Olá, boas-vindas a este curso de AWS Data Lake: Processamento de Dados com AWS Glue, ministrado pela instrutora Ana Hashimoto.
Audiodescrição: Ana é uma mulher de pele clara, de cabelos e olhos pretos, ela usa batom vermelho e uma blusa preta sem manga. Ao fundo, temos parte de um armário liso à esquerda da instrutora e uma porta escura e uma parede branca à sua direita. Todo o fundo está iluminado por uma luz esverdeada.
Neste curso, faremos o processamento dos dados utilizando o AWS Glue e os seus recursos, como o Glue Crawler, o Glue Catalog, o Glue Studio, no qual utilizaremos o recurso de visual ETL (Extract, Transform, Load). Aprenderemos também sobre o Glue Data Quality e o Glue Databrew.
Para isso, vamos utilizar a base de dados do site Data Boston, que já fizemos a ingestão no curso anterior e hoje está na camada bronze do nosso bucket S3 na AWS.
Faremos o processamento destes dados utilizando o AWS Glue e os seus recursos, no qual faremos a criação da camada silver com os dados tratados e harmonizados no nosso bucket S3 na AWS.
Faremos também a criação de um filtro no nosso Data Lake, no qual aplicaremos a regra de mínimo privilégio, para que as pessoas usuárias tenham acesso somente às informações que, de fato, elas irão utilizar.
Por fim, iremos utilizar também o AWS Athena para consultas ad-hoc e também verificação da gravação das informações nas tabelas criadas.
Com este curso, você conseguirá fazer a criação de um ETL e da camada silver utilizando o AWS Glue.
Para um melhor aproveitamento do curso, recomendamos que você tenha conhecimento em Python e também em Cloud Computing.
E aí, vamos começar a nossa jornada?
No curso anterior, realizamos a ingestão de dados externos do site Data Boston, contendo 6 anos de informações, diretamente na camada bronze dentro da AWS.
Agora, nosso desafio é processar essas informações utilizando o AWS Glue, que realizará todo o ETL dessas informações e também a criação da camada silver dentro da AWS.
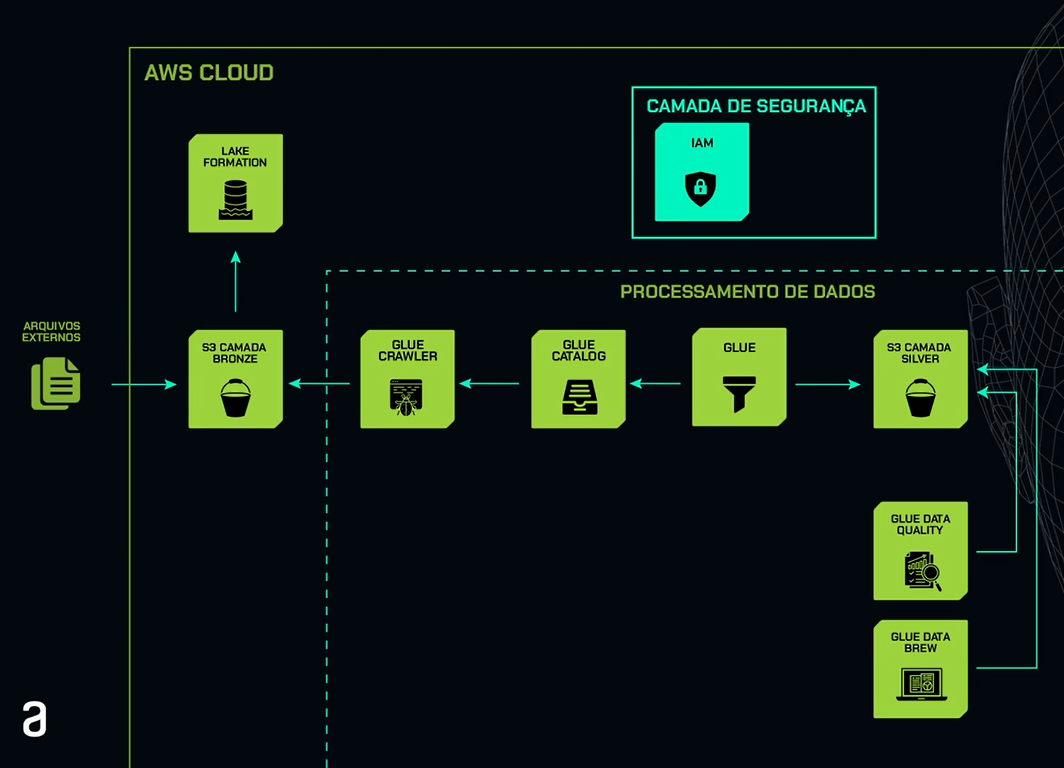
Para entender melhor a arquitetura, temos aqui, à esquerda, o símbolo dos arquivos externos, que representam as informações do site Data Boston. Em seguida, temos o ícone do S3, representando a camada bronze que criamos no curso anterior.
