Olá, pessoal! Meu nome é Guilherme Silveira, sou instrutor e fundador da Alura. Neste curso, vamos trabalhar na construção de um dashboard utilizando a ferramenta Dash.
Audiodescrição: Guilherme é uma pessoa de pele clara, olhos castanhos, cabelo escuro raspado curto. Está com uma camiseta amarela-clara estampada. Ao fundo, estúdio com iluminação degradê do azul ao rosa, plantas e estante com decorações.
A ferramenta Dash foi criada com base na ferramenta Plotly, que é uma biblioteca poderosa em Python para gerar gráficos dinâmicos. Com ela, conseguimos dar zoom, clicar, escolher uma faixa, ver os valores, entre outras funcionalidades. Essa biblioteca foi utilizada como base para criar dashboards.
Esses dashboards podem ser extremamente ricos, compostos por diversos gráficos, gráficos dinâmicos, tabelas onde conseguimos fazer filtragens, ou até mesmo formulários com os quais conseguimos interagir.
Neste curso, vamos implementar um dashboard que possui três páginas. Uma página inicial, apenas de boas-vindas; uma página onde apresentamos dois tipos de gráficos diferentes para aprendermos como criar um gráfico do Plotly e colocá-lo dentro de um dashboard.
Além disso, teremos que lidar com diversas questões de front-end, porque quando falamos sobre mostrar um dashboard, as questões que surgem não são apenas do back-end, de trazer os dados para montar o gráfico, mas também de como apresentamos isso na nossa página.
Isso envolve decidir se um gráfico ficará ao lado do outro, um em cima do outro, qual será o tamanho do grid, a proporção de um para o outro, o que acontece em uma tela pequena e em uma tela grande, entre outras questões de componentes visuais apresentados para nossos clientes dentro de um dashboard.
O código aqui, apesar de ser back-end, o código em Python que escrevemos para trabalhar com esses dados e gráficos. É extremamente importante entender cada vez mais sobre front-end, pois isso trará consequências para nossos dashboards.
A terceira página, dentro dessa solução, terá um formulário onde também faremos uma previsão, de acordo com o modelo que treinamos.
Temos um modelo treinado de previsão de doença cardíaca e, de acordo com os dados que preenchemos aqui, o modelo será executado e fornecerá sua previsão.
É um modelo simples, claro, não é um modelo do mundo real, mas os dados são dados do mundo real, utilizados de uma universidade americana, a UCI. Vamos utilizar esses dados, criar um modelo, produzir o formulário e, de acordo com o modelo, executar para esses dados e obter uma previsão.
O pré-requisito é já saber trabalhar com Python, com gráficos em Python e com pandas.
Não é necessário saber treinar um modelo de machine learning, vamos escrever o código de treino sem nos preocuparmos com o funcionamento do treino de machine learning. Esse não é o foco deste curso, mas sim utilizar o modelo.
Então, o foco será na parte de apresentar esses resultados para nossos usuários através de dashboards, usando a ferramenta Dash.
Nos vemos na próxima aula!
Olá, pessoal! Vamos começar.
Neste curso, a ideia é utilizar um conjunto de dados reais já existentes. Para isso, vamos utilizar um conjunto de dados que trabalha com doenças cardiovasculares.
Este conjunto de dados, que já foi compartilhado conosco, é da Universidade da Califórnia, Irvine. Se pesquisarmos por "UCI Machine Learning", encontraremos este conjunto de dados, que contém diversas informações. Selecionamos o conjunto de dados referente a doenças do coração (heart disease). Há um link na atividade Preparando o Ambiente com todas as informações necessárias.
Este conjunto de dados contém muitas informações sobre os dados que estão lá dentro, como tipo de dado. Temos idade, gênero, se a pessoa tem a doença ou não, qual é o tipo de doença cardiovascular ou nível, entre outras coisas. Vamos trabalhar com algumas dessas informações à medida que exploramos esses dados.
Este conjunto de dados dessa instituição já está disponibilizado e muitas pessoas ao redor do mundo o utilizam, tanto para artigos científicos quanto para fazer explorações. Este é o conjunto que queremos utilizar.
Como vamos utilizar isso no nosso Colab? Vamos começar no Google Colab, no Jupyter Notebook, onde você preferir escrever o código Python.
No Google Colab, clicamos em "Novo notebook". Em seguida, damos um nome ao notebook, neste caso, "Heart Disease" (Doença Cardíaca), e começamos a programar.
