Esse é o TGZ que vamos baixar.
Após baixar o TGZ, vamos descompactá-lo, dar dois cliques, usar o terminal que preferir. No terminal, visualizaremos um problema muito comum quando executamos o Kafka.
Estamos dentro do diretório anterior, vamos entrar no diretório, acessar o Kafka no diretório de download, descompactar e acessar o diretório do kafka. Note que deixaremos um espaço entre apps\ e descompactadas/ proposital:
apps\ descompactadas/
tar zxf ../download/kafla_2.12-2.3.1.tgz
kafka_2.12-2.3.1/
pwd
/Users/alura/Documents/guilhermesilveira/1552-kafka1/apps descompactadas/kafka_2.12-2.3.1
No diretório do Kafka, encontraremos mais diretórios: o de scripts (bin) e o de configurações (config). Vamos acessar o diretório de scrips do Java com a configuração padrão de servidor:
bin/kafka-server-start.sh config/server.properties
Quando tentamos rodar, ele nos envia uma série de erros.
bin/kafka-server-start.sh config/server.properties
usage: dirname path
usage: dirname path
usage: dirname path
usage: dirname path
Classpath is empty. Please build the project first
// Retorno omitido.
O erro nos conduz a pensar que o projeto não está construído, mas não é isso. Mas não baixamos o código fonte, mas, sim, a versão binária, com o projeto já construído, pronto para executar.
O problema, na verdade, está no diretório path que estamos utilizando. Há um espaço entre \apps e descompactadas/. Então, o diretório que antes se chamava apps descompactadas agora se chamará apenas apps. Feita a mudança, podemos retornar ao Kafka e codar:
bin/kafka-server-start.sh config/server.properties
Tentamos executar, ele roda o Java 13 que já está instalado, mas aponta vários erros e desliga. Por quê? Porque o Kafka é o processador dessas mensagens, no sentido de conectar tudo. Mas, onde ele armazena essas informações? O Kafka armazena algumas informações básicas no Zookeeper. Então, vamos baixar o zookeeper, acessando Apache ZooKeeper.
Lembrando que Kafka já vem com o Zookeeper instalado, caso você não queira instalar separadamente. Porque pode haver empresas que já tem o Zookeeper rodando por outros motivos. No nosso caso, nós não temos. Então, antes de rodar o Kafka, vamos executar:
bin/zookeeper-server-start.sh config/zookeeper.properties
Já temos as propriedades padrão configuradas e vamos utilizá-las. Nos conectamos com 0.0.0.0/0.0.0.0, na porta 2181. O Zookeeper está rodando. Agora, sim, vamos abrir outra aba e tentar acessar o mesmo diretório:
bin/kafka-server-start.sh config/server.properties
Ele vai tentar se conectar ao Zookeeper. Ele se conecta, mostra uma série de propriedades padrão que está utilizando, e, ao final do retorno, está escrito "started". Significa que ele está rodando o Kafka em algum lugar.
O Kafka está em execução e conseguimos encontrar a porta padrão 9092, isto é, port = 9092, que está especificada em server properties. Portanto, temos a propriedade que está na porta 9092, operando o Kafka e, por trás, o Zookeeper para algumas configurações. Não para todos os dados, apenas algumas configurações.
Agora, vamos enviar uma mensagem de um lado para o outro e analisar o Kafka em funcionamento. Vamos testar no terminal outra vez e no mesmo diretório, Kafka. A ideia é criar um tópico para trocar mensagens:
bin/kafka-topics.sh
Visualizaremos tudo o que o Kafka Topics nos permite fazer e existem várias funções. O que vamos fazer é criar um tópico. Mas precisamos indicar onde o Kafka está rodando. Ele está rodando bootstrap-server, em localhost porta 9092:
bin/kafka-topics.sh --create --bootstrap-server localhost:9092
Então, estamos indicando uma conexão com o Kafka, localhost:9092, e definiremos duas propriedades padrão. Elas serão utilizadas durante todos os cursos. Portanto, não se preocupe, vamos nos aprofundar no estudo sobre elas aos poucos.
Por enquanto, vamos deixar fixos o replication factor e o partitions como 1:
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1
Também definiremos o nome do tópico. Pode ser o padrão que quiser. Imagine que temos um novo pedido chegando na nossa loja. Então, poderíamos definir como LOJA_NOVOPEDIDO ou LOJA.NOVOPEDIDO. A sugestão do Kafka Topics é não misturar ponto com underline. Por isso, não vamos misturar. Manteremos o underline como padrão, sugerindo que a loja teve um novo pedido.
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic LOJA_NOVO_PEDIDO
Será que é o melhor padrão? Não existe muito um melhor ou pior padrãoa, apenas usar ponto e underline ao mesmo tempo não é uma recomendação do Kafka. Ao tentar criar o código, recebemos um aviso de que, por limitações nas métricas dos nomes, tópicos com período, ponto ou underscore podem colidir. Portanto, a melhor maneira é usar um ou outro, mas não ambos.