Acima dela, temos o ícone do Lake Formation, com o qual criamos o Data Lake dentro da AWS. Na parte superior à direita, temos o ícone do IAM, onde criamos nosso usuário IAM, para que não utilizemos o usuário raiz. Essa camada representa a camada de segurança dentro da AWS.
Descendo um pouco, temos nosso quadrado pontilhado, que será a arquitetura deste curso. Primeiramente, temos o ícone do Glue Crawler, que realizará toda a extração das informações que estão no S3 e também a criação automática da tabela dentro do Glue Catalog.
O Glue Catalog representa a camada de armazenamento das informações das tabelas e também dos metadados. Em seguida, temos o ícone do Glue, que realizará a criação do ETL e processamento dessas informações.
Posteriormente, temos o ícone do S3, representando a camada silver, que será uma camada harmonizada desses dados. Abaixo dele, temos o ícone do Glue Data Quality, que realizará a qualidade dessas informações. Por fim, temos o Glue Data Brew, que realizará todos esses serviços de processamento e criação de camada silver de uma forma bem mais fácil e visual.
No próximo vídeo, vamos aprofundar essa arquitetura com detalhes dos serviços. Vamos lá?
Agora que já compreendemos como será nossa pipeline para processamento dos dados, vamos fazer a ingestão das informações do site Data Boston diretamente no nosso bucket S3, utilizando o código que criamos no curso anterior.
Recomendamos que você faça o curso anterior para um melhor entendimento da pipeline e também disponibilizaremos todo esse código para download.
Nesse código, estamos extraindo as informações diretamente do site Data Boston por meio da URL informada, depois estabelecemos a conexão com o nosso bucket S3 e, por fim, convertemos todos esses arquivos para o formato parquet e salvamos diretamente na nossa camada bronze no bucket S3.
Agora, vamos entrar no Google Colab e analisar o nosso código. Vamos iniciar a parte de extração dos dados. No primeiro item, vamos criar um novo diretório chamado data. Para isso, vamos utilizar o comando mkdir e chamaremos esse diretório de data, que será o local onde serão armazenadas as novas informações.
#Cria um novo diretório
!mkdir -p data
Vamos executar essa célula e, na célula seguinte, vamos criar a nossa função, que fará a extração das informações da URL e armazenará no local informado. Para isso, como primeiro item, vamos fazer o import da urllib.request, que é o módulo utilizado para fazer download de dados de uma URL informada.
Na linha seguinte, vamos criar a nossa função que fará o download dos dados e salvará no arquivo informado. Vamos chamar essa função de extract_data. Vamos passar os parâmetros url e filename e ela vai esperar dois argumentos. Basicamente, temos que passar o caminho da URL, que será o local que buscará as informações do site Data Boston, e filename, que será o nome dos arquivos que vamos passar para ela.
Depois, temos a parte de try e except para lidarmos com as exceções dentro do Python. Na parte do try, vamos passar os argumentos para ela e, no except, ela vai imprimir caso tenha qualquer erro.
Na parte do try, estamos utilizando a função urlretrieve dentro do módulo urllib.request e estamos passando para ela os dois argumentos, a nossa url e filename. Nesse ponto, ela está baixando o arquivo da URL e salvando no local especificado. Por fim, na parte de Exception, ela vai imprimir qualquer erro que ocorra durante o processo.