Queremos importar nosso arquivo CSV ou seja qual for o formato que queremos carregar nossos dados. É comum utilizarmos a biblioteca pandas para isso.
No caso, a faculdade UCI, já disponibiliza um código Python que carrega os dados. É comum no mundo científico ter esse tipo de pacote.
Vamos dar uma olhada no código deles, chamado uci-ml-repo. Se pesquisarmos, encontraremos o GitHub deles, que tem várias formas de utilizar, várias informações.
Na primeira página do repositório, ele indica para fazer um pip install. É exatamente isso que queremos fazer. Vamos copiar essa linha e executá-la:
!pip3 install -U ucimlrepo
Ele vai criar uma máquina no cloud do Google para poder rodar isso para nós. Então, demora um pouco na primeira vez. Ele vai instalar esse repositório, ucimlrepo.
Depois de instalado, você pode se perguntar, por que estamos usando pip3 e não pip? O pip3 indica que é Python 3. Antigamente, o pip podia ser tanto do 2 quanto do 3. Estamos tentando deixar explícito aqui que, de forma universal, queremos atualizar o ucimlrepo. No meu caso, instalou a versão 0.0.3. Se instalar uma versão mais recente, melhor ainda, não tem problema. O retorno foi:
Collecting ucimlrepo
Downloading ucimlrepo-0.0.3-py3-none-any.whl (7.0 kB)
Installing collected packages: ucimlrepo
Successfully installed ucimlrepo-0.0.3
O que vamos fazer depois disso? Vamos ao código que ele mostra dentro da página do UCI Machine Learning para heart disease.
Se você procurar, em algum lugar, à direita, tem o botão "Importar o código em Python" (Import in Python). Clicamos e ele tem tanto o código de pip install quanto um exemplo de código. Vamos copiar o exemplo de código inteiro e colar na nossa segunda célula da doença cardíaca.
from ucimlrepo import fetch_ucirepo
# fetch dataset
heart_disease = fetch_ucirepo(id=45)
# data (as pandas dataframes)
X = heart_disease.data.features
y = heart_disease.data.targets
# metadata
print(heart_disease.metadata)
# variable information
print(heart_disease.variables)
Neste bloco de código, primeiro ele importa o pacote, from ucimlrepo, importa o fetch_ucirepo, ou seja, ele vai buscar o repositório. E ele busca o heart_disease para nós.
Ele busca o x, que são as variáveis que vamos trabalhar, e y, que é o nosso alvo. Não vamos utilizar isso por enquanto, podemos apagar essas linhas. Só queremos o heart_disease mesmo. Repare como é muito simples para nós carregarmos, e ele imprime tanto metadados quanto as variáveis.
Vamos ver um por vez desses elementos. Então, vamos deixar só o fetch, e vamos colocar heart disease.variables para ver as variáveis.
from ucimlrepo import fetch_ucirepo
# fetch dataset
heart_disease = fetch_ucirepo(id=45)
heart_disease.variables
Podemos executar com "Shift + Enter". Temos as variáveis, a variável age, que é a idade, a variável sex, que é o sexo biológico, a variável cp, a variável trestbps, chol, etc. Tem uma pequena descrição de algumas delas. Descrições maiores estão naquela outra página que vimos antes.
Agora temos as variáveis. O que mais?
Na célula seguinte podemos escrever:
dados = heart disease.data.features
Que são as variáveis que estamos trabalhando, exceto o alvo, exceto aquela que diz se é ou não é doença. Vamos chamar isso de dados, e vamos imprimir dados.head para ver os primeiros dados que temos. Temos idade 63, o sexo biológico está com 1's e 0's, e diversas outras variáveis que podemos explorar.
dados = heart disease.data.features
dados.head()
| age | sex | cp | trestbps | chol | fbs | restecg | thalach | exang | oldpeak | slope | ca | thal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 63 | 1 | 1 | 145 | 233 | 1 | 2 | 150 | 0 | 2.3 | 3 | 0.0 | 6.0 |
| 1 | 67 | 1 | 4 | 160 | 286 | 0 | 2 | 108 | 1 | 1.5 | 2 | 3.0 | 3.0 |
| 2 | 67 | 1 | 4 | 120 | 229 | 0 | 2 | 129 | 1 | 2.6 | 2 | 2.0 | 7.0 |
| 3 | 37 | 1 | 3 | 130 | 250 | 0 | 0 | 187 | 0 | 3.5 | 3 | 0.0 | 3.0 |
| 4 | 41 | 0 | 2 | 130 | 204 | 0 | 2 | 172 | 0 | 1.4 | 1 | 0.0 | 3.0 |
O que queremos ver primeiro? Sabemos que tem idade. Vamos ver a distribuição dessa idade? Uma forma tradicional de ver a distribuição é um histograma. Temos pessoas com diversas idades. Queremos ver o histograma desses dados.