Para nos certificarmos de que o tópico foi criado, passaremos:
bin/kafka-topics.sh --list --bootstrap-server localhost:9082
LOJA_NOVO_PEDIDO
Esses comandos são muito úteis no dia a dia. Vamos usar várias vezes. O retorno confirma que existe sim um tópico chamado LOJA_NOVO_PEDIDO. Podemos enviar algumas mensagens para esse tópico. No Kafka, há uma indicação de criação da partição para o tópico, especificamente a partição 0. Ou seja, só existe uma partição, e ela começa com 0. Portanto, confirmamos que o tópico realmente está lá.
Em outra aba, vamos rodar um produtor de mensagens:
bin/kafka-console-producer.sh
Também vamos informar que os brokers Kafka estão rodando no localhost:9092:
bin/kafka-console-producer.sh -- broker-list localhost:9092
Em seguida, dizemos qual é o tópico:
bin/kafka-console-producer.sh -- broker-list localhost:9092 LOJA_NOVO_PEDIDO
Quando o console-producer na linha de comando, cada linha que escrevemos corresponde a uma mensagem. Poderíamos, por exemplo, criar uma mensagem dizendo que o pedido zero teve valor de 550 reais:
bin/kafka-console-producer.sh -- broker-list localhost:9092 LOJA_NOVO_PEDIDO
pedido0, 550
Que o pedido 1 foi 330 reais e o pedido 2 foi 67213:
bin/kafka-console-producer.sh -- broker-list localhost:9092 LOJA_NOVO_PEDIDO
pedido0, 550
pedido1, 330
pedido2, 67213
Agora, vamos consumir essas mensagens. Para isso, abriremos uma nova aba e passaremos o comando:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic LOJA_NOVO_PEDIDO
Agora, surge uma pergunta. Devemos consumir a partir de quando? Desde a primeira mensagem armazenada ou a partir das mensagens que chegam agora? Se executarmos da forma como está, não recebemos nenhuma mensagem.
Vamos abrir uma nova aba e executar o comando:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic LOJA_NOVO_PEDIDO --from-beginning
Assim, estamos indicando para começar da primeira mensagem armazenada no kafka. Ele vai começar da primeira mensagem, verificar quais mensagens estão armazenadas e consumi-las.
Neste ponto, ainda não recebi nada, porque não tiveram novas mensagens. No entanto, tive três mensagens do passado que estavam armazenadas esperando alguém consumir.
Agora, vamos enviar uma nova mensagem:
bin/kafka-console-producer.sh -- broker-list localhost:9092 LOJA_NOVO_PEDIDO
pedido0, 550
pedido1, 330
pedido2, 67213
pedido3, 6423
Recebemos o "Pedido 3" nos dois consumidores. Excelente!
Vamos discutir ao longo do curso se queremos receber em todos os consumidores, apenas em um consumidor, como receber, quantas partições, quantas repetições, ter certeza de que vai receber, ter certeza de que começou desde o início, entre outros aspectos.
Mas, por enquanto, aprendemos como instalar o Kafka e como verificar os tópicos que estão lá. Vamos explorar esse tópico mais vezes, como criar um produtor que envia strings simples e um ou mais consumidores que consomem essas strings, apenas para visualizarmos funcionando.
A partir de agora, queremos executar isso com programação e entender todas as vantagens e desvantagens que teremos com o Kafka em nossos programas. Esses são nossos próximos passos!
O curso Kafka: produtores, consumidores e streams possui 183 minutos de vídeos, em um total de 38 atividades. Gostou? Conheça nossos outros cursos de Mensageria/Streams em DevOps, ou leia nossos artigos de DevOps.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
Impulsione a sua carreira com os melhores cursos e faça parte da maior comunidade tech.
1 ano de Alura
Matricule-se no plano PLUS e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Mobile, Programação, Front-end, DevOps, UX & Design, Marketing Digital, Data Science, Inovação & Gestão, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Acelere o seu aprendizado com a IA da Alura e prepare-se para o mercado internacional.
1 ano de Alura
Todos os benefícios do PLUS e mais vantagens exclusivas:
Luri é nossa inteligência artificial que tira dúvidas, dá exemplos práticos, corrige exercícios e ajuda a mergulhar ainda mais durante as aulas. Você pode conversar com a Luri até 100 mensagens por semana.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Para estudantes ultra comprometidos atingirem seu objetivo mais rápido.
1 ano de Alura
Todos os benefícios do PRO e mais vantagens exclusivas:
Mensagens ilimitadas para estudar com a Luri, a IA da Alura, disponível 24hs para tirar suas dúvidas, dar exemplos práticos, corrigir exercícios e impulsionar seus estudos.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