Nessa célula, estamos criando a nossa função extract_data, que, nas linhas abaixo, vamos passar para ela quais são os argumentos. Vamos executar essa célula.
import urllib.request
#Módulo utilizado para fazer o download de dados de uma url
# Função para baixar dados de um URL e salvar em um arquivo
def extract_data(url, filename): #Parâmetros da função que espera 2 argumentos
try:
urllib.request.urlretrieve(url, filename)
# Baixa o arquivo do URL e salva no local especificado
except Exception as e:
print(e) # Imprime qualquer erro que ocorra durante o processo
Na próxima célula, temos agora a parte de execução dessa função, que vamos, de fato, passar as informações para ela. Aqui, estamos chamando a função extract_data para baixarmos os 6 anos de informação do site Data Boston e, também, vamos passar o filename, que será o local por onde ela vai salvar essas informações. Cada conjunto de dados é salvo em um arquivo CSV diferente.
No primeiro argumento, estamos passando os 6 anos de informações do site Data Boston, de 2015 a 2020, e o segundo argumento que estamos passando para ela será o local e o nome do arquivo que ela vai passar. Primeiro, ela vai salvar no diretório data, que foi o primeiro item que criamos nesse código, e ela vai salvar o nome como dados_ano ao qual ela se refere.
Basicamente, nessa célula, estamos utilizando a função extract_data que criamos na célula acima, e estamos passando os dois argumentos, tanto a URL quanto o filename. Vamos executar essa célula.
# Chamando a função extract_data para baixar diferentes conjuntos de dados
# Cada conjunto de dados é salvo em um arquivo CSV diferente
extract_data("https://data.boston.gov/dataset/8846b97b-a46d-4bfc-b9a9-ee00169f2323/resource/05e9bab4-6fc4-4b97-979a-0cf4a1c02c9b/download/311_service_requests_2015.csv", "data/dados_2015.csv")
extract_data("https://data.boston.gov/dataset/8846b97b-a46d-4bfc-b9a9-ee00169f2323/resource/b7eacb1a-3ca4-4cb5-9713-cd1dcb5d297a/download/311_service_requests_2016.csv", "data/dados_2016.csv")
extract_data("https://data.boston.gov/dataset/8846b97b-a46d-4bfc-b9a9-ee00169f2323/resource/30021317-709d-465e-baa6-ca155b5197ed/download/311_service_requests_2017.csv", "data/dados_2017.csv")
extract_data("https://data.boston.gov/dataset/8846b97b-a46d-4bfc-b9a9-ee00169f2323/resource/2be349b0-349a-4c1f-a3f6-f2c18e58288a/download/311_service_requests_2018.csv", "data/dados_2018.csv")
extract_data("https://data.boston.gov/dataset/8846b97b-a46d-4bfc-b9a9-ee00169f2323/resource/e2e4a696-4a24-429c-9870-dbe92ebe6222/download/311_service_requests_2019.csv", "data/dados_2019.csv")
extract_data("https://data.boston.gov/dataset/8846b97b-a46d-4bfc-b9a9-ee00169f2323/resource/6ff6afd6-3141-44aa-8880-66aa3f7e78b9/download/script_105774672_20210108153400_combine.csv", "data/combine.csv")
Na próxima célula, vamos criar uma lista somente com os nomes dos arquivos baixados. Aqui, vamos passar o diretório, que chama data, e o nome do arquivo. Tudo isso, vamos salvar na lista chamada arquivos.
# Lista dos nomes dos arquivos baixados
arquivos = [
"data/dado_2015.csv",
"data/dado_2016.csv",
"data/dado_2017.csv",
"data/dado_2018.csv",
"data/dado_2019.csv",
"data/dado_2020.csv",
]
Na célula seguinte, vamos criar um dicionário para armazenar os dados de cada arquivo. Nesse caso, vamos salvar as informações dentro desse dicionário chamado dfs. Vamos executar também essa célula.
# Dicionário para armazenar os dados de cada arquivo
dfs = {}
Na próxima célula, vamos criar um looping para ler cada arquivo e salvar o nosso dicionário. Também, vamos fazer a extração somente do ano de cada arquivo. Para isso, primeiro, vamos importar a biblioteca chamada pandas e chamá-la de pd. Depois, temos um for, que vai ler todos os itens dessa lista que criamos chamada arquivos.
Ele vai fazer a leitura de todos os itens e vai salvar em ano. Em ano, vamos extrair o ano do nome do arquivo. Vamos utilizar aqui o split, no qual vamos começar a leitura no underline e vamos terminar no ponto.
Basicamente, o que ele vai fazer é vai pegar, por exemplo, dados_2015.csv. Ele vai começar a leitura depois do underline e vai ler até o ponto. Ou seja, nesse caso, ele vai extrair 2015 para que consigamos extrair somente o ano do nome do arquivo.