Tradicionalmente, usamos ferramentas como Matplotlib, antes de entrarmos no Plotly, e começarmos a rodar isso na web, através de um servidor, que é o nosso objetivo.
Então, importamos Matplotlib.pyplot como plt. E aí, o que vamos fazer? plt.hist, qual é o que queremos mostrar? É dados na coluna age.
import matplotlib.pyplot as plt
plt.hist(dados["age"])
Vamos pressionar "Shift + Enter" para rodar. E aí, temos um plot, mais ou menos, das nossas idades, das faixas etárias. Vemos que tem uma concentração aí entre 55, 60, algo assim. Podemos refinar esse gráfico. Vamos dar uma refinada simples nele. Vamos colocar aqui que queremos 30 caixinhas. Ficou mais distribuído em intervalos menores de idade. Então, dá para ver claramente que, realmente, lá pelos 58, algo assim, parece muito essa idade.
Vamos melhorar um pouco mais esse plot, só vamos mudar um título, plt.title, "Distribuição Etária". E plt.xlabel, no eixo x, temos a idade, e no eixo y, temos a frequência, a quantidade. Por fim, vamos mandar um show para que ele não mostre essas idades dos finais, e temos o gráfico que queríamos, um plot razoável.
import matplotlib.pyplot as plt
plt.hist(dados["age"], bins=30)
plt.title("Distribuição etária")
plt.xlabel("Idade")
plt.ylabel("Frequência")
plt.show()
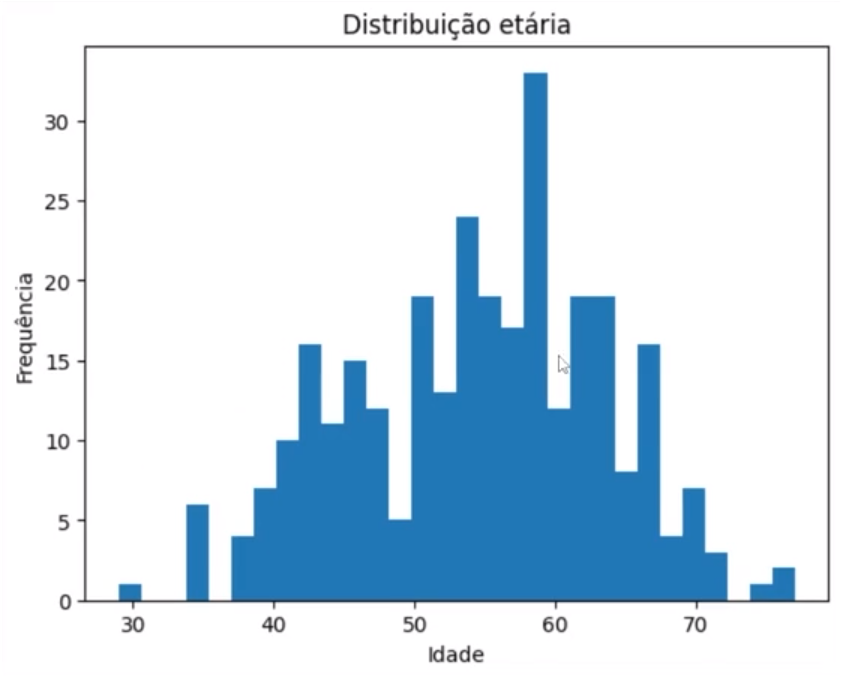
Uma última coisa, acho que essas barras sem as linhas ficam meio estranhas, então, vou colocar aqui um edgecolor, que é a cor das bordas, vamos colocar black, para ter borda preta entre as barras.
import matplotlib.pyplot as plt
plt.hist(dados["age"], bins=30, edgecolor="black")
plt.title("Distribuição etária")
plt.xlabel("Idade")
plt.ylabel("Frequência")
plt.show()
Agora temos um plot tradicional de histograma, mas não só isso, queremos ver outros tipos de gráficos. Então, vamos trabalhar com outro tipo de gráfico e outra ferramenta, vamos explorando várias ferramentas até chegarmos no Plotly e no Dash, que é o que queremos chegar.
O que queremos fazer agora?
Queremos mostrar as doenças. Vamos lá no ucimlrepo, e vemos as variáveis, tem a tabela de variáveis, e se explorarmos todas as variáveis, vamos ver que temos diversas variáveis, e no final, a nossa variável alvo, que é a variável target, é a de diagnóstico, se tem ou não tem doença.
Vamos dar uma olhada na variável alvo? Vamos ao nosso notebook, digitamos heartDisease.data.targets. Nessa coluna terão valores como 1, 2 3...
heart_disease.data.targets
Se formos lá no UCI e clicarmos nos valores adicionais, descrições adicionais das variáveis, vamos ver que o num, que é o tal do número de alvo, que é o 58 aqui, a variável que está sendo predita, o atributo. 58 pode ser 0, como pode ser 1 ou mais. 1 ou mais quer dizer que tem doença, 0 não tem. Queremos uma classificação binária, 0 não tem, 1 tem, queríamos prever isso, seria o diagnóstico.
Então, queremos se esse atributo é maior do que 0, em alguns sim, em outros não. Então, deu falsos e verdadeiros.
heart_disease.data.targets > 0
| num | |
|---|---|
| 0 | False |
| 1 | True |
| 2 | True |
| 3 | False |
| 4 | False |
| ... | ... |
Mas não queremos falsos e verdadeiros, queremos 0s e 1s. E aí tem um truque, se multiplicarmos 1 vezes 0s e 1s, falsos e verdadeiros, vai dar 0s e 1s. 0 no false e 1 no true, por quê? Porque o true vale 1 e o false vale 0 nessa multiplicação. Então, agora sim temos essa coluna com o alvo.
1 * (heart_disease.data.targets > 0)
| num | |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 1 |
| 3 | 0 |
| 4 | 0 |
| ... | ... |
Então, podemos dizer que no nosso conjunto de dados, dados, no nosso dataframe, queremos criar uma coluna chamada doenca, e a nossa coluna doenca vai ser isso aí. Podemos até dar de novo um dados.head para conferir, vamos ver que tem 0, 1, 1, 0, 0, que era o que queríamos.
dados["doenca"] = 1 * (heart_disease.data.targets > 0)
dados.head()
Agora, vamos fazer um outro gráfico, como citamos, com o Seaborn, uma outra biblioteca de gráficos:
import seaborn as sns
No Seaborn, vamos querer mostrar agora a idade de novo, queremos mostrar a faixa etária. Se tiver doença e se não tiver doença, duas distribuições.
Para analisar a distribuição das idades, podemos fazer um histograma. Mas o que queremos fazer agora é comparar a distribuição de quem tem doença com quem não tem doença, e ver esses gráficos lado a lado. Pode ser um histograma lado a lado, pode ser um histograma em cima do outro, pode ser os dois histogramas no mesmo gráfico, cada um tem suas vantagens na visualização. Mas aqui vamos para um outro lado, vamos para o boxplot, que é uma outra ferramenta para comparar distribuições visualmente. Vamos lá?
Então, no Seaborn, que é o sns, vamos pedir um boxplot. No boxplot, vamos dizer que queremos monstrar no eixo Y, para cima e para baixo, a idade, o age. E vamos dizer que o data, que são os dados, o dataframe, é o dados.
import seaborn as sns
sns.boxplot(y="age", data=dados)
Rodamos, ele vai mostrar um boxplot para nós. Mas falamos que queríamos um histograma, um histograma não, um boxplot, dois boxplots, um para cada, se tem doença ou se não tem. Sim, vamos gerar no eixo X, vamos gerar de acordo com a coluna doenca, porque se a doenca for zero, vai gerar um, se a doenca for um, vai gerar outro, lembrando que doenca é doença, é o diagnóstico. Então, vamos ver, separou, diagnóstico zero, diagnóstico um.