Feito isso, vamos usar o pandas para ele fazer a leitura de cada arquivo e salvar no dicionário que criamos acima. Aqui ele vai ler os dados dos arquivos, transformar em dataframe e armazenar no dicionário que criamos anteriormente. Para isso, cada dataframe vai ter o ano do seu respectivo arquivo.
import pandas as pd
# Loop para ler cada arquivo e adicionar ao dicionário
for arquivo in arquivos:
ano = arquivo.split("_")[-1].split(".")[0] # Extrai o ano do nome do arquivo
df[ano] = pd.read_csv(arquivo)
# Lê os dados do arquivo transforma em DataFrame e armazena no dicionário
Na célula seguinte, vamos passar um exemplo de como podemos acessar as informações de um ano específico. No passo anterior, criamos o dfs e o seu respectivo ano. Agora vamos pegar, por exemplo, 2018 e vamos colocar um head. Ou seja, vamos imprimir somente as primeiras linhas desse dataframe.
# Exemplo de como acessar os dados de um ano específico
dfs["2018"].head()
Aqui ele já trouxe para nós todas as informações de 2018 e conseguimos ver que elas foram carregadas com sucesso, porque a data de abertura e a data de fechamento é 2018. Assim, conseguimos, com sucesso, extrair as informações do site Data Boston. Conseguimos também extrair o ano do nome do arquivo e salvar localmente no nosso diretório chamado data.
| case_enquiry_id | open_dt | target_dt | closed_dt | ontime | case_status | closure_reason |
|---|---|---|---|---|---|---|
| 101002296861 | 2018-01-01 00:08:00 | NaN | 2018-03-01 15:18:12 | ONTIME | Closed | Case Closed. Closed date: 2018-03-01 15:18:12... |
| 101002296862 | 2018-01-01 00:09:46 | 2018-01-02 08:30:00 | 2018-01-02 21:15:22 | OVERDUE | Closed | Case Closed. Closed date: 2018-01-02 21:15:22... |
Na próxima célula, vamos começar um tópico bastante importante, que é a parte de conexão com a nossa conta de armazenamento. Vamos estabelecer a conexão entre o nosso diretório local e o nosso Bucket S3 na AWS.
Para isso, como primeiro item, vamos instalar a biblioteca boto3. Ela é bem conhecida para a parte de automatização de tarefas dentro da AWS. Conseguimos estabelecer conexão entre o diretório local e a AWS e automatizar tarefas. Nesse caso, vamos utilizar o boto3 para que consigamos, de fato, estabelecer a conexão com a nossa camada bronze no Bucket S3 e consigamos também gravar os arquivos.
pip install boto3
Na célula seguinte, vamos fazer o import do boto3 e vamos passar as credenciais de conexão. Aqui temos que passar três itens para ela, o Access Key, o Secret Access Key e também o nome da região em que o nosso Bucket foi criado. A parte de criação de Bucket S3 fizemos no curso anterior.
Nessa etapa, é importante que você substitua todas essas informações para os dados da sua conta.
Vamos começar a utilizar o boto3 e vamos estabelecer uma seção padrão, passando os parâmetros. Toda a seção que estabelecermos com o S3, vamos passar todos os itens informados acima.
Aqui vamos passar o Access Key, o Secret Access Key e a região, o nome da região em que esse Bucket foi criado. Aqui estamos estabelecendo uma conexão padrão, utilizando o boto3. E, por fim, estamos fazendo a criação de um Cliente S3, também utilizando um recurso do S3. Estamos criando um Client chamado S3.
import boto3
# IMPORTANTE: Essas credenciais não podem aparecer no seu código, coloque em variáveis de ambiente
# exemplo: aws_access_key_id = os.environ['AWS_ACCESS_KEY_ID']
# TODO: Substituir 'aws_access_key_id' e 'aws_secret_access_key' pelas informações da sua conta
aws_access_key_id = "AKIA234GKISQZO7AFVM"
aws_secret_access_key = "eGkFMD6ydl3C9enf0fzGc+w3XAOQYbDBLtAzeOQH"
region_name = "us-east-1"
boto3.setup_default_session(
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
region_name=region_name,
)
# Criação de um cliente S3
s3 = boto3.client("s3")
Na próxima célula, vamos criar um arquivo teste para verificarmos se essa conexão com o S3 foi feita com sucesso. Para isso, vamos criar um arquivo teste. Primeiro vamos colocar o conteúdo desse arquivo, Olá, S3!. Depois, vamos criar um arquivo chamado hello-s3.txt. Esse W é de Write. Dentro desse arquivo, vamos escrever as informações e vamos passar as informações de content.