import seaborn as sns
sns.boxplot(y="age", x="doenca", data=dados)
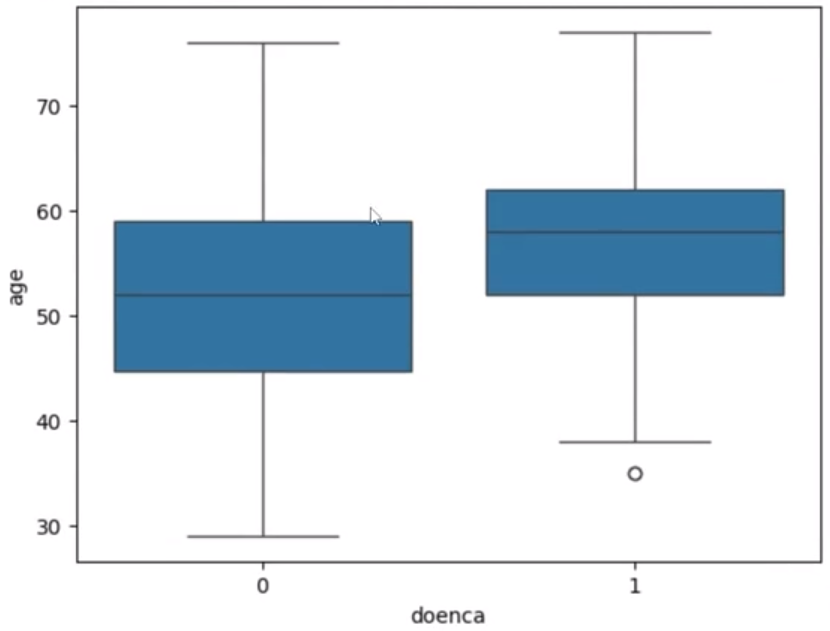
Claro, não está lindo, maravilhoso, dá para ver que a mediana é bem diferente, mais próximo de 60 para quem tem o diagnóstico, mais próximo de 50 para quem não tem.
Então, diversas coisas que dá para ver por aí. O que podemos fazer aqui? Podemos colorir de acordo com a doença, então vamos colocar hue, que é o tom, de acordo com a coluna doenca, que é a doença.
Agora ficou mais bonitinho, claro, vamos melhorar, plt.title para colocarmos o título, então percebe, o matplotlib está sendo utilizado pelo Seaborn, porque agora estamos usando o matplotlib para alterar o gráfico.
Então, "Idade por Diagnóstico". O que mais? Vamos dizer que o label do eixo x, qual é o label do eixo x? Se tem diagnóstico, que é zero, é não, e 1 é sim. O que mais? plt.ylabel, no eixo y, vamos colocar idade, e aí mostramos esse gráfico com show.
import seaborn as sns
sns.boxplot(y="age",x="doenca", data=dados, hue="doenca")
plt.title("Idade por diagnóstico")
plt.xlabel("Diagnóstico (0 = não, 1 = sim)")
plt.ylabel("Idade")
plt.show()
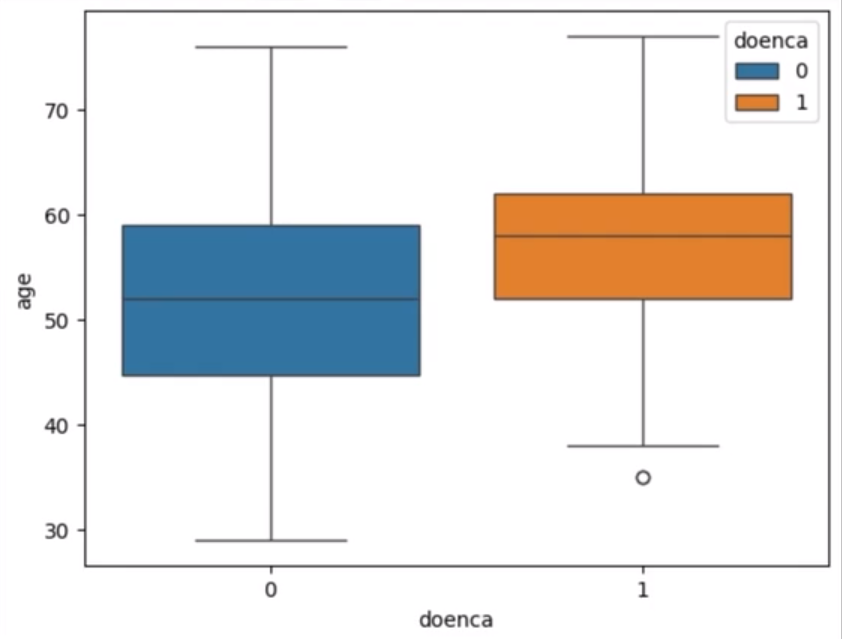
Lembrando que nosso foco aqui é entender como utilizamos essas bibliotecas de gráficos de Python, matplotlib, Seaborn, que são fundamentais no dia a dia, para podermos utilizar a Plotly e jogar tudo isso para a web, que são os nossos próximos passos. Beleza? Até lá!
Continuando, mencionamos que utilizaríamos o Plotly para criar este gráfico.
Como vamos utilizar o Plotly no Google Colab? Vamos importar o Plotly. Ele já está instalado para nós, assim como o Matplotlib e o Seaborn já estavam instalados. Vamos importar. Import Plotly.express as px. E aí, o px, que é o Plotly Express, o Plotly mais rápido. Porque a versão original era muito lenta, não é? Agora o código ficou mais rápido.
Vamos chamar o método histogram. E no histograma, vamos passar nossos dados e dizer que queremos fazer o histograma no eixo x em qual campo mesmo?
Lembra que usamos idade no nosso primeiro histograma? Então, é isso, idade.
import plotly.express as px
px.histogram(dados, x="age")
Podemos executar. E temos o gráfico com as informações de idade. Poderíamos adicionar um título, como title = "Distribuição da idade", por exemplo.
import plotly.express as px
px.histogram(dados, x="age",title="Distribuição etária")
Aí você pode pensar que é legal, mas que tem que memorizar tudo isso?
Não, na prática, o que fazemos? Acessamos a documentação. Vemos os exemplos de histogramas que eles fornecem, vemos o código. Então, o código começa muito parecido, aí vai dando variações, então ele vai fornecendo diversas, uma quantidade enorme de variações de histogramas. Para você poder comparar duas distribuições. Um monte de variação e outros gráficos para tentarmos trabalhar isso.
Primeiro, não queremos que você decore, certo? Nós, por exemplo, não decoramos essas coisas, esquecemos rapidamente. Procure muito em documentação.
Hoje em dia, também temos a utilização das ferramentas de inteligência artificial e vamos utilizar no curso, de vez em quando.
Como o Google Colab, vamos usar nesse instante, depois vamos passar para a web, queríamos mostrar para vocês no Google Colab como é que funciona hoje.
Vamos apagar essa célula anterior. Então, imagine que não temos Plotly nesse projeto ainda.
Estamos com a ferramenta Colab AI ativada no canto superior direito, Colab AI, certo? Está ativada aqui. Então, podemos conversar com ela no canto direito.
Podemos vir aqui na nossa célula, clicar em "Gere código com IA" e aí podemos dizer para ela o que queremos fazer.
Queremos um histograma com Plotly, histograma da idade, com Plotly.
histograma da idade com Plotly
É isso que queremos que ela faça. "Ctrl + Enter" e ela vai gerar o código para nós:
# prompt: histograma da idade com plotly
import plotly.express as px
# Crie um histograma da idade usando Plotly Express
fig = px.histogram(dados, x="age", nbins=30)
# Atualize o layout do gráfico
fig.update_layout(
title="Distribuição etária",
xaxis_title="Idade",
yaxis_title="Frequência",
)
# Exiba o gráfico
fig.show()
Import plotly express as px igualzinho a antes. Fig = histogram, dados = age, ela colocou um número de bins igual a 30, por que ela pegou 30? Porque ela olhou lá em cima o nosso código e viu que tínhamos usado 30 antes, então ela quis manter o padrão.
Colocou o mesmo título, "Distribuição etária", colocou idade, colocou frequência e mostrou o gráfico para nós.
Vamos rodar e temos o nosso resultado, muito parecido com o que tínhamos naquele nosso primeiro gráfico. Mudou o tamanho, não colocou borda, algumas diferenças no fundo, etc, mas ela executou o código que queríamos.
Então, o Colab AI, para preencher e gerar 10 linhas de um gráfico e depois trabalhar em cima desse código, é ótimo.
Outra coisa importante: ela armazena qual foi o prompt que gerou esse código. Assim temos lá se precisamos alterar, fazer alguma outra coisa.
Então, sugerimos no dia a dia a utilização do Plotly e o Colab AI para gerar células. À medida que precisamos gerar algumas linhas, ajuda bastante.
Se não ajudou, você apaga e faz sozinho, não tem problema, vai funcionar da forma que conhecemos! Mas pode ajudar a gerar algumas coisas sem precisarmos decorar códigos.
O próximo passo é levarmos isso para a web. Para levarmos isso para a web, não vamos conseguir mais ficar rodando aqui no nosso Google Colab. Precisamos passar a rodar ele num Visual Studio para rodar o nosso servidor com Flask.
Usaremos o Visual Studio a partir da próxima aula. Até lá!
O curso Dash: construindo dashboards para modelos de Machine Learning possui 160 minutos de vídeos, em um total de 55 atividades. Gostou? Conheça nossos outros cursos de Machine Learning em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