Esse arquivo teste será bem simples. Ele vai se chamar hello.s3, vai estar no formato .txt e o conteúdo dele será somente hola.s3.
content = """
Olá, S3!
"""
with open("hello-s3.txt", "w+") as f:
f.write(content)
Na próxima célula, vamos agora salvar o nosso bucket S3 na AWS. Para isso, vamos utilizar um recurso do S3, que foi o client que criamos nos passos anteriores, e temos que passar três parâmetros para ele.
Temos que passar o nome do arquivo. Nesse caso, hello-s3.txt, que criamos na célula acima. Qual é o nome do nosso bucket S3? Nesse caso, o meu chama alura-datalakeaws. E aqui vou salvar na nossa camada bronze esse arquivo hello-s3.
Nessa célula, é necessário que você substitua essas informações para as informações da sua conta. Tanto o nome do seu bucket S3 quanto a camada que você deseja salvar esse arquivo teste.
s3.upload_file("hello-s3.txt", "alura-datalakeaws", "bronze/hello-s3")
Agora, vamos entrar no console AWS, que vamos verificar se o arquivo foi salvo com sucesso. Para isso, vamos entrar no console AWS. Na barra de pesquisa, vamos digitar S3.
No menu lateral à esquerda, vamos clicar em Buckets. E aqui ele vai aparecer todos os buckets que hoje estão na sua conta. Vamos clicar no primeiro, então alura-datalakeaws. Vamos entrar na camada bronze/, que foi o que informamos.
E agora vamos verificar se o arquivo foi salvo. Sim, o arquivo hello-s3 foi salvo com sucesso. Na última modificação, ele mostra a data e hora dessa alteração. Podemos clicar no arquivo também. E aqui vão aparecer todas as informações, como o tamanho, o owner, a região, entre outras informações.
Com isso, verificamos que conseguimos estabelecer a conexão entre o nosso diretório local e o nosso bucket S3 na camada bronze na AWS. No próximo vídeo, vamos ver como converter esses arquivos em parquet e salvar também na AWS. Até logo!
O curso AWS Data Lake: processando dados com AWS Glue possui 155 minutos de vídeos, em um total de 39 atividades. Gostou? Conheça nossos outros cursos de Engenharia de Dados em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
O Plano Plus evoluiu: agora com Luri para impulsionar sua carreira com os melhores cursos e acesso à maior comunidade tech.
2 anos de Alura
Matricule-se no plano PLUS 24 e garanta:
Jornada de estudos progressiva que te guia desde os fundamentos até a atuação prática. Você acompanha sua evolução, entende os próximos passos e se aprofunda nos conteúdos com quem é referência no mercado.
Programação, Data Science, Front-end, DevOps, Mobile, Inovação & Gestão, UX & Design, Inteligência Artificial
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
Acesso à inteligência artificial da Alura.
No Discord, você participa de eventos exclusivos, pode tirar dúvidas em estudos colaborativos e ainda conta com mentorias em grupo com especialistas de diversas áreas.
Catálogo de tecnologia para quem é da área de Marketing
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Luri Vision chegou no Plano Pro: a IA da Alura que enxerga suas dúvidas, acelera seu aprendizado e conta também com o Alura Língua que prepara você para competir no mercado internacional.
2 anos de Alura
Todos os benefícios do PLUS 24 e mais vantagens exclusivas:
Acesso ao catálogo da Casa do Código e leitura dentro da plataforma
Chat, busca, exercícios abertos, revisão de aula, geração de legenda para certificado.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Para quem quer atingir seus objetivos mais rápido: Luri Vision ilimitado, vagas de emprego exclusivas e mentorias para acelerar cada etapa da jornada.
2 anos de Alura
Todos os benefícios do PRO 24 e mais vantagens exclusivas:
Catálogo de tecnologia para quem é da área de Marketing
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais de forma ilimitada.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.
Conecte-se ao mercado com mentoria individual personalizada, vagas exclusivas e networking estratégico que impulsionam sua carreira tech para o próximo nível.






